
When does your app enforce its data structure? If you’re using a relational database, you comply with a pre-defined data structure when you write data to its tables. The schema—made up of field names, data types, and foreign key constraints, for example—is enforced up front. Your app won’t successfully write data if it violates the schema. Many of us have been working with schema-on-write relational databases for a long time, and they make sense when you have relatively static data structures.
If you’d prefer to be more flexible with what data you store, and want data consumers to be responsible for enforcing structure, you’ll prefer a NoSQL database. Whether you’ve got a document-style database like Firestore or MongoDB, or key-value stores like Redis, you’re mostly leaving it up the client to retrieve the data and deserialize it into a structure it expects. These clients apply a schema when they read the data.
Both of these approaches are fine. It’s all about what you need for a given scenario. While this has been a choice for database folks for a while, today’s message queue services often apply a schema-on-read approach. Publish whatever, and subscribers retrieve the data and deserialize it into the object they expects. To be sure, there are some queues with concepts of message structure—ActiveMQ has something, and traditional ESB products like TIBCO EMS and BizTalk Server offer schemas—but modern cloud-based queue services are typically data-structure-neutral.
Amazon SQS is one of the oldest cloud services. It doesn’t look at any of the messages that pass through, and there’s no concept of a message schema. Same goes for Azure Service Bus, another robust queuing service that asks the consumer to apply a schema when a message is read. To be clear, there’s nothing is wrong with that. It’s a good pattern. Heck, it’s one that Google Cloud applies too with Pub/Sub. However, we’ve recently added schema support, and I figured we should take a look at this unique feature.
I wrote about Pub/Sub last year. It’s a fairly distinct cloud service. You can do traditional message queuing, of course. But it also supports things like message replay—which feels Kafka-esque—and push notifications. Instead of using 3+ cloud messaging services, maybe just use one?
The schema functionality in Pub/Sub is fairly straightforward. A schema defines a message structure, you apply it to one or many new Topics, and only messages that comply with that schema may be published to those Topics. You can continue using Topics without schemas and accept any input, while attaching schemas to Topics that require upfront validation.
Creating schemas
Schemas work with schemas encoded as JSON or in a binary format. And the schema itself is structured using either Apache Avro or the protocol buffer language. Both support basic primitive types, and complex structures (e.g. nested types, arrays, enumerations).
With Google Cloud Pub/Sub, you can create schemas independently and then attach to Topics, or you can create them at the same time as creating a Topic. Let’s do the former.
You can create schemas programmatically, as you’d expect, but let’s use the Google Cloud Console to do it here. I’M A VISUAL LEARNER.
On the schemas view of the Console, I see options to view, create, and delete schemas.

I chose to create a brand new schema. In this view, I’m asked to give the schema a name, and then choose if I’m using Avro or Protocol Buffers to define the structure.
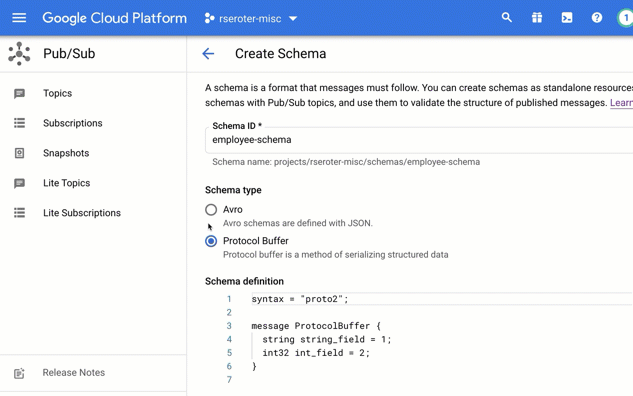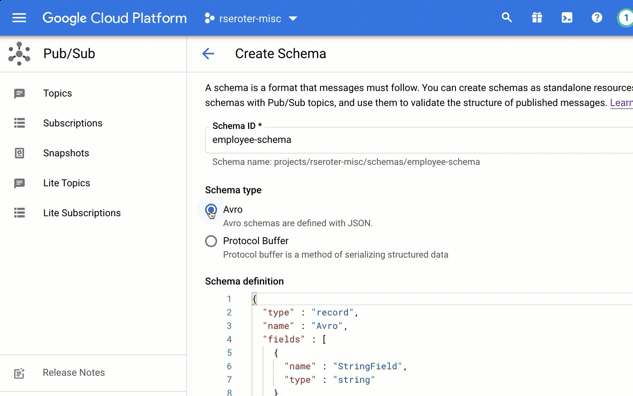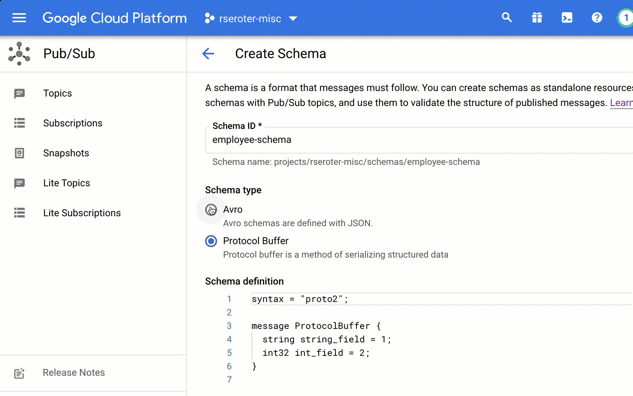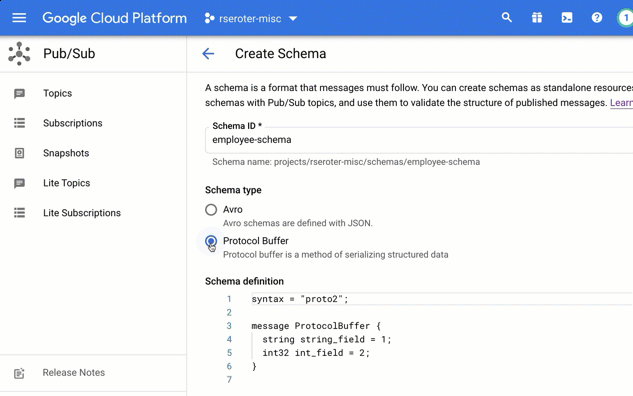
In that “schema definition” box, I get a nice little editor with type-ahead support. Here, I sketched out a basic schema for an “employee” message type.

No matter how basic, I’m still capable of typing things wrong. So, it’s handy that there’s a “validate schema” button at the bottom that shockingly confirmed that I got my structure correct.

You’ll also notice a “test message” button. This is great. From here, I can validate input, and see what happens (below) if I skip a required field, or put the the wrong value into the enumeration.
Also note that the CLi lets you do this too. There are simple commands to test a message against a new schema, or one that already exists. For example:
gcloud pubsub schemas validate-message \
--message-encoding=JSON \
--message="{\"name\":\"Jeff Reed\",\"role\":\"VP\",\"timeinroleyears\":0.5,\"location\":\"SUNNYVALE\"}" \
--schema-name=employee-schema
Once I’m content with the structure, I save the schema. Then it shows up in my list of available schemas. Note that I cannot change a published schema. If my structure changes over time, that’s a new schema. This is a fairly light UX, so I assume you should maintain versions in a source code repo elsewhere.
[March 20, 2023 update: Schemas can now be updated.]
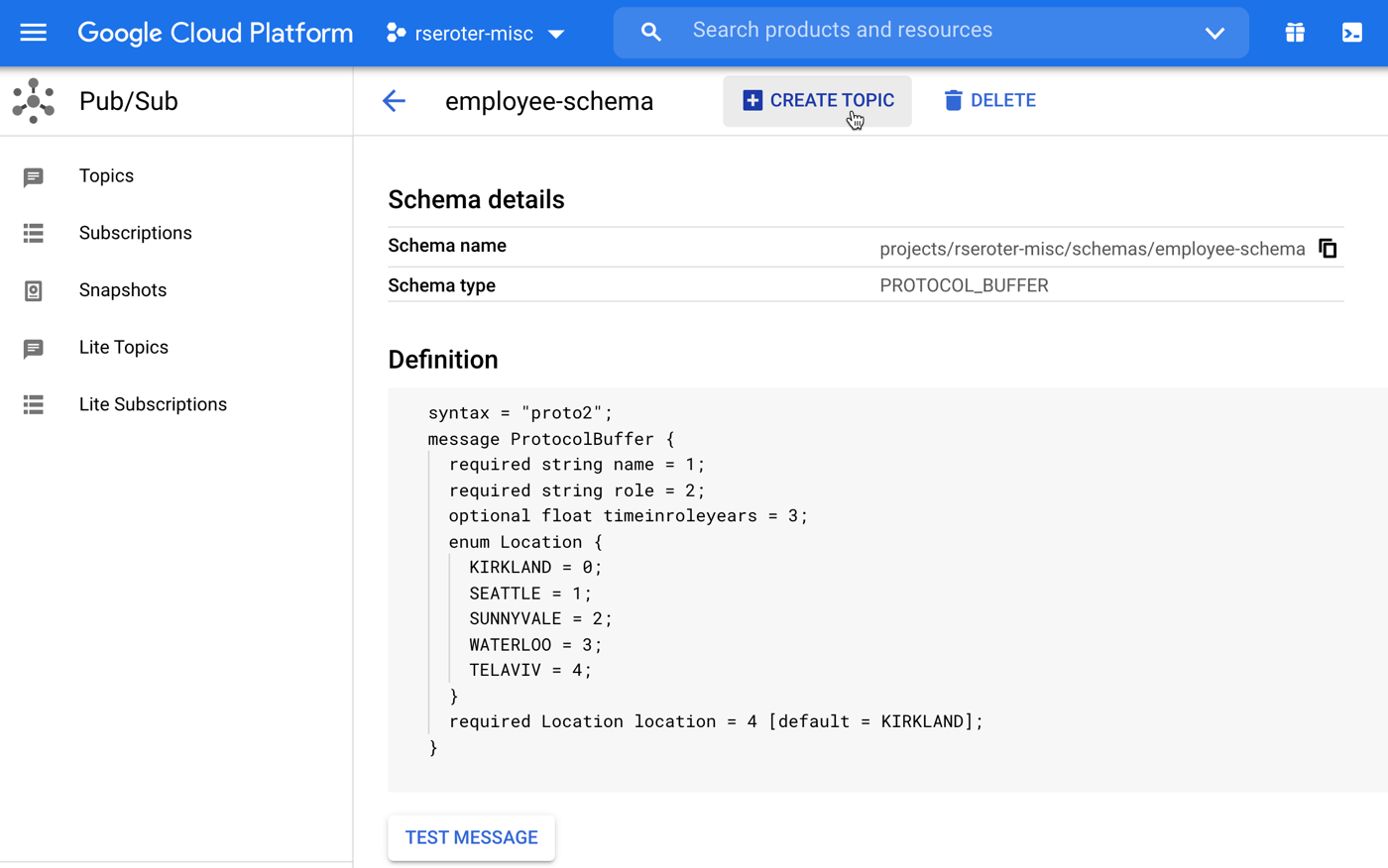
Apply schemas to Topics
In that screenshot above, you see a button that says “create topic.” I can create a Topic from here, or, use the standard way of creating Topics and select a schema then. Let’s do that. When I go to the general “create Topic” view, you see I get a choice to use a schema and pick a message encoding. Be aware that you can ONLY attach schemas to new Topics, and once you attach a schema, you can’t remove it from that Topic. Make good choices.
[March 20, 2023 update: Schemas can now be added and removed from topics.]
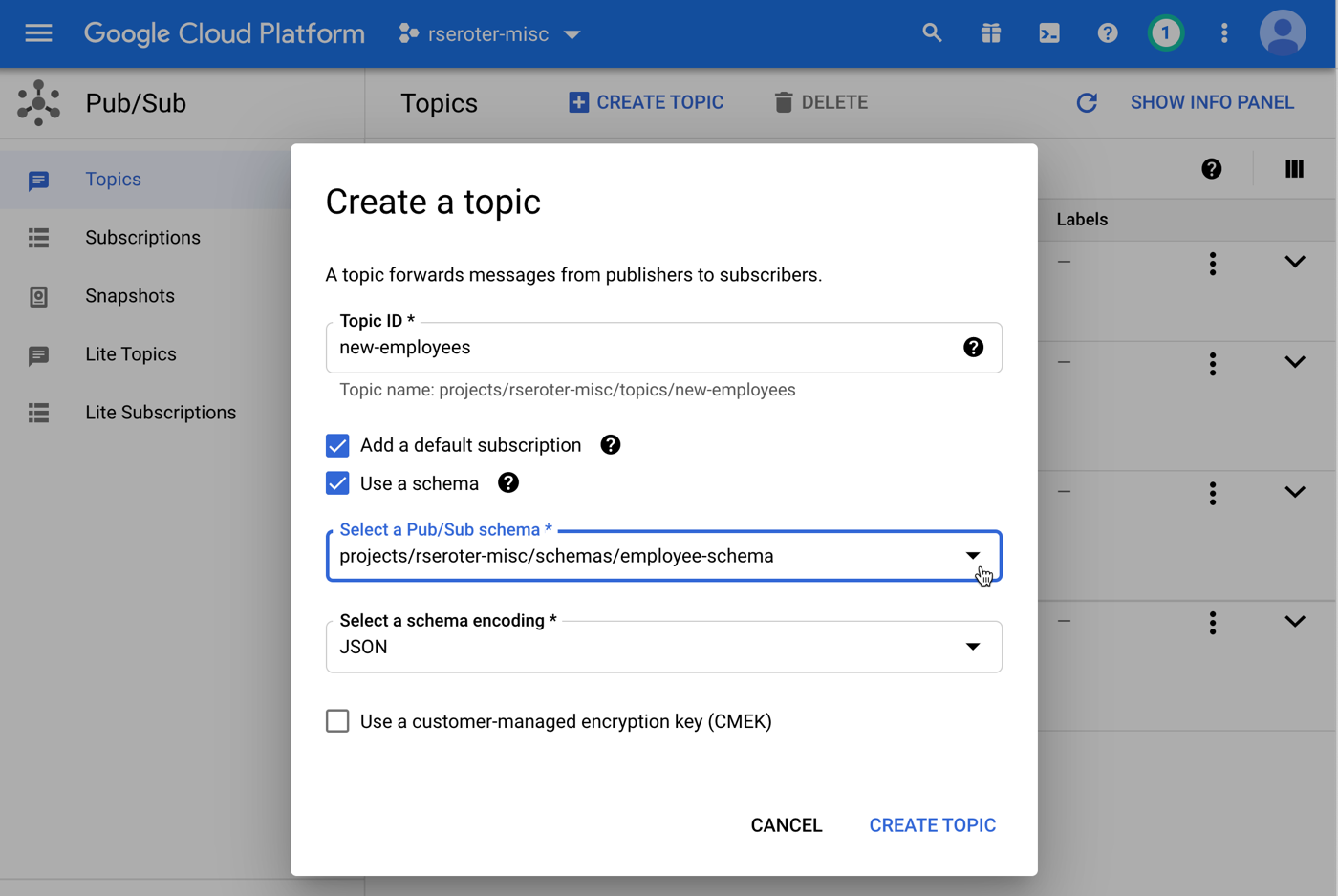
How do I know that a Topic has schema attached? You have a few options.
First, the Google Cloud Console shows you! When I view the details of a given Topic, I notice that the encoding and schema get called out.

It’s not all about the portal UX, however. CLI fans need love too. Everything I did above, you can do in code or via CLi. That includes getting details about a given schema. Notice below that I can list all the schemas for my project, and get the details for any given one.
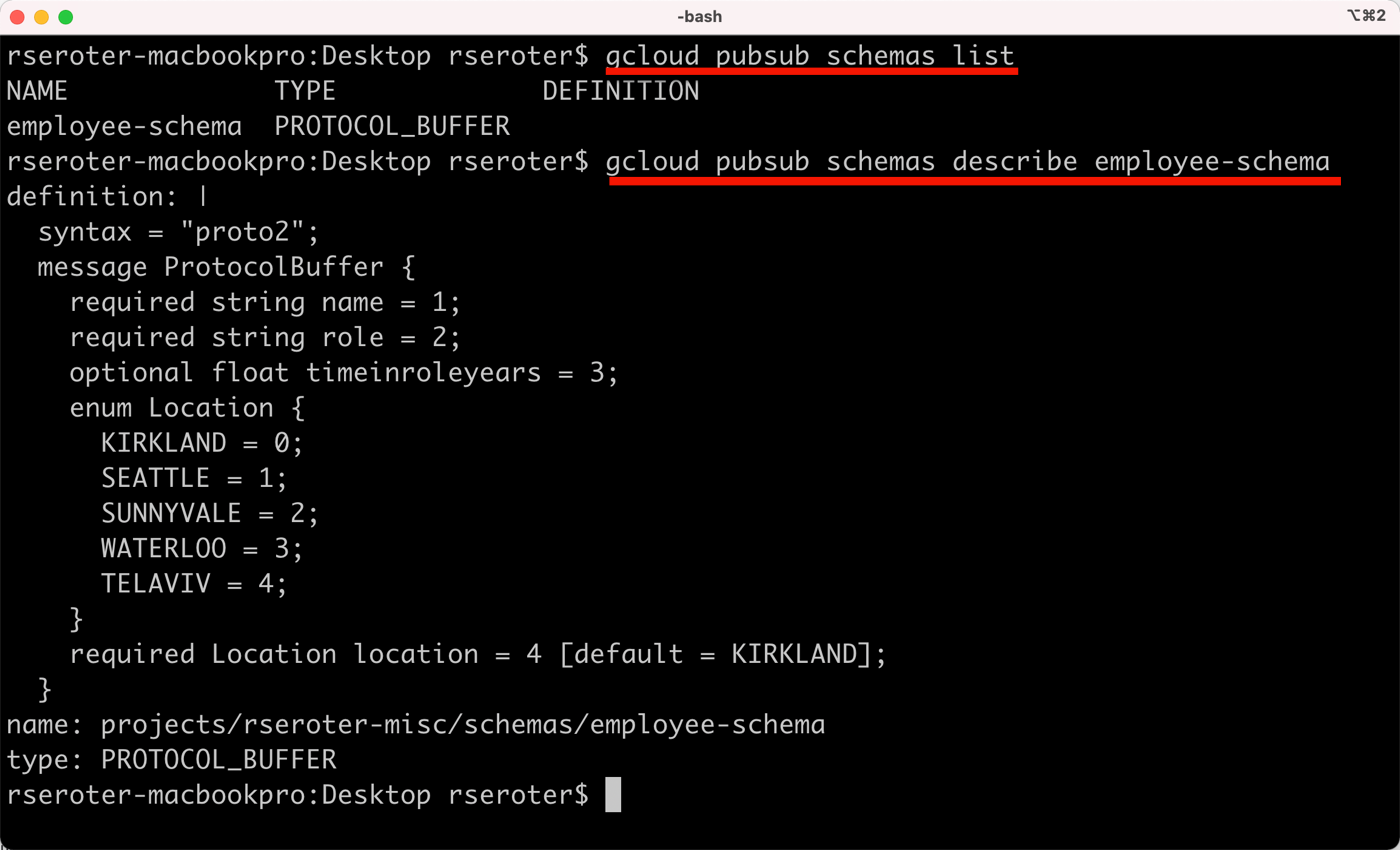
And also see that when I view my Topic, it shows that I have a schema applied.

Publishing messages
After ensuring that my Topic has a subscription or two—messages going to a Topic without a subscription are lost—I tried publishing some messages.
First, I did this from a C# application. It serializes a .NET object into a JSON object and sends it to my schema-enforcing Pub/Sub topic.
using System;
using Google.Cloud.PubSub.V1;
using Google.Protobuf;
using System.Text.Json;
namespace core_pubsub_schema
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Pub/Sub app started");
PublishMessage();
Console.WriteLine("App done!");
}
static void PublishMessage() {
//define an employee object
var employee = new Employee {
name = "Jeff Reed",
role = "VP",
timeinroleyears = 0.5f,
location = "SUNNYVALE"
};
//convert the .NET object to a JSON string
string jsonString = JsonSerializer.Serialize(employee);
//name of our topic
string topicName ="projects/rseroter-misc/topics/new-employees";
PublisherServiceApiClient publisher = PublisherServiceApiClient.Create();
//create the message
PubsubMessage message = new PubsubMessage
{
Data = ByteString.CopyFromUtf8(jsonString)
};
try {
publisher.Publish(topicName, new[] { message });
Console.WriteLine("Message published!");
}
catch (Exception ex) {
Console.WriteLine(ex.ToString());
}
}
}
public class Employee {
public string name {get; set; }
public string role {get; set; }
public float timeinroleyears {get; set;}
public string location {get; set;}
}
}
After running this app, I see that I successfully published a message to the Topic, and my lone subscription holds a copy for me to read.
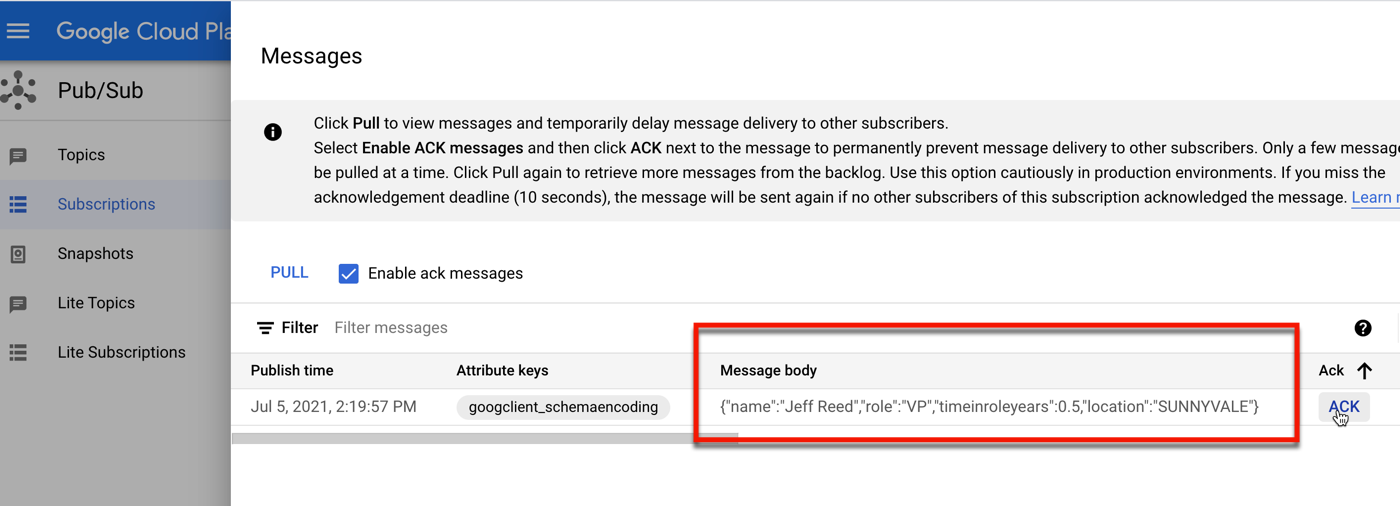
For fun, I can also publish messages directly from the Google Cloud Console. I like that we’ve offered the ability to publish up to a hundred messages on an interval, which is great for testing purposes.
Below, I entered some JSON, and removed a required field (“role”) before publishing. You can see that I got an error before the message hit the Topic.

Dealing with schema changes
My first impression upon using this schema capability in Pub/Sub was that it’s cool, but I wish I could change schemas more easily, and detach schemas from Topics. But the more I thought about it, the more I understood the design decision.
If I’m attaching a schema to a Topic, then I’m serious about the data structure. And downstream consumers are expecting that specific data structure. Changing the schema means creating a new Topic, and establishing new subscribers.
What if your app can absorb schema changes, and you want to access new Subscriptions without redeploying your whole app? You might retrieve the subscription name from an external configuration (e.g. ConfigMap in Kubernetes) versus hard-coding it. Or use a proxy service/function/whatever in between publishers and Topics, or consumers and subscriptions. Changing that proxy might be simpler than changing your primary system. Regardless, once you sign up to use schemas, you’ll want to think through your strategy for handling changes.
[March 20, 2023 update: Schemas can now be updated.]
Wrap up
I like this (optional) functionality in Google Cloud Pub/Sub. You can do the familiar schema-on-read approach, or now do a schema-on-write when needed. If you want to try this yourself, take advantage of our free tier for Pub/Sub (10GB of messages per month) and let me know if you come up with any cool use cases, or schema upgrade strategies!

Leave a comment