
I’m seeing the usual blitz of articles that predict what’s going to happen this year in tech. I’m not smart enough to make 2021 predictions, but one thing that seems certain is that most every company is deploying more software to more places more often. Can we agree on that? Companies large and small are creating and buying lots of software. They’re starting to do more continuous integration and continuous delivery to get that software out the door faster. And yes, most companies are running that software in multiple places—including multiple public clouds.
So we have an emerging management problem, no? How do I create and maintain software systems made up of many types of components—virtual machines, containers, functions, managed services, network configurations—while using different clouds? And arguably the trickiest part isn’t building the system itself, but learning and working within each cloud’s tenancy hierarchy, identity system, administration tools, and API model.
Most likely, you’ll use a mix of different build orchestration tools and configuration management tools based on each technology and cloud you’re working with. Can we unify all of this without forcing a lowest-common-denominator model that keeps you from using each cloud’s unique stuff? I think so. In this post, I’ll show an example of how to provision and manage infrastructure, apps, and managed services in a consistent way, on any cloud. As a teaser for what we’re building here, see that we’ve got a GitHub repo of configurations, and 1st party cloud managed services deployed and configured in Azure and GCP as a result.

Before we start, let’s define a few things. GitOps—a term coined by Alexis and championed by the smart folks at Weaveworks—is about declarative definitions of infrastructure, stored in a git repo, and constantly applied to the environment so that you remain in the desired state.
Next, let’s talk about the Kubernetes Resource Model (KRM). In Kubernetes, you define resources (built in, or custom) and the system uses controllers to create and manage those resources. It treats configurations as data without forcing you to specify *how* to achieve your desired state. Kubernetes does that for you. And this model is extendable to more than just containers!
The final thing I want you to know about is Google Cloud Anthos. That’s what’s tying all this KRM and GitOps stuff together. Basically, it’s a platform designed to create and manage distributed Kubernetes clusters that are consistent, connected, and application ready. There are four capabilities you need to know to grok this KRM/GitOps scenario we’re building:
- Anthos clusters and the cloud control plane. That sounds like the title of a terrible children’s book. For tech folks, it’s a big deal. Anthos deploys GKE clusters to GCP, AWS, Azure (in preview), vSphere, and bare metal environments. These clusters are then visible to (and configured by) a control plane in GCP. And you can attach any existing compliant Kubernetes cluster to this control plane as well.
- Config Connector. This is a KRM component that lets you manage Google Cloud services as if they were Kubernetes resources—think BigQuery, Compute Engine, Cloud DNS, and Cloud Spanner. The other hyperscale clouds liked this idea, and followed our lead by shipping their own flavors of this (Azure version, AWS version).
- Environs. These are logical groupings of clusters. It doesn’t matter where the clusters physically are, and which provider they run on. An environ treats them all as one virtual unit, and lets you apply the same configurations to them, and join them all to the same service mesh. Environs are a fundamental aspect of how Anthos works.
- Config Sync. This Google Cloud components takes git-stored configurations and constantly applies them to a cluster or group of clusters. These configs could define resources, policies, reference data, and more.
Now we’re ready. What are we building? I’m going to provision two Anthos clusters in GCP, then attach an Azure AKS cluster to that Anthos environ, apply a consistent configuration to these clusters, install the GCP Config Connector and Azure Service Operators into one cluster, and use Config Sync to deploy cloud managed services and apps to both clouds. Why? Once I have this in place, I have a single way to create managed services or deploy apps to multiple clouds, and keep all these clusters identically configured. Developers have less to learn, operators have less to do. GitOps and KRM, FTW!
Step 1: Create and Attach Clusters
I started by creating two GKE clusters in GCP. I can do this via the Console, CLI, Terraform, and more. Once I created these clusters (in different regions, but same GCP project), I registered both to the Anthos control plane. In GCP, the “project” (here, seroter-anthos) is also the environ.

Next, I created a new AKS cluster via the Azure Portal.

In 2020, our Anthos team added the ability to attach existing clusters an an Anthos environ. Before doing anything else, I created a new minimum-permission GCP service account that the AKS cluster would use, and exported the JSON service account key to my local machine.
From the GCP Console, I followed the option to “Add clusters to environ” where I provided a name, and got back a single command to execute against my AKS cluster. After logging into my AKS cluster, I ran that command—which installs the Connect agent—and saw that the AKS cluster connected successfully to Anthos.

I also created a service account in my AKS cluster, bound it to the cluster-admin role, and grabbed the password (token) so that GCP could log into that cluster. At this point, I can see the AKS cluster as part of my environ.
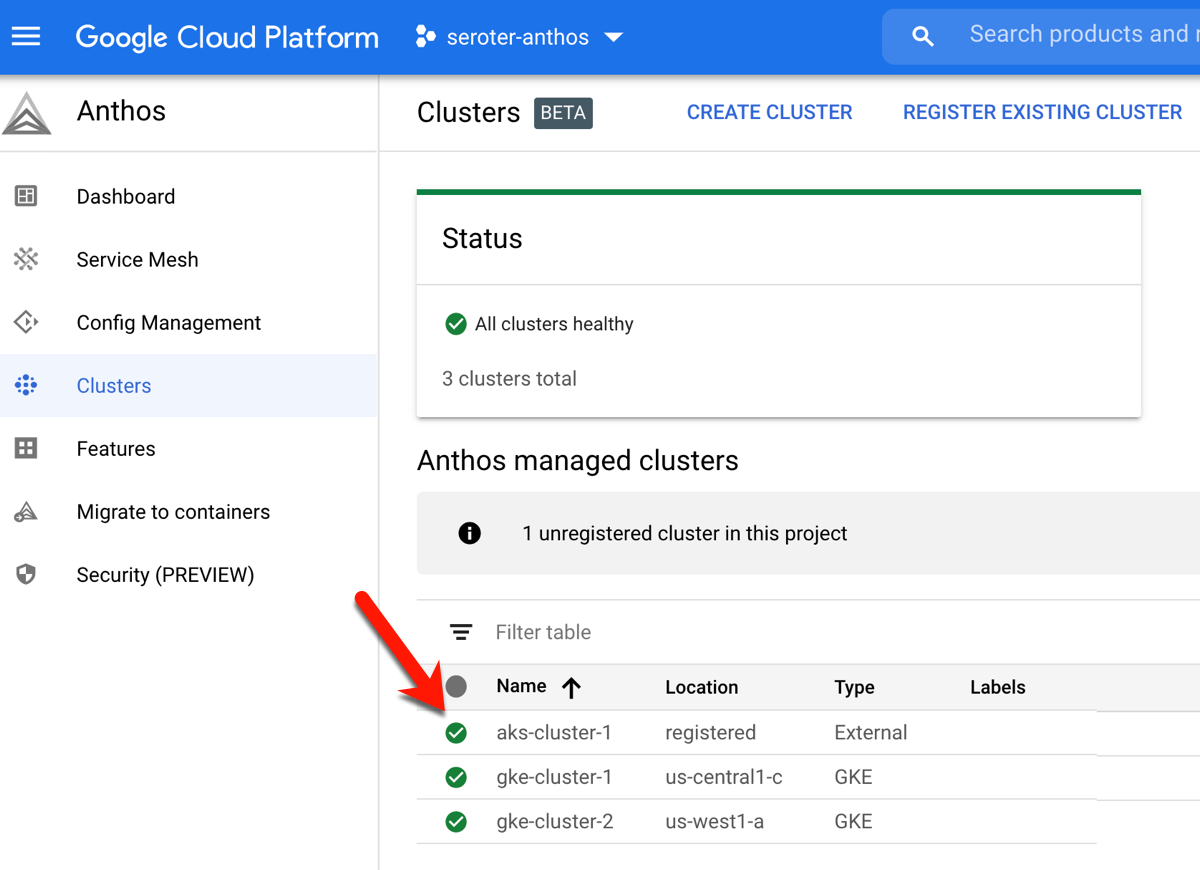
You know what’s pretty awesome? Once this AKS cluster is connected, I can view all sorts of information about cluster nodes, workloads, services, and configurations. And, I can even deploy workloads to AKS via the GCP Console. Wild.
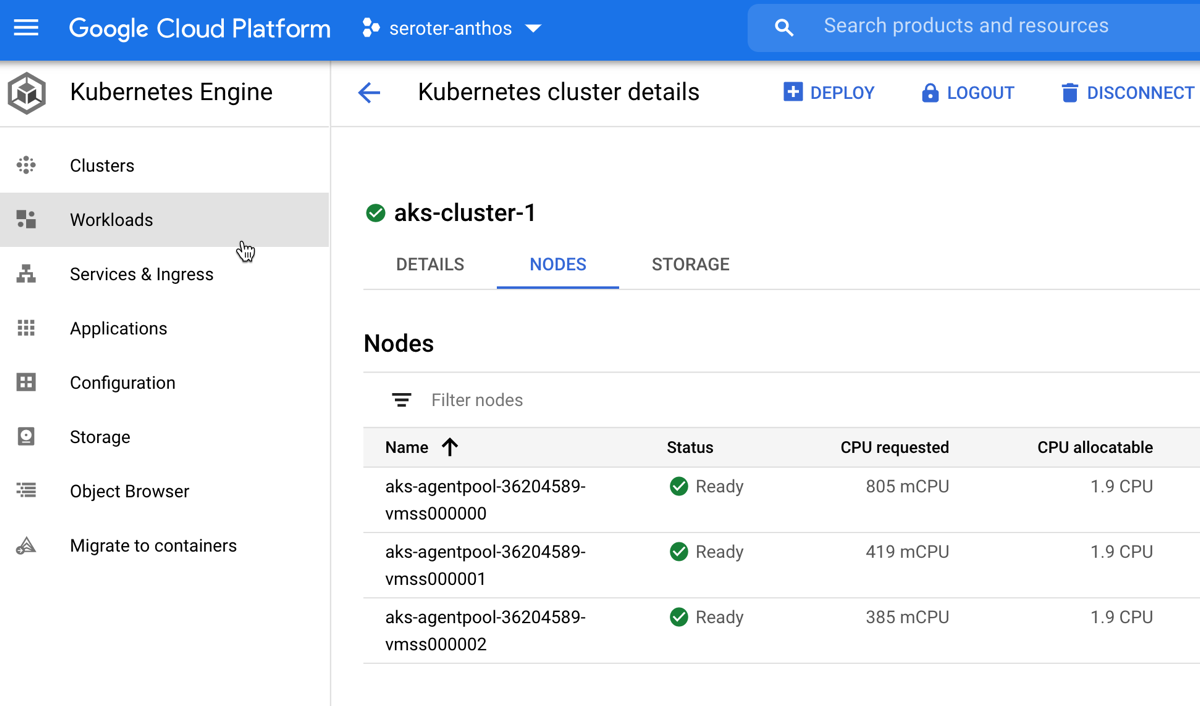
But I digress. Let’s keep going.
Step 2: Instantiate a Git Repo
GitOps requires … a git repo. I decided to use GitHub, but any reachable git repository works. I created the repo via GitHub, opened it locally, and initialized the proper structure using the nomos CLI. What does a structured repo look like and why does the structure matter? Anthos Config Management uses this repo to figure out the clusters and namespaces for a given configuration. The clusterregistry directory contains ClusterSelectors that let me scope configs to a given cluster or set of clusters. The cluster directory holds any configs that you want applied to entire clusters versus individual namespaces. And the namespaces directory holds configs that apply to a specific namespace.

Now, I don’t want all my things deployed to all the clusters. I want some namespaces that span all clusters, and others that only sit in one cluster. To do this, I need ClusterSelectors. This lets me define labels that apply to clusters so that I can control what goes where.
For example, here’s my cluster definition for the AKS cluster (notice the “name” matches the name I gave it in Anthos) that applies an arbitrary label called “cloud” with a value of “azure.”
kind: Cluster
apiVersion: clusterregistry.k8s.io/v1alpha1
metadata:
name: aks-cluster-1
labels:
environment: prod
cloud: azure
And here’s the corresponding ClusterSelector. If my namespace references this ClusterSelector, it’ll only apply to clusters that match the label “cloud: azure.”
kind: ClusterSelector
apiVersion: configmanagement.gke.io/v1
metadata:
name: selector-cloud-azure
spec:
selector:
matchLabels:
cloud: azure
After creating all the cluster definitions and ClusterSelectors, I committed and published the changes. You can see my full repo here.
Step 3: Install Anthos Config Management
The Anthos Config Management (ACM) subsystem lets you do a variety of things such as synchronize configurations across clusters, apply declarative policies, and manage a hierarchy of namespaces.
Enabling and installing ACM on GKE clusters and attached clusters is straightforward. First, we need credentials to talk to our git repo. One option is to use an SSH keypair. I generated a new keypair, and added the public key to my GitHub account. Then, I created a secret in each Kubernetes cluster that references the private key value.
kubectl create ns config-management-system && \
kubectl create secret generic git-creds \
--namespace=config-management-system \
--from-file=ssh="[/path/to/KEYPAIR-PRIVATE-KEY-FILENAME]"
With that done, I went through the GCP Console (or you can do this via CLI) to add ACM to each cluster. I chose to use SSH as the authentication mechanism, and then pointed to my GitHub repo.

After walking through the GKE clusters, I could see that ACM was installed and configured. Then I installed ACM on the AKS cluster too, all from the GCP Console.
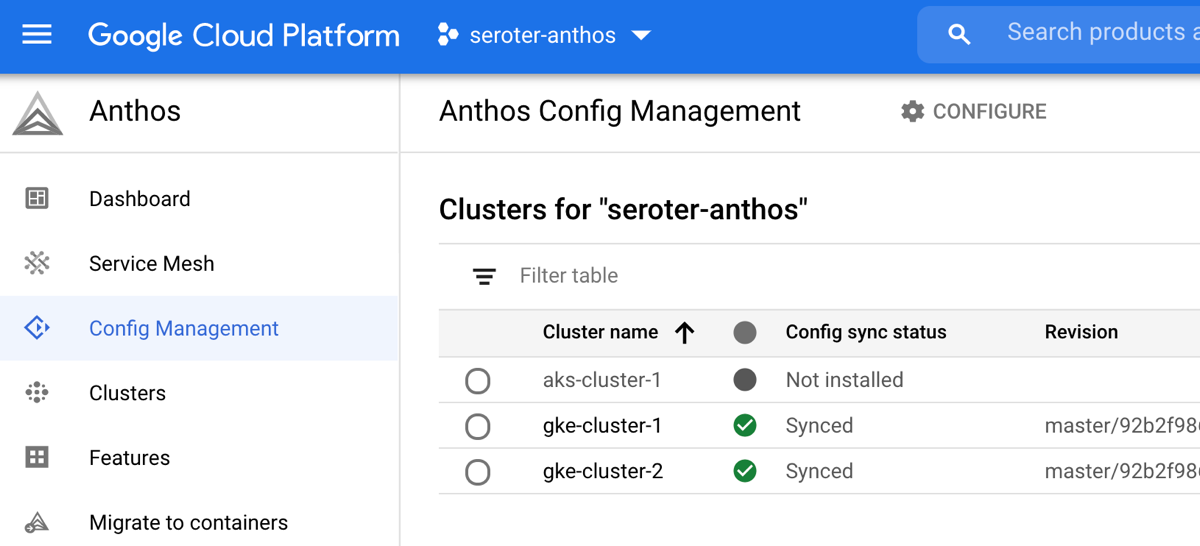
With that, the foundation of my multi-cloud platform was all set up.
Step 4: Install Config Connector and Azure Service Operator
As mentioned earlier, the Config Connector helps you treat GCP managed services like Kubernetes resources. I only wanted the Config Connector on a single GKE cluster, so I went to gke-cluster-2 in the GCP Console and “enabled” Workload Identity and the Config Connector features. Workload Identity connects Kubernetes service accounts to GCP identities. It’s pretty cool. I created a new service account (“seroter-cc”) that Config Connector would use to create managed services.
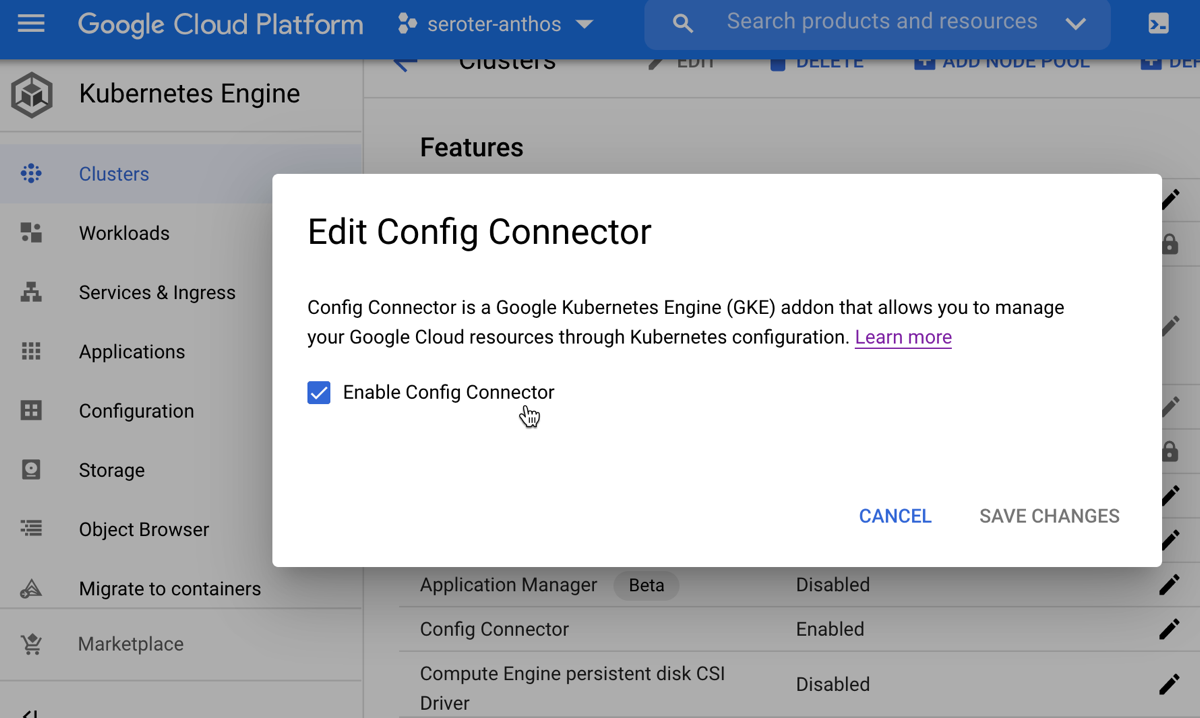
To confirm installation, I ran a “kubectl get crds” command to see all the custom resources added by the Config Connector.

There’s only one step to configure the Config Connector itself. I created a single configuration that referenced the service account and GCP project used by Config Connector.
# configconnector.yaml
apiVersion: core.cnrm.cloud.google.com/v1beta1
kind: ConfigConnector
metadata:
# the name is restricted to ensure that there is only one
# ConfigConnector instance installed in your cluster
name: configconnector.core.cnrm.cloud.google.com
spec:
mode: cluster
googleServiceAccount: "seroter-cc@seroter-anthos.iam.gserviceaccount.com"
I ran “kubectl apply -f configconnector.yaml” for the configuration, and was all set.
Since I also wanted to provision Microsoft Azure services using the same GitOps + KRM mechanism, I installed the Azure Service Operators. This involved installing a cert manager, installing Helm, creating an Azure Service Principal (that has rights to create services), and then installing the operator.
Step 5: Check-In Configs to Deploy Managed Services and Applications
The examples for the Config Connector and Azure Service Operator talk about running “kubectl apply” for each service you want to create. But I want GitOps! So, that means setting up git directories that hold the configurations, and relying on ACM (and Config Sync) to “apply” these configurations on the target clusters.
I created five namespace directories in my git repo. The everywhere-apps namespace applies to every cluster. The gcp-apps namespace should only live on GCP. The azure-apps namespace only runs on Azure clusters. And the gcp-connector and azure-connector namespaces should only live on the cluster where the Config Connector and Azure Service Operator live. I wanted something like this:
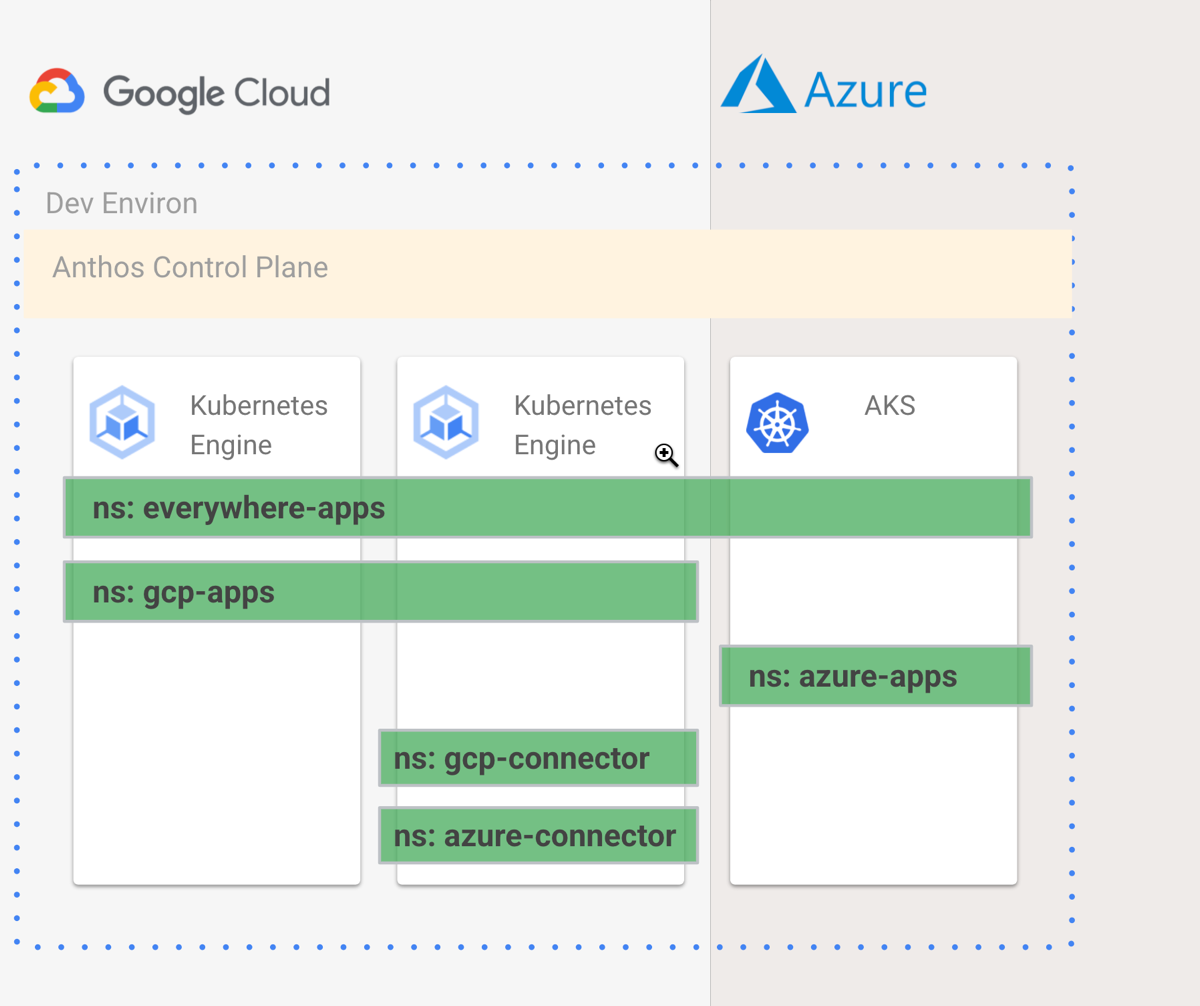
How do I create configurations that make that above image possible? Easy. Each “namespace” directory in the repo has a namespace.yaml file. This file provides the name of the namespace, and optionally, annotations. The annotation for the gcp-connector namespace used the ClusterSelector that only applied to gke-cluster-2. I also added a second annotation that told the Config Connector which GCP project hosted the generated managed services.
apiVersion: v1
kind: Namespace
metadata:
name: gcp-connector
annotations:
configmanagement.gke.io/cluster-selector: selector-specialrole-connectorhost
cnrm.cloud.google.com/project-id: seroter-anthos
I added namespace.yaml files for each other namespace, with ClusterSelector annotations on all but the everywhere-apps namespace, since that one runs everywhere.
Now, I needed the actual resource configurations for my cloud managed services. In GCP, I wanted to create a Cloud Storage bucket. With this “configuration as data” approach, we just define the resource, and ask Anthos to instantiate and manage it. The Cloud Storage configuration looks like this:
apiVersion: storage.cnrm.cloud.google.com/v1beta1
kind: StorageBucket
metadata:
annotations:
cnrm.cloud.google.com/project-id : seroter-anthos
#configmanagement.gke.io/namespace-selector: config-supported
name: seroter-config-bucket
spec:
lifecycleRule:
- action:
type: Delete
condition:
age: 7
uniformBucketLevelAccess: true
The Azure example really shows the value of this model. Instead of programmatically sequencing the necessary objects—first create a resource group, then a storage account, then a storage blob—I just need to define those three resources, and Kubernetes reconciles each resource until it succeeds. The Storage Blob resource looks like:
apiVersion: azure.microsoft.com/v1alpha1
kind: BlobContainer
metadata:
name: blobcontainer-sample
spec:
location: westus
resourcegroup: resourcegroup-operators
accountname: seroterstorageaccount
# accessLevel - Specifies whether data in the container may be accessed publicly and the level of access.
# Possible values include: 'Container', 'Blob', 'None'
accesslevel: Container
The image below shows my managed-service-related configs. I checked all these configurations into GitHub.

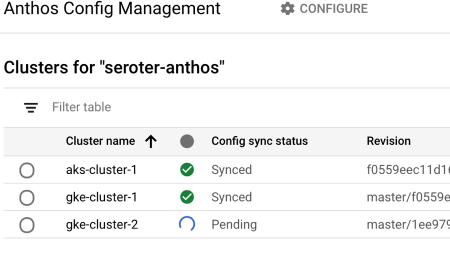
A few seconds later, I saw that Anthos was processing the new configurations.
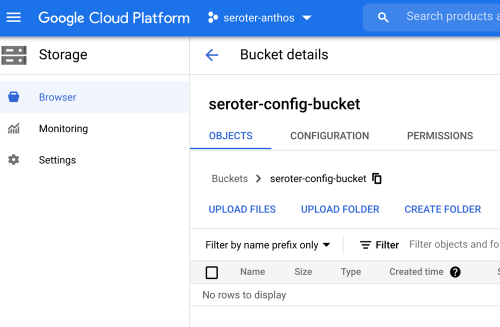
Ok, it’s the moment of truth. First, I checked Cloud Storage and saw my brand new bucket, provisioned by Anthos.
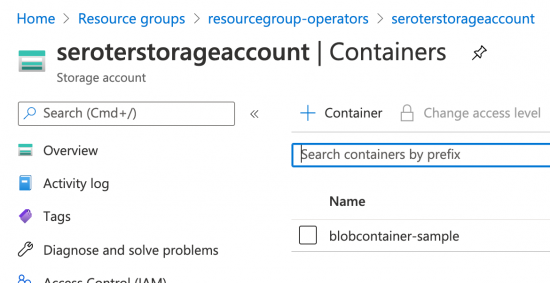
Switching over to the Azure Portal, I navigated to Storage area and saw my new account and blob container.
How cool is that? Now i just have to drop resource definitions into my GitHub repository, and Anthos spins up the service in GCP or Azure. And if I delete that resource manually, Anthos re-creates it automatically. I don’t have to learn each API or manage code that provisions services.
Finally, we can also deploy applications this way. Imagine using a CI pipeline to populate a Kubernetes deployment template (using kpt, or something else) and dropping it into a git repo. Then, we use the Kubernetes resource model to deploy the application container. In the gcp-apps directory, I added Kubernetes deployment and service YAML files that reference a basic app I containerized.

As you might expect, once the repo synced to the correct clusters, Anthos created a deployment and service that resulted in a routable endpoint. While there are tradeoffs for deploying apps this way, there are some compelling benefits.

Step 6: “Move” App Between Clouds by Moving Configs in GitHub
This last step is basically my way of trolling the people who complain that multi-cloud apps are hard. What if I want to take the above app from GCP and move it to Azure? Does it require a four week consulting project and sacrificing a chicken? No. I just have to copy the Kubernetes deploy and service YAML files to the azure-apps directory.

After committing my changes to GitHub, ACM fired up and deleted the app from GCP, and inflated it on Azure, including an Azure Load Balancer instance to get a routable endpoint. I can see all of that from within the GCP Console.

Now, in real life, apps aren’t so easily portable. There are probably sticky connections to databases, and other services. But if you have this sort of platform in place, it’s definitely easier.
Thanks to deep support for GitOps and the KRM, Anthos makes it possible to manage infrastructure, apps, and managed services in a consistent way, on any cloud. Whether you use Anthos or not, take a look at GitOps and the KRM and start asking your preferred vendors when they’re going to adopt this paradigm!

Leave a reply to Rinkesh Cancel reply