
When it comes to building and managing cloud resources—VMs, clusters, user roles, databases—most people seem to use a combination of tools. The recent JetBrains developer ecosystem survey highlighted that Terraform is popular for infrastructure provisioning, and Ansible is popular for keeping infrastructure in a desired state. Both are great tools, full stop. Recently, I’ve seen folks look at the Kubernetes API as a single option for both activities. Kubernetes is purpose-built to take a declared state of a resource, implement that state, and continuously reconcile to ensure the resource stay in that state. While we apply this Kubernetes Resource Model to containers today, it’s conceptually valid for most anything.
18 months ago, Google Cloud shipped a Config Connector that offered custom resource definitions (CRDs) for Google Cloud services, and controllers to provision and manage those services. Install this into a Kubernetes cluster, send resource definitions to that cluster, and watch your services hydrate. Stand up and manage 60-ish Google Cloud services as if they were Kubernetes resources. It’s super cool and useful. But maybe you don’t want 3rd party CRDs and controllers running in a shared cluster, and don’t want to manage a dedicated cluster just to host them. Reasonable. So we created a new managed service: Config Controller. In this post, I’ll look at manually configuring a GKE cluster, and then show you how to use the new Config Controller to provision and configure services via automation. And, if you’re a serverless fan or someone who doesn’t care at ALL about Kubernetes, you’ll see that you can still use this declarative model to build and manage cloud services you depend on.
But first off, let’s look at configuring clusters and extending the Kubernetes API to provision services. To start with, it’s easy to stand up a GKE cluster in Google Cloud. It can be one-click or fifty, depending on what you want. You can use the CLI, API, Google Cloud Console, Terraform modules, and more.

Building and managing one of something isn’t THAT hard. Dealing with fleets of things is harder. That’s why Google Anthos exists. It’s got a subsystem called Anthos Config Management (ACM). In addition to embedding the above-mentioned Config Connector, this system includes an ability to synchronize configurations across clusters (Config Sync), and apply policies to clusters based on Open Policy Agent Gatekeeper (Policy Controller). All these declarative configs and policies are stored in a git repo. We recently made it possible to use ACM as a standalone service for GKE clusters. So you might build up a cluster that looks like this:

What this looks like in real life is that there’s a “Config Management” tab on the GKE view in the Console. When you choose that, you register a cluster with a fleet. A fleet shares a configuration source, so all the registered clusters are identically configured.

Once I registered my GKE cluster, I chose a GitHub repo that held my default configurations and policies.

Finally, I configured Policy Controller on this GKE cluster. This comes with a few dozen Google-provided constraint templates you can use to apply cluster constraints. Or bring your own. My repo above includes a constraint that limits how much CPU and memory a pod can have in a specific namespace.
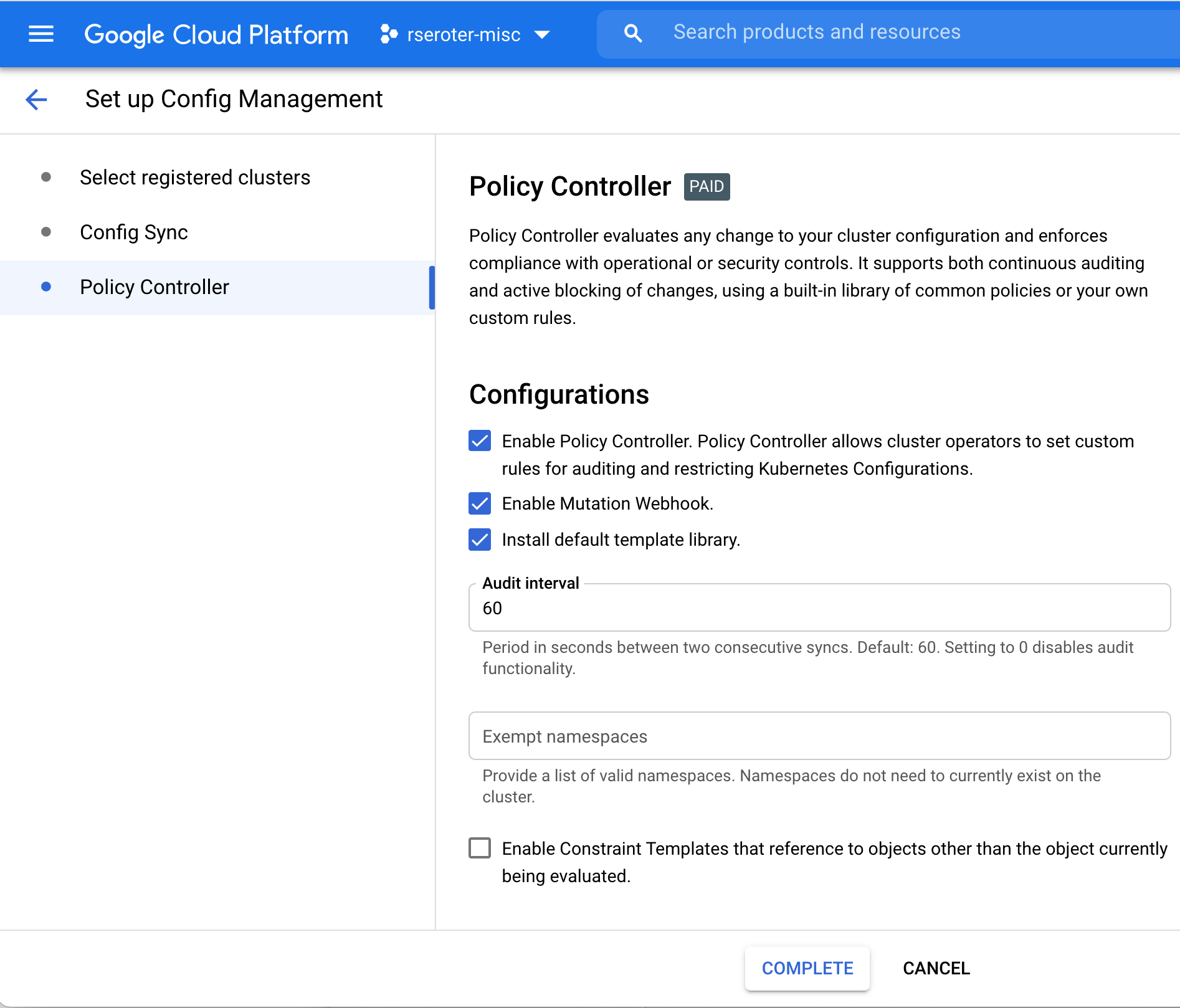
At this point, I have a single cluster with policy guardrails and applied configurations. I also have the option of adding the Config Connector to a cluster directly. In that scenario, a cluster might look like this:
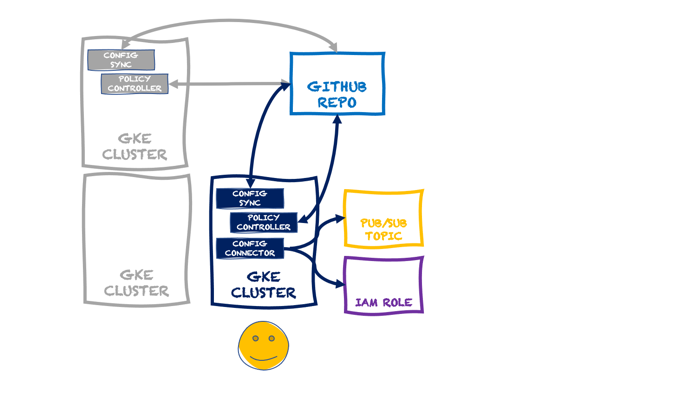
In that diagram, the GKE cluster not only has the GKE Config Management capabilities turned on (Config Sync and Policy Controller), but we’ve also added the Config Connector. You can add that feature during cluster provisioning, or after the fact, as I show below.
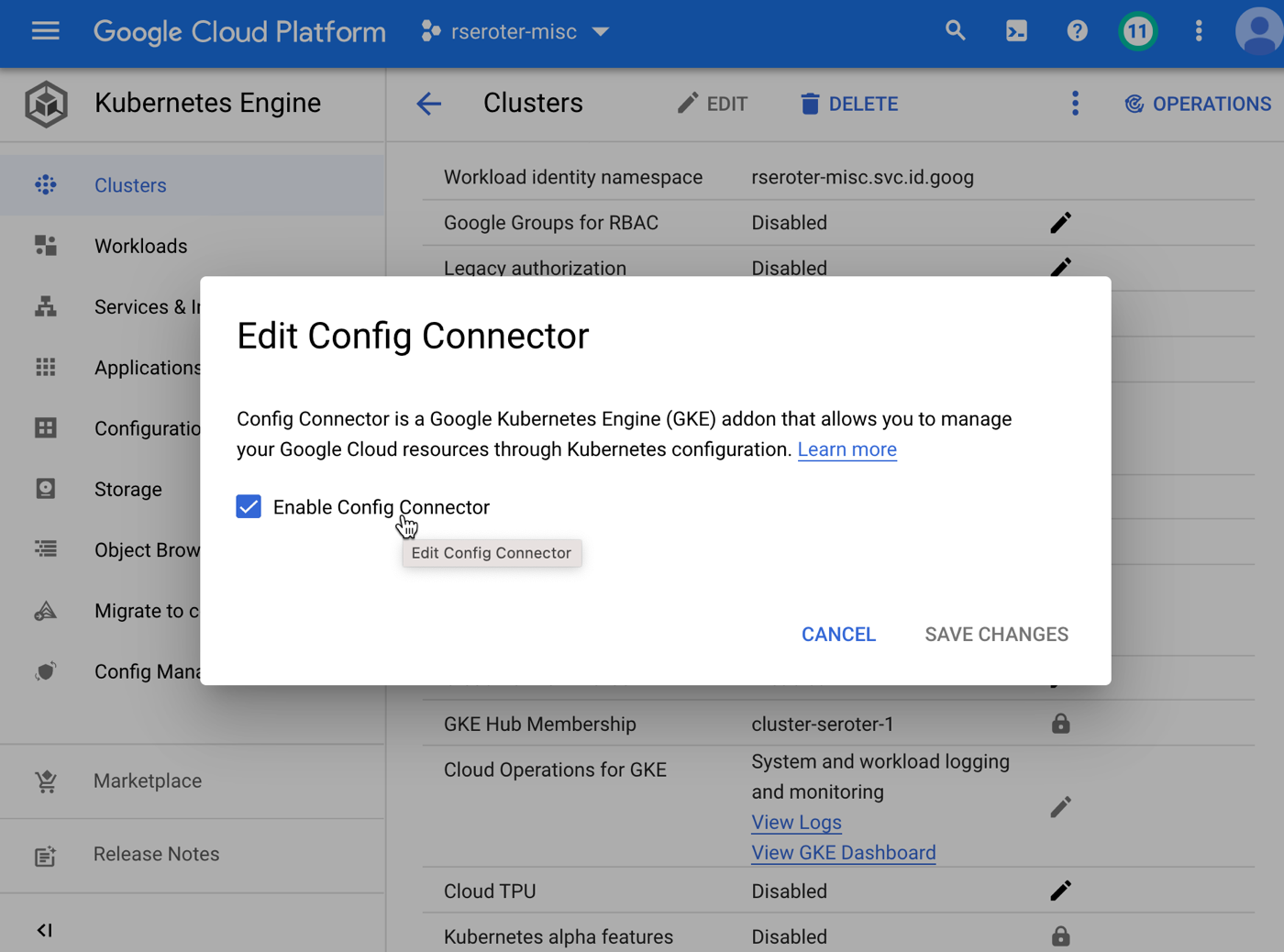
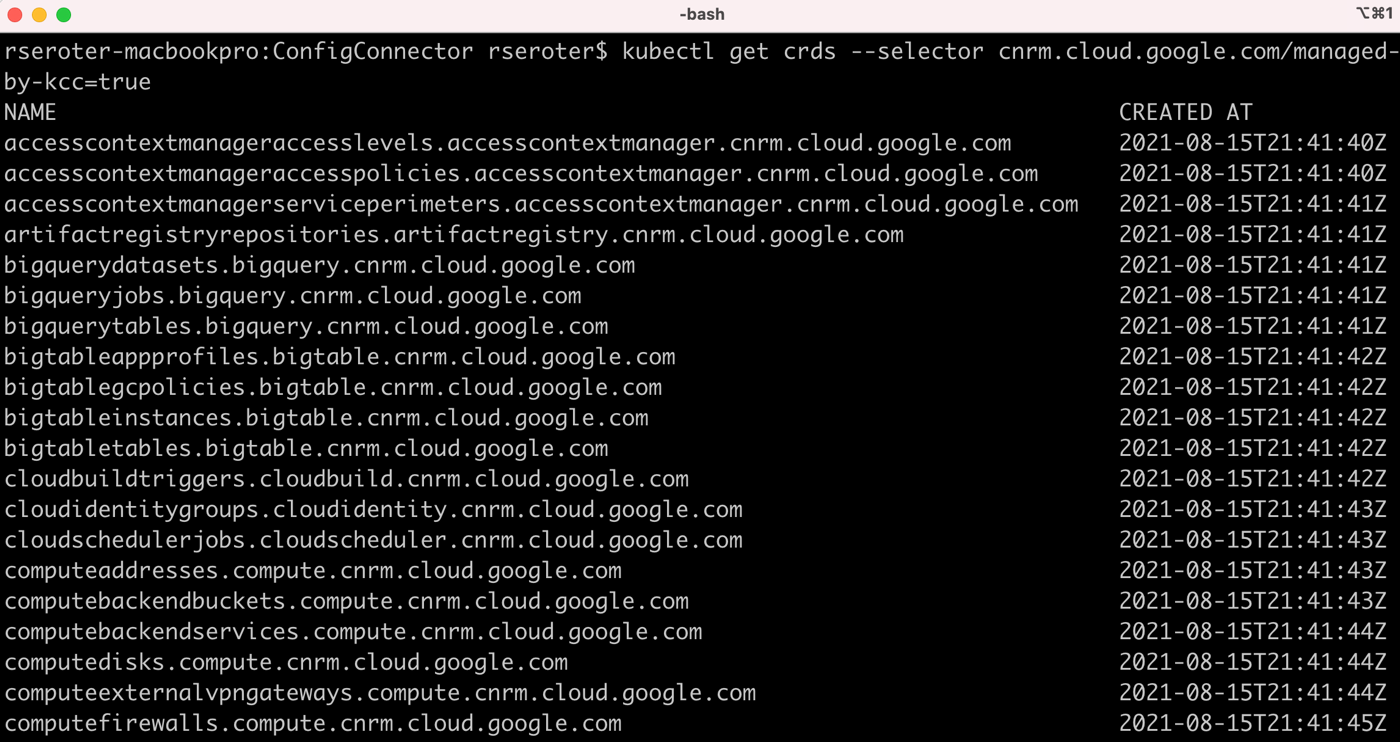
Once you create an identity for the Config Connector to use, and annotate a Kubernetes namespace that holds the created resources, you’re good to go. I see all the cloud services we can create and manage by logging into my cluster and issuing this command:
kubectl get crds --selector cnrm.cloud.google.com/managed-by-kcc=true
Now, I can create instances of all sorts of Google Cloud managed services—BigQuery jobs, VMs, networks, Dataflow jobs, IAM policies, Memorystore Redis instances, Spanner databases, and more. Whether your app uses containers or functions, this capability is super useful. To create the resource I want, I write a bit of YAML. I could export an existing cloud service instance to get its representative YAML, write it from scratch, or generate it from the Cloud Code tooling. I did the latter, and produced this YAML for a managed Redis instance via Memorystore:
apiVersion: redis.cnrm.cloud.google.com/v1beta1
kind: RedisInstance
metadata:
labels:
label: "seroter-demo-instance"
name: redisinstance-managed
spec:
displayName: Redis Instance Managed
region: us-central1
tier: BASIC
memorySizeGb: 16
With a single command, I apply this resource definition to my cluster.
kubectl apply -f redis-test.yaml -n config-connector
When I query Kubernetes for “redisinstances” it knows what that means, and when I look to see if I really have one, I see it show up in the Google Cloud Console.

You could stop here. We have a fully-loaded cluster that synchronizes configurations and policies, and can create/manage Google Cloud services. But the last thing is different from the first two. Configs and policies create a secure and consistent cluster. The Config Connector is a feature that uses the Kubernetes control plane for other purposes. In reality, what you want is something like this:
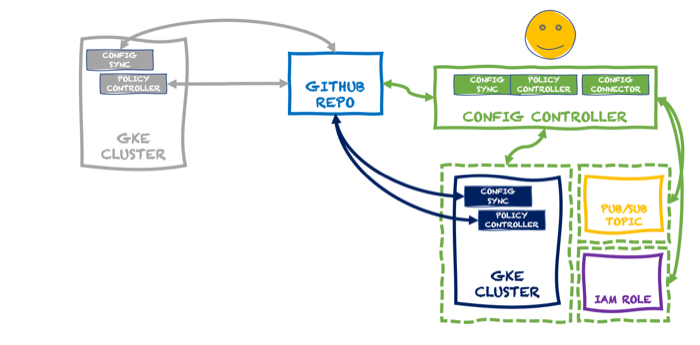
Here, we have a dedicated KRM server thanks to the managed Config Controller. With this, I can spin up and manage cloud services, including GKE clusters themselves, without running a dedicated cluster or stashing extra bits inside an existing cluster. It takes just a single command to spin up this service (which creates a managed GKE instance):
gcloud alpha anthos config controller create seroter-cc-instance \
--location=us-central1
A few minutes later, I see a cluster in the GKE console, and can query for any Config Controller instances using:
gcloud alpha anthos config controller list --location=us-central1
Now if I log into that service instance, and send in the following YAML, Config Controller provisions (and manages) a Pub/Sub topic for me.
apiVersion: pubsub.cnrm.cloud.google.com/v1beta1
kind: PubSubTopic
metadata:
labels:
label: "seroter-demo"
name: cc-topic-1
Super cool. But wait, there’s more. This declarative model shouldn’t FORCE you to know about Kubernetes. What if I want to GitOps-ify my services so that anyone could create cloud services by checking a configuration into a git repo versus kubectl apply commands? This is what makes this interesting to any developer, whether they use Kubernetes or not. Let’s try it.
I have a GitHub repo with a flattened structure. The Config Sync component within the Config Controller service will read from this repo, and and work with the Config Connector to instantiate and manage any service instances I declare. To set this up, all I do is activate Config Sync and tell it about my repo. This is the file that I send to the Config Controller to do that:
# config-management.yaml
apiVersion: configmanagement.gke.io/v1
kind: ConfigManagement
metadata:
name: config-management
spec:
#you can find your server name in the GKE console
clusterName: krmapihost-seroter-cc-instance
#not using an ACM structure, but just a flat one
sourceFormat: unstructured
git:
policyDir: /
syncBranch: main
#no service account needed since there's no read permissions required
secretType: none
syncRepo: https://github.com/rseroter/anthos-seroter-config-repo-cc
Note: this demo would have been easier if I had used Google Cloud’s Source Repositories instead of GitHub. But I figured most people would use GitHub, so I should too. The Config Controller is a private GKE cluster, which is safe and secure, but also doesn’t have outbound access. It can reach our Source Repos, but I had to add an outbound VPC firewall rule for 443, and then provision a NAT gateway so that the traffic could flow.
With all this in place, as soon as I check in a configuration, the Config Controller reads it and acts upon it. Devs just need to know YAML and git. They don’t have to know ANY Kubernetes to provision managed cloud services!
Here’s the definition for a custom IAM role.
apiVersion: iam.cnrm.cloud.google.com/v1beta1
kind: IAMCustomRole
metadata:
name: iamcustomstoragerole
namespace: config-control
spec:
title: Storage Custom Role
description: This role only contains two permissions - read and update
permissions:
- storage.buckets.list
- storage.buckets.get
stage: GA
When I add that to my repo, I almost immediately see a new role show up in my account. And if I mess with that role directly by removing or adding permissions, I see Config Controller detect that configuration drift and return the IAM role back to the desired state.

This concept gets even more powerful when you look at the blueprints we’re creating. Stamp out projects, landing zones, and GKE clusters with best practices applied. Imagine using the Config Controller to provision all your GKE clusters and prevent drift. If someone went into your cluster and removed Config Sync or turned off Workload Identity, you’d be confident knowing that Config Controller would reset those properties in short order. Useful!
In this brave new world, you can can keep Kubernetes clusters in sync and secured by storing configurations and policies in a git repo. And you can leverage that same git repo to store declarative definitions of cloud services, and ask the KRM-powered Config Controller to instantiate and manage those services. To me, this makes managing an at-scale cloud environment look much more straightforward.

Leave a comment