
My name is Richard, and I like to run as admin. There, I said it. You should rarely listen to me for good security advice since I’m now (always?) a pretend developer who does things that are easy, not necessarily right. But identity management is something I wanted to learn more about in 2021, so now I’m actually trying. Specifically, I’m exploring the best ways for my applications to securely access cloud services. In this post, I’ll introduce you to GKE Workload Identity, and why it seems like a terrific way to do the right thing.
First, let’s review some of your options for providing access to distributed components—think databases, storage, message queues, and the like—from your application.
- Store credentials in application variables. This is terrible. Which means I’ve done it before myself. Never do this, for roughly 500 different reasons.
- Store credentials in property files. This is also kinda awful. First, you tend to leak your secrets often because of this. Second, it might as well be in the code itself, as you still have to change, check in, do a build, and do a deploy to make the config change.
- Store credentials in environment variables. Not great. Yes, it’s out of your code and config, so that’s better. But I see at least three problems. First, it’s likely not encrypted. Second, you’re still exporting creds from somewhere and storing them here. Third, there’s no version history or easy management (although clouds offer some help here). Pass.
- Store credentials in a secret store. Better. At least this is out of your code, and in a purpose-built structure for securely storing sensitive data. This might be something robust like Vault, or something more basic like Kubernetes Secrets. The downside is still that you are replicating credentials outside the Identity Management system.
- Use identity federation. Here we go. How about my app runs under an account that has the access it needs to a given service? This way, we’re not extracting and stashing credentials. Seems like the ideal choice.
So, if identity federation is a great option, what’s the hard part? Well, if my app is running in Kubernetes, how do I run my workload with the right identity? Maybe through … Workload Identity? Basically, Workload Identity lets you map a Kubernetes service account to a given Google Cloud service account (there are similar types of things for EKS in AWS, and AKS in Azure). At no point does my app need to store or even reference any credentials. To experiment, I created a basic Spring Boot web app that uses Spring Cloud GCP to talk to Cloud Storage and retrieve all the files in a given bucket.
package com.seroter.gcpbucketreader;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import com.google.api.gax.paging.Page;
import com.google.cloud.storage.Blob;
import com.google.cloud.storage.Storage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.stereotype.Controller;
import org.springframework.ui.Model;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestParam;
@Controller
@SpringBootApplication
public class GcpBucketReaderApplication {
public static void main(String[] args) {
SpringApplication.run(GcpBucketReaderApplication.class, args);
}
//initiate auto-configuration magic that pulls in the right credentials at runtime
@Autowired(required=false)
private Storage storage;
@GetMapping("/")
public String bucketList(@RequestParam(name="bucketname", required=false, defaultValue="seroter-bucket-logs") String bucketname, Model model) {
List<String> blobNames = new ArrayList<String>();
try {
//get the objects in the bucket
Page<Blob> blobs = storage.list(bucketname);
Iterator<Blob> blobIterator = blobs.iterateAll().iterator();
//stash bucket names in an array
while(blobIterator.hasNext()) {
Blob b = blobIterator.next();
blobNames.add(b.getName());
}
}
//if anything goes wrong, catch the generic error and add to view model
catch (Exception e) {
model.addAttribute("errorMessage", e.toString());
}
//throw other values into the view model
model.addAttribute("bucketname", bucketname);
model.addAttribute("bucketitems", blobNames);
return "bucketviewer";
}
}
I built and containerized this app using Cloud Build and Cloud Buildpacks. It only takes a few lines of YAML and one command (gcloud builds submit --config cloudbuild.yaml .) to initiate the magic.
steps:
# use Buildpacks to create a container image
- name: 'gcr.io/k8s-skaffold/pack'
entrypoint: 'pack'
args: ['build', '--builder=gcr.io/buildpacks/builder', '--publish', 'us-west1-docker.pkg.dev/seroter-anthos/seroter-images/boot-bucketreader:$COMMIT_SHA']
In a few moments, I had a container image in Artifact Registry to use for testing.
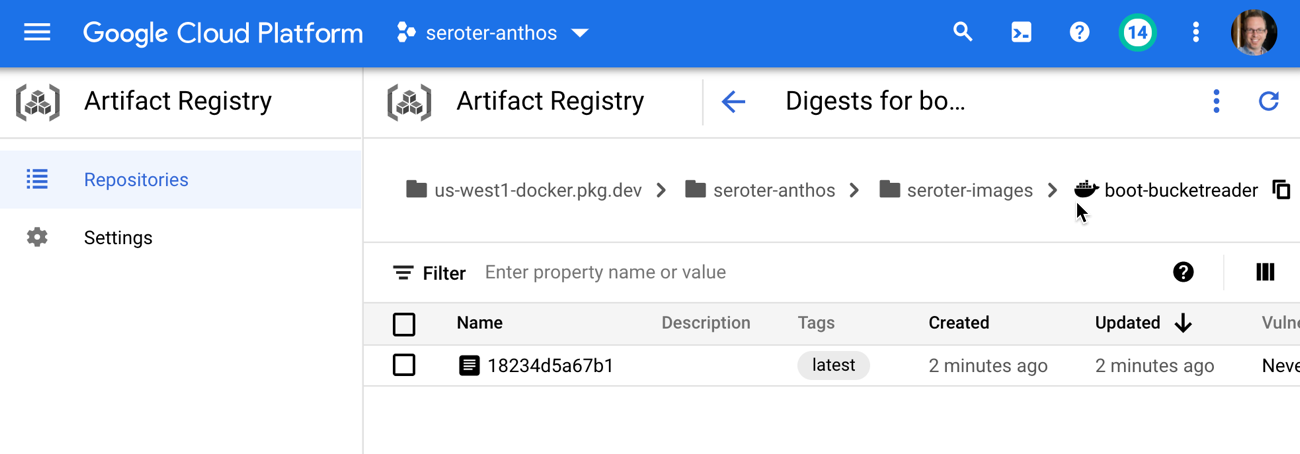
Then I loaded up a Cloud Storage bucket with a couple of nonsense files.

Let’s play through a few scenarios to get a better sense of what Workload Identity is all about.
Scenario #1 – Cluster runs as the default service account
Without Workload Identity, a pod in GKE assumes the identity of the service account associated with the cluster’s node pool.
When creating a GKE cluster, you choose a service account for a given node pool. All the nodes runs as this account.

I built a cluster using the default service account, which can basically do everything in my Google Cloud account. That’s fun for me, but rarely something you should ever do.
From within the GKE console, I went ahead and deployed an instance of our container to this cluster. Later, I’ll use Kubernetes YAML files to deploy pods and expose services, but the GUI is fun to use for basic scenarios.

Then, I created a service to route traffic to my pods.

Once I had a public endpoint to ping, I sent a request to the page and provided the bucket name as a querystring parameter.
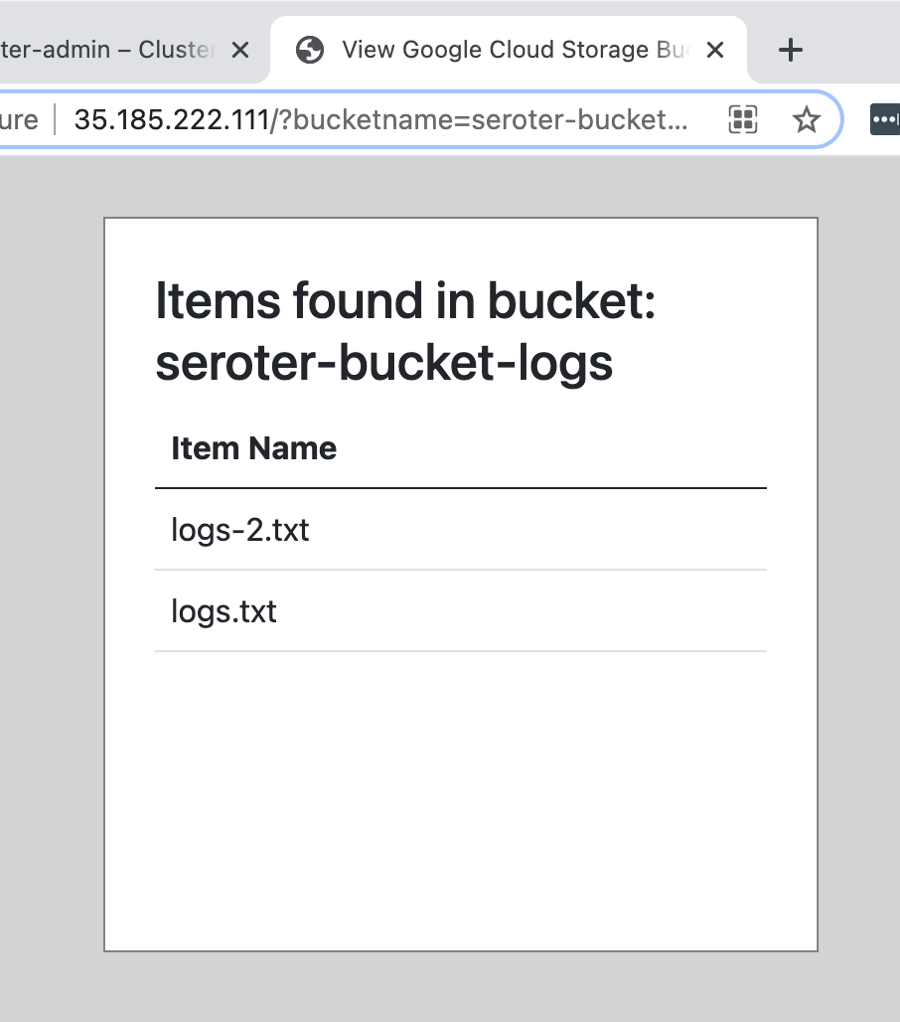
That worked, as expected. Since the pod runs as a super-user, it had full permission to Cloud Storage, and every bucket inside. While that’s a fun party trick, there aren’t many cases where the workloads in a cluster should have access to EVERYTHING.
Scenario #2 – Cluster runs as a least privilege service account
Let’s do the opposite and see what happens. This time, I started by creating a new Google Cloud service account that only had “read” permissions to the Artifact Registry (so that it could pull container images) and Kubernetes cluster administration rights.

Then, I built another GKE cluster, but this time, chose this limited account as the node pool’s service account.
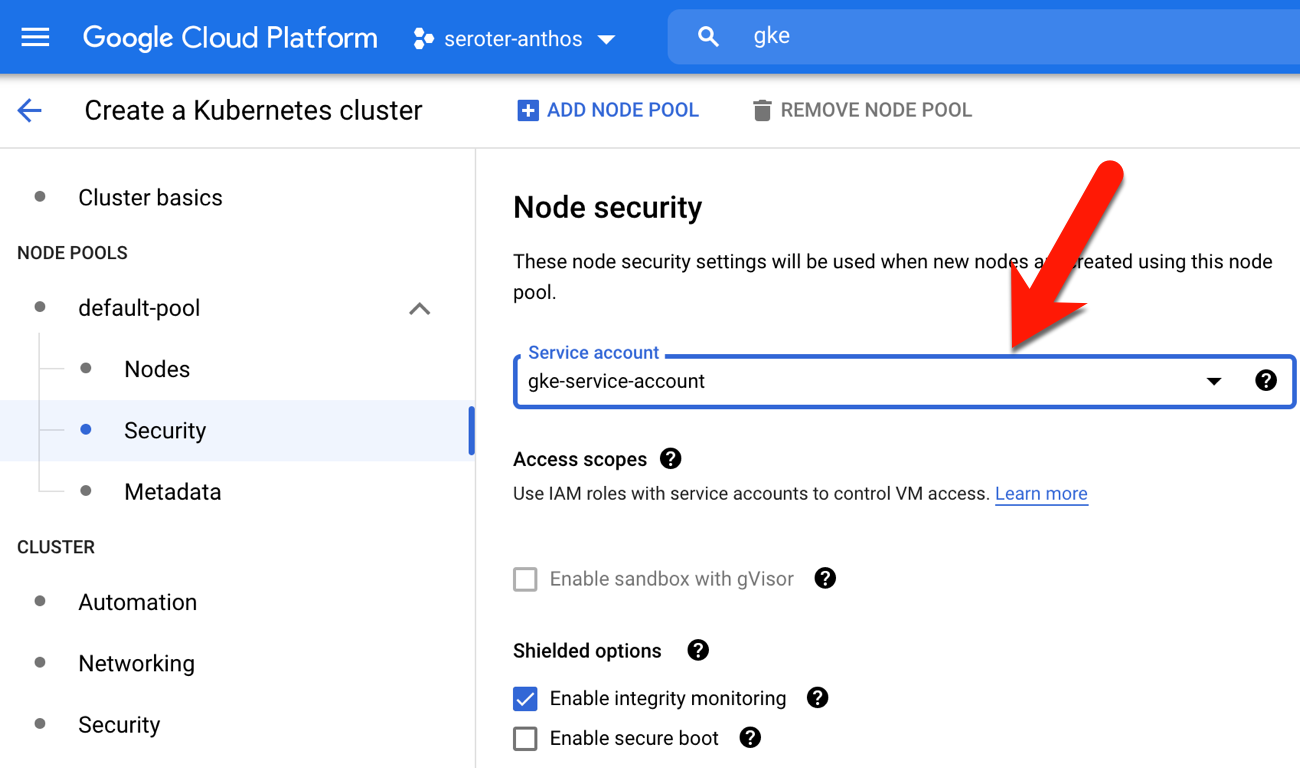
After building the cluster, I went ahead and deployed the same container image to the new cluster. Then I added a service to make these pods accessible, and called up the web page.
As expected, the attempt to read my Storage bucket failed, This least privilege account didn’t have rights to Cloud Storage.
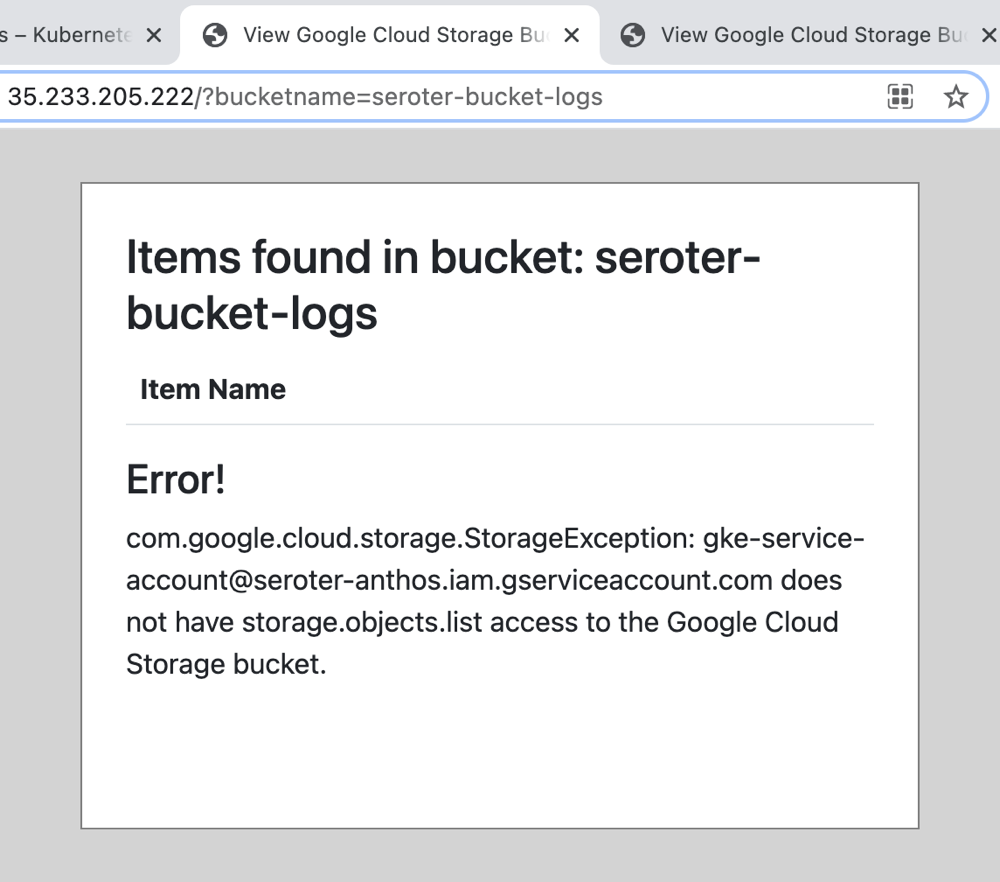
This is a more secure setup, but now I need a way for this app to securely call the Cloud Storage service. Enter Workload Identity.
Scenario #3 – Cluster has Workload Identity configured with a mapped service account
I created yet another cluster. This time, I chose the least privilege account, and also chose to install Workload Identity. How does this work? When my app ran before, it used (via the Spring Cloud libraries) the Compute Engine metadata server to get a token to authenticate with Cloud Storage. When I configure Workload Identity, those requests to the metadata server get routed to the GKE metadata server. This server runs on each cluster node, mimics the Compute Engine metadata server, and gives me a token for whatever service account the pod has access to.

If I deploy my app now, it still won’t work. Why? I haven’t actually mapped a service account to the namespace my pod gets deployed into!
I created the namespace, created a Kubernetes service account, created a Google Cloud storage account, mapped the two together, and annotated our service account. Let’s go step by step.
First, I created the namespace to hold my app.
kubectl create namespace blog-demos
Next, I created a Kubernetes service account (“sa-storageapp”) that’s local to the cluster, and namespace.
kubectl create serviceaccount --namespace blog-demos sa-storageapp
After that, I created a new Google Cloud service account named gke-storagereader.
gcloud iam service-accounts create gke-storagereader
Now we’re ready for some account mapping. First, I made the Kubernetes service account a member of my Google Cloud storage account.
gcloud iam service-accounts add-iam-policy-binding \
--role roles/iam.workloadIdentityUser \
--member "serviceAccount:seroter-anthos.svc.id.goog[blog-demos/sa-storageapp]" \
gke-storagereader@seroter-anthos.iam.gserviceaccount.com
Now, to give the Google Cloud service account the permission it needs to talk to Cloud Storage.
gcloud projects add-iam-policy-binding seroter-anthos \
--member="serviceAccount:gke-storagereader@seroter-anthos.iam.gserviceaccount.com" \
--role="roles/storage.objectViewer"
The final step? I had to add an annotation to the Kubernetes service account that links to the Google Cloud service account.
kubectl annotate serviceaccount \
--namespace blog-demos \
sa-storageapp \
iam.gke.io/gcp-service-account=gke-storagereader@seroter-anthos.iam.gserviceaccount.com
Done! All that’s left is to deploy my Spring Boot application.
First I set my local Kubernetes context to the target namespace in the cluster.
kubectl config set-context --current --namespace=blog-demos
In my Kubernetes deployment YAML, I pointed to my container image, and provided a service account name to associate with the deployment.
apiVersion: apps/v1
kind: Deployment
metadata:
name: boot-bucketreader
spec:
replicas: 1
selector:
matchLabels:
app: boot-bucketreader
template:
metadata:
labels:
app: boot-bucketreader
spec:
serviceAccountName: sa-storageapp
containers:
- name: server
image: us-west1-docker.pkg.dev/seroter-anthos/seroter-images/boot-bucketreader:latest
ports:
- containerPort: 8080
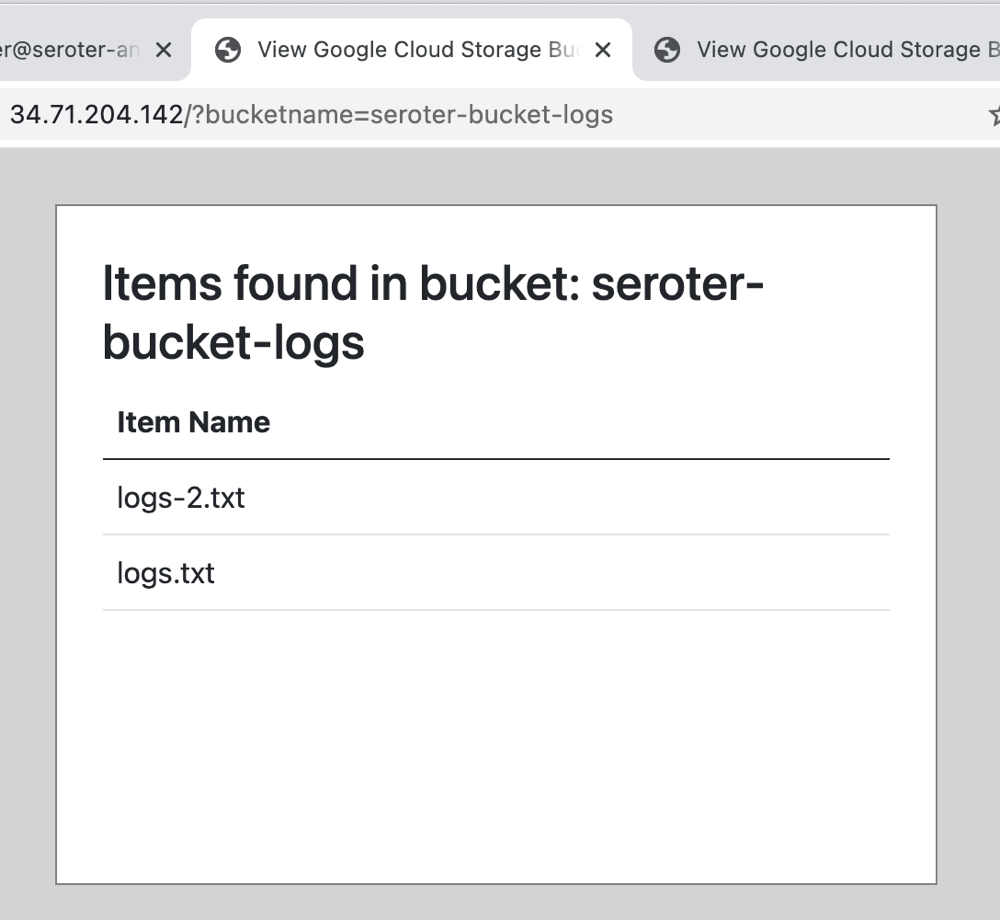
I then deployed a YAML file to create a routable service, and pinged my application. Sure enough, I now had access to Cloud Storage.
Wrap
Thanks to Workload Identity for GKE, I created a cluster that had restricted permissions, and selectively gave permission to specific workloads. I could get even more fine-grained by tightening up the permissions on the GCP service account to only access a specific bucket (or database, or whatever). Or have different workloads with different permissions, all in the same cluster.
To me, this is the cleanest, most dev-friendly way to do access management in a Kubernetes cluster. And we’re bringing this functionality to GKE clusters that run anywhere, via Anthos.
What about you? Any other ways you really like doing access management for Kubernetes-based applications?

Leave a comment