APIs, APIs everywhere. They power our mobile apps, connect our “things”, and improve supply chains. API management suites popped up to help companies secure, tune, version, and share their APIs effectively. I’ve watched these suites expand beyond the initial service virtualization and policy definition capabilities to, in some cases, replace the need for an ESB. One such suite is Azure API Management. I decided to take Azure API Management for a spin, and use it with a web service running in Cloud Foundry.
Cloud Foundry is an ideal platform for running modern apps, and it recently added a capability (“Route Services“) that lets you inject another service into the request path. Why is this handy? I could use this feature to transparently introduce a caching service, a logging service, an authorization service, or … an API gateway. Thanks to Azure API Management, I can add all sorts of functionality to my API, without touching the code. Specifically, I’m going to try and add response caching, rate limiting, and IP address filtering to my API.

Step 1 – Deploy the web service
I put together a basic Node.js app that serves up “startup ideas.” If you send an HTTP GET request to the root URL, you get all the ideas back. If you GET a path (“/startupideas/1”) you get a specific idea. Nothing earth-shattering.
Next up, deploying my app to Cloud Foundry. If your company cares about shipping software, you’re probably already running Pivotal Cloud Foundry somewhere. If not, no worries. Nobody’s perfect. You can try it out for free on Pivotal Web Services, or by downloading a fully-encapsulated VM.
Note: For production scenarios, you’d want your API gateway right next to your web services. So if you want to use Cloud Foundry with Azure API Management, you’ll want to run apps in Pivotal Cloud Foundry on Azure!
The Cloud Foundry CLI is a super-powerful tool, and makes it easy to deploy an app—Java, .NET, Node.js, whatever. So, I typed in “cf push” and watched Cloud Foundry do it’s magic.

In a few seconds, my app was accessible. I sent in a request, and got back a JSON response along with a few standard HTTP headers.

At this point, I had a fully working service deployed, but was in dire need of API management.
Step 2 – Create an instance of Azure API Management
Next up, I set up an instance of Azure API Management. From within the Azure Portal, I found it under the “Web + Mobile” category.

After filling in all the required fields and clicking “create”, I waited about 15 minutes for my instance to come alive.

Step 3 – Configure API in Azure API Management
The Azure API Management product is meant to help companies create and manage their APIs. There’s a Publisher Portal experience for defining the API and managing user subscriptions, and a Developer Portal targeted at devs who consume APIs. Both portals are basic looking, but the Publisher Portal is fairly full-featured. That’s where I started.
Within the Publisher Portal, I defined a new “Product.” A product holds one or more APIs and has settings that control who can view and subscribe to those APIs. By default, developers who want to use APIs have to provide a subscription token in their API calls. I don’t feel like requiring that, so I unchecked the “require subscription” box.

With a product in place, I added an API record. I pointed to the URL of my service in Cloud Foundry, but honestly, it didn’t matter. I’ll be overwriting it later at runtime.

In Azure API Management, you can call out each API operation (URL + HTTP verb) separately. For a given operation, you have the choice of specifying unique behaviors (e.g. caching). For a RESTful service, the operations could be represented by a mix of HTTP verbs and extension of the URL path. That is, one operation might be to GET “/customers” and another could GET “/customers/100/orders.”

In the case of Route Services, the request is forwarded by Cloud Foundry to Azure API Management without any path information. It redirects all requests to the root URL in Azure API Management and puts the full destination URL in an HTTP header (“x-cf-forwarded-url”). What does that mean? It means that I need to define a single operation in Azure API Management, and use policies to add different behaviors for each operation represented by unique paths.
Step 4 – Create API policy
Now, the fun stuff! Azure API Management has a rich set of management policies that we use to define our API’s behavior. As mentioned earlier, I wanted to add three behaviors: caching, IP address filtering, and rate limited. And for fun, I also wanted to add an output HTTP header to prove that traffic flowed through the API gateway.
You can create policies for the whole product, the API, or the individual operation. Or all three! The policy that Azure API Management ends up using for your API is a composite of all applicable policies. I started by defining my scope at the operation level.

Below is my full policy. What should you pay attention to? On line 10, notice that I set the target URL to whatever Cloud Foundry put into the x-cf-forwarded-url header. On lines 15-18, I do IP filtering to keep a particular source IP from calling the service. See on line 23 that I’m rate limiting requests to the root URL (all ideas) only. Lines 25-28 spell out the request caching policy. Finally, on line 59 I define the cache expiration period.
<policies>
<!-- inbound steps apply to inbound requests -->
<inbound>
<!-- variable is "true" if request into Cloud Foundry includes /startupideas path -->
<set-variable name="isStartUpIdea" value="@(context.Request.Headers["x-cf-forwarded-url"].Last().Contains("/startupideas"))" />
<choose>
<!-- make sure Cloud Foundry header exists -->
<when condition="@(context.Request.Headers["x-cf-forwarded-url"] != null)">
<!-- rewrite the target URL to whatever comes in from Cloud Foundry -->
<set-backend-service base-url="@(context.Request.Headers["x-cf-forwarded-url"][0])" />
<choose>
<!-- applies if request is for /startupideas/[number] requests -->
<when condition="@(context.Variables.GetValueOrDefault<bool>("isStartUpIdea"))">
<!-- don't al low direct calls from a particular IP -->
<ip-filter action="forbid">
<address>63.234.174.122</address>
</ip-filter>
</when>
<!-- applies if request is for the root, and returns all startup ideas -->
<otherwise>
<!-- limit callers by IP to 10 requests every sixty seconds -->
<rate-limit-by-key calls="10" renewal-period="60" counter-key="@(context.Request.IpAddress)" />
<!-- lookup requests from the cache and only call Cloud Foundry if nothing in cache -->
<cache-lookup vary-by-developer="false" vary-by-developer-groups="false" downstream-caching-type="none" must-revalidate="false">
<vary-by-header>Accept</vary-by-header>
<vary-by-header>Accept-Charset</vary-by-header>
</cache-lookup>
</otherwise>
</choose>
</when>
</choose>
</inbound>
<backend>
<base />
</backend>
<!-- output steps apply to after Cloud Foundry reeturns a response -->
<outbound>
<!-- variables hold text to put into the custom outbound HTTP header -->
<set-variable name="isroot" value="returning all results" />
<set-variable name="isoneresult" value="returning one startup idea" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<bool>("isStartUpIdea"))">
<set-header name="GatewayHeader" exists-action="override">
<value>@(
(string)context.Variables["isoneresult"]
)
</value>
</set-header>
</when>
<otherwise>
<set-header name="GatewayHeader" exists-action="override">
<value>@(
(string)context.Variables["isroot"]
)
</value>
</set-header>
<!-- set cache to expire after 10 minutes -->
<cache-store duration="600" />
</otherwise>
</choose>
</outbound>
<on-error>
<base />
</on-error>
</policies>
Step 5 – Add Azure API Management to the Cloud Foundry route
At this stage, I had my working Node.js service in Cloud Foundry, and a set of policies configured in Azure API Management. Next up, joining the two!
The Cloud Foundry service marketplace makes it easy for devs to add all sorts of services to an app—databases, caches, queues, and much more. In this case, I wanted to add a user-provided service for Azure API Management to the catalog. It just took one command:
cf create-user-provided-service azureapimgmt -r https://seroterpivotal.azure-api.net
All that was left to do was bind my particular app’s route to this user-provided service. That also takes one command:
cf bind-route-service cfapps.io azureapimgmt –hostname seroter-startupideas
With this in place, Azure API Management was invisible to the API caller. The caller only sends requests to the Cloud Foundry URL, and the Route Service intercepts the request!
Step 6 – Test the service
Did it work?
When I sent an HTTP GET request to https://seroter-startupideas.cfapps.io/startupideas/1 I saw a new HTTP header in the result.

Ok, so it definitely went through Azure API Management. Next I tried the root URL that has policies for caching and rate limiting.
On the first call to the root URL, I saw an log entry recorded in Cloud Foundry, and a JSON response with the latest timestamp.

With each subsequent request, the timestamp didn’t change, and there was no entry in the Cloud Foundry logs. What did that mean? It meant that Azure API Management cached the initial response and didn’t send future requests back to Cloud Foundry. Rad!
The last test was for rate limiting. It didn’t matter how many requests I sent to https://seroter-startupideas.cfapps.io/startupideas/1 I always got a result. No surprise, as there was no rate limiting for that operation. However, when I sent a flurry of requests to https://seroter-startupideas.cfapps.io I got back the following response:

Very cool. With zero code changes, I added caching and rate-limiting to my Node.js service.
Next Steps
Azure API Management is pretty solid. There are lots of great tools in the API Gateway market, but if you’re running apps in Microsoft Azure, you should strongly consider this one. I only scratched the service of the capabilities here, and I plan to spend some more time investigating user subscription and authentication capabilities.
Have you used Azure API Management? Do you like it?
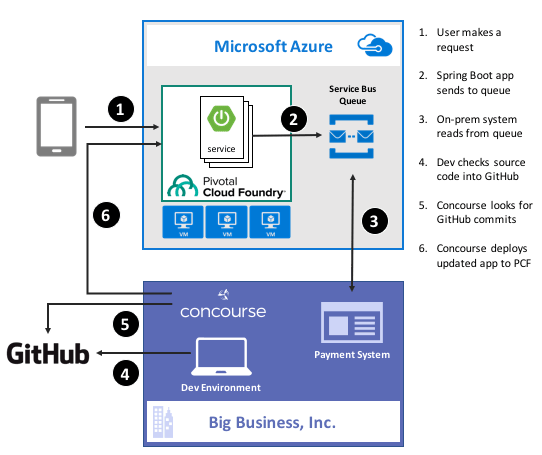





















 I just finished reading “
I just finished reading “