First off, I am NOT a data analytics person. My advice is sketchy enough when it comes to app development and distributed systems that I don’t need to overreach into additional areas. That said, we at Google Cloud quietly shipped a new data-related feature this week that sparked my interest, and I figured that we could explore it together.
To be sure, loading data into a data warehouse is a solved problem. Many of us have done this via ETL (extract-transform-load) tools and streaming pipelines for years. It’s all very mature technology, even when steering your data towards newfangled cloud data warehouses like the fully-managed Google Cloud’s BigQuery. Nowadays, app developers can also insert directly into these systems from their code. But what about your event-driven apps? It could be easier than it is today! This is why I liked this new subscription type for Google Cloud Pub/Sub—our messaging engine for routing data between systems—that is explicitly for BigQuery. That’s right, you can directly subscribe your data warehouse to your messaging system.
Let’s try it out, end to end.
First, I needed some data. BigQuery offers an impressive set of public data sets, including those with crime statistics, birth data summaries, GitHub activity, census data, and even baseball statistics. I’m not choosing any of those, because I wanted to learn more about how BigQuery works. So, I built a silly comma-separated file of “pet visits” to my imaginary pet store chain.
1,"store400","2022-07-26 06:22:10","Mittens","cat","camp",806 2,"store405","2022-07-26 06:29:15","Jessie","dog","bath",804 3,"store400","2022-07-26 07:01:34","Ellie","dog","nailtrim",880 4,"store407","2022-07-26 07:02:00","Rocket","cat","bath",802 5,"store412","2022-07-26 07:06:45","Frank","cat","bath",853 6,"store400","2022-07-26 08:08:08","Nala","cat","nailtrim",880 7,"store407","2022-07-26 08:15:04","Rocky","dog","camp",890 8,"store402","2022-07-26 08:39:16","Cynthia","bird","spa",857 9,"store400","2022-07-26 08:51:14","Watson","dog","haircut",831 10,"store412","2022-07-26 09:05:58","Manny","dog","camp",818
I saved this data as “pets.csv” and uploaded it into a private, regional Google Cloud Storage Bucket.

Excellent. Now I wanted this data loaded into a BigQuery table that I could run queries against. And eventually, load new data into when it flows through Pub/Sub.
I’m starting with no existing data sets or tables in BigQuery. You can see here that all I have is my “project.” And there’s no infrastructure to provision or manage here, so all we have to think about is our data. Amazing.

As an aside, we make it very straightforward to pull in data from all sorts of sources, even those outside of Google Cloud. So, this really can be a single solution for all your data analytics needs. Just sayin’. In this scenario, I wanted to add data to a BigQuery table, so I started by selecting my project and choosing to “create a dataset“, which is really just a container for data tables.

Next, I picked my data set and click the menu option to “create table.” Here’s where it gets fun. I can create an empty table, upload some data or point to object storage repos like Google Cloud Storage, Amazon S3, or Azure Blob Storage. I chose Cloud Storage. Then I located my Storage bucket and chose “CSV” as the file format. Other options include JSON, Avro, and Parquet. Then I gave my table a name (“visits_table”). So far so good.

The last part of this table creation process involves schema definition. BigQuery can autodetect the schema (data types and such), but I wanted to define it manually. The graphical interface offers a way to define column name, data type, and whether it’s a required data point or not.

After creating the table, I could see the schema and run queries against the data. For example, this is a query that returns the count of each animal type coming into my chain of pet stores for service.

You could imagine there might be some geospatial analysis, machine learning models, or other things we constantly do with this data set over time. That said, let’s hook it up to Pub/Sub so that we can push a real-time stream of “visits” from our event-driven architecture.
Before we forget, we need to change permissions to allow Pub/Sub to send data to BigQuery tables. From within Google Cloud IAM, I chose to “include Google-provided role grants” in the list of principals, located my built-in Pub/Sub service account, and added the “BigQuery Data Editor” and “BigQuery Metadata Viewer” roles.

When publishing from Pub/Sub to BigQuery you have a couple of choices for how to handle the data. One option is to dump the entire payload into a single “data” field, which doesn’t sound exciting. The other option is to use a Pub/Sub schema so that the data fields map directly to BigQuery table columns. That’s better. I navigated to the Pub/Sub “Schemas” dashboard and created a new schema.

If kids are following along at home, the full schema looks like this:
{
"type": "record",
"name": "Avro",
"fields": [
{
"name": "apptid",
"type": "int"
},
{
"name": "storeid",
"type": "string"
},
{
"name": "visitstamp",
"type": "string"
},
{
"name": "petname",
"type": "string"
},
{
"name": "animaltype",
"type": "string"
},
{
"name": "servicetype",
"type": "string"
},
{
"name": "customerid",
"type": "int"
}
]
}
We’re almost there. Now we just needed to create the actual Pub/Sub topic and subscription. I defined a new topic named “pets-topic”, and selected the box to “use a schema.” Then I chose the schema we created above.

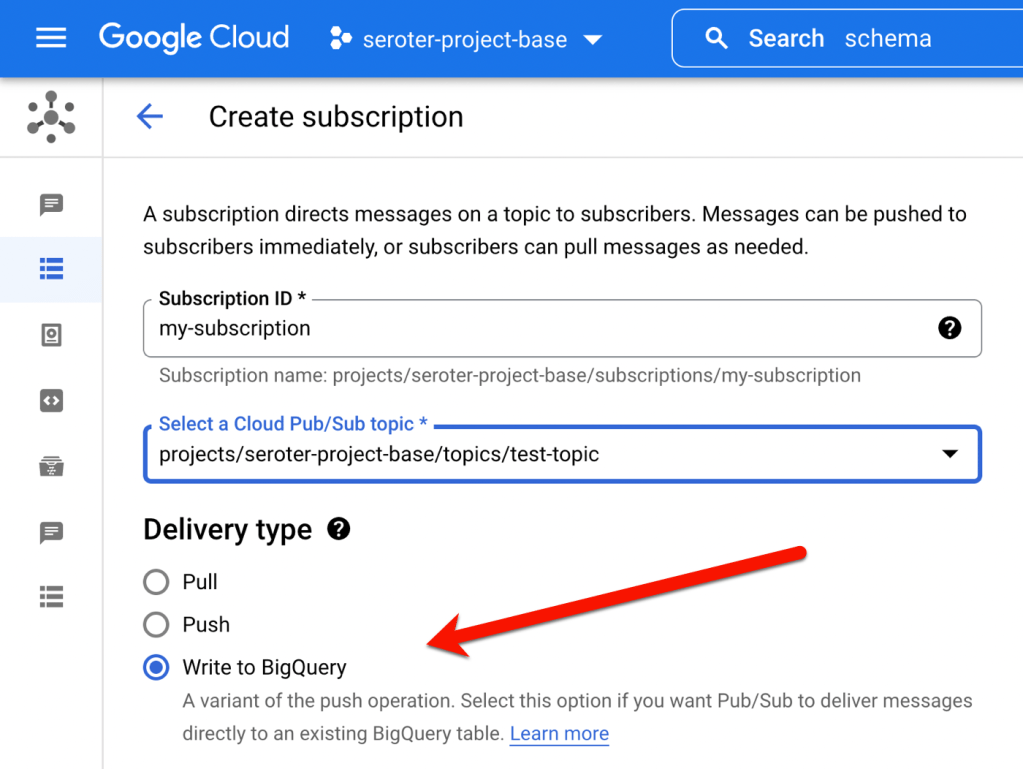
Now for the subscription itself. As you see below, there’s a “delivery type” for “Write to BigQuery” which is super useful. Once I chose that, I was asked for the dataset and table, and I chose the option to “use topic schema” so that the message body would map to the individual columns in the table.

This is still a “regular” Pub/Sub subscription, so if I wanted to, I could set properties like message retention duration, expiration period, subscription filters, and retry policies.
Nothing else to it. And we did it all from the Cloud Console. To test this out, I went to my topic in the Cloud Console, and chose to send a message. Here, I sent a single message that conformed to the topic schema.

Almost immediately, my BigQuery table got updated and I saw the new data in my query results.

When I searched online, I saw various ways that people have stitched together their (cloud) messaging engines with their data warehouse. But from what I can tell, what we did here is the simplest, most-integrated way to pull that off. Try it out and tell me what you think!

Leave a comment