My favorite definition of “serverless computing” still comes from Rachel Stephens at RedMonk: managed services that scale to zero. There’s a lot packed into that statement. It elevates consumption-based pricing, and a bias towards managed services, not raw infrastructure. That said, do today’s mainstream serverless technologies represent a durable stack for the next decade? I’m not sure. It feels like there’s still plenty of tradeoffs and complexity. I especially feel this way after spending time with Dark.
If you build apps by writing code, you’re doing a lot of setup and wiring. Before writing code, you figure out tech choices, spin up dependent services (databases, etc), get your CI/CD pipeline figured out, and decide out how to stitch it all together. Whether you’re building on-premises or off, it’s generally the same. Look at a typical serverless stack from AWS. it’s made up of AWS Lambda or Fargate, Amazon S3, Amazon DynamoDB, Amazon Cognito, Amazon API Gateway, Amazon SQS or Kinesis, Amazon CloudWatch, AWS X-Ray and more. All managed services, but still a lot to figure out and pre-provision. To be fair, frameworks like AWS Amplify or Google’s Firebase pull things together better than pure DIY. Regardless, it might be serverless, but it’s not setup-less or maintain-less.
Dark seems different. It’s a complete system—language, editor, runtime, and infrastructure. You spend roughly 100% of your time building the app. It’s a deploy-less model where your code changes are instantly deployed behind the scenes. It’s setup-less as you don’t create databases, message brokers, API gateways, or compute hosts. Everything is interconnected. Some of this sounds reminiscent of low-code platforms like Salesforce, Microsoft PowerApps, or OutSystems. But Dark still targets professional programmers, I think, so it’s a different paradigm.
In this post, I’ll build a simple app with Dark. As we go along, I’ll explain some of the interesting aspects of the platform. This app serves up a couple REST endpoints, stores data in database, and uses a background worker to “process” incoming orders.

Step 0: Understand Dark Language and Components
With Dark, you’re coding in their language. They describe it as “statically-typed functional/imperative hybrid, based loosely on ML. It is a high-level language, with immutable values, garbage collection, and support for generics/polymorphic types.” It offers the standard types (e.g. Strings, Integers, Booleans, Lists, Dictionaries), and doesn’t really support custom objects.
The Dark team also describes their language as “expression-oriented.” You basically build up expressions. You use (immutable) variables, conditional statements, and pipelining to accomplish your objectives. We’ll see a few examples of this below.
There are five (kinda, six) components that make up a Dark app. These “handlers” sit on your “canvas” and hold all your code. These components are:
- HTTP endpoints. These are for creating application entry points via the major HTTP verbs.
- Cron jobs. These are tasks that run on whatever schedule you set.
- Background Workers. They receive events, run asynchronously, and support automatic retries.
- Persistent Datastores. This is a key-value store.
- REPL. These are developer tools you create to run commands outside of your core components.
All of these components are first-class in the Dark language itself. I can write Dark code that inherently knows what to do with all the above things.
The other component that’s available is a “Function” which is just that. It’s an extracted command that you can call from your other components.
Ok, we know the basics. Let’s get to work.
Step 1: Create a Datastore
I need to store state. Almost every system does. Whether your compute nodes store it locally, or you pull it from an attached backing store, you have to factor in provisioning, connecting to, and maintaining it. Not with Dark.
First, let’s look at the canvas. Here, I add and position the components that make up my app. Each user (or app) gets its own canvas.

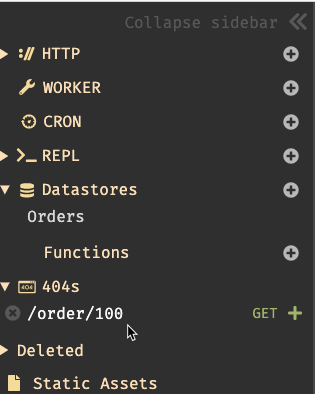
I need a database. To create it, I just click the “plus” next to the Datastores item in the left sidebar, or click on the canvas and choose New DB.
I named mine “Orders” and proceeded to define a handful of fields and corresponding data types. That’s it. I didn’t pick an instance size, throughput units, partition IDs, or replication factors.

I can also test out my database by adding a REPL to my canvas, and writing some quick code to inject a record in the database. A button in the REPL lights up and when I click it, it runs whatever code is there. I can then see the record in the database, and add a second REPL to purge the database.

Step 2: Code the REST endpoints
Let’s add some data to this database, via a REST API.
I could click the “plus” button next to the HTTP component in the sidebar, or click the canvas. A better way of doing this is via the Trace-Based Development model in Dark. Specifically, I can issue a request to a non-existent endpoint, Dark will capture that, and I can build up a handler based on it. Reminds me a bit of consumer-driven contract testing where you’re building based on what the client needs.
So, I go to Postman and submit an HTTP POST request to a URL that references my canvas, but the path doesn’t exist (yet). I’m also sending in the shape of the JSON payload that I want my app to handle.

Back in Dark, I see a new entry under “404s.”

When I click the “plus” sign next to it, I get a new HTTP handler on my canvas. Not only that, the handler is pre-configured to handle POST requests to the URL I specified, and, shows me the raw trace of the 404 request.
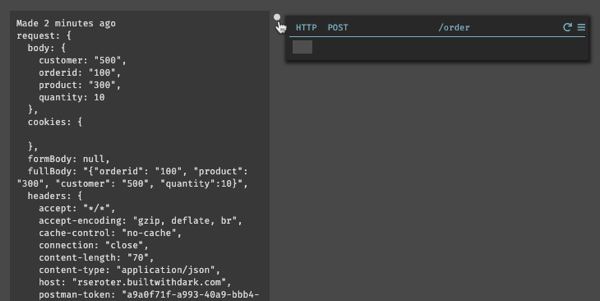
What’s kinda crazy is that I can choose this trace (or others) and replay them through the component. This is a powerful way to first create the stub, and then run that request through the component after writing the handler code.
So let’s write the code. All I want to do is create a record in the database with the data from the HTTP request. If the fields map 1:1, you can just dump it right in there. I chose to more explicitly map it, and set some DB values that didn’t exist in the JSON payload.
As I start typing my code in, I’m really just filling in the expressions, and choosing from the type-ahead values. Also notice that each expression resolves immediately and shows you the result of that expression on the left side.

My code itself is fairly simple. I use the built-in operators to set a new database record, and return a simple JSON acknowledgement to the caller.

That’s it. Dark recognized that this handler is now using the Orders database, and shows a ghostly connection visualization. When I click the “replay” button on my HTTP handler, it runs my code against the selected trace, and sure enough, a record shows up in the database.

I want a second API endpoint to retrieve a specific order from the system. So, I go back to Postman, and issue another HTTP request to the URL that I want the system to give me.

As expected, I have another trace to leverage when inflating my HTTP handler.
For this handler, I changed the handler’s URL to tokenize the request (and get the “orderid” as a variable), and added some simple code to retrieve a record from the database using that order ID.

That’s all. I now have two REST endpoints that work together to create and retrieve data from a persistent datastore. At no point was I creating containers, deployment pipelines, or switching to logging dashboards. It’s all in one place, as one experience.
Step 3: Build a Worker
The final step is to build a worker. This component receives an event and does some work. In my case, I want it to receive new orders, and change the order status to “processing.”
Once again, I can trigger creation of a worker by “calling” it before it exists. Back in my HTTP post handler, I’m adding the reserved emit command. This is how you send events to a background worker. In this case, I specify the payload, and the name of the yet-to-be-created worker. Then I replay that specific command against the latest trace, and see a new 404 for the worker request.

In my Dark code, I overwrite the existing record with a new one, and set the OrderStatus value. By replaying the trace, I can see the inbound payload (left) and resulting database update (bottom).
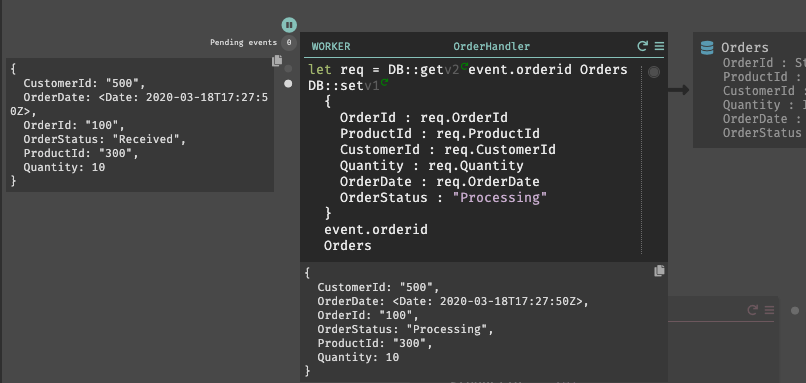
At this point, my app is done. I can POST new orders, and almost immediately see the changed “status” because the workers run so fast.
Dark won’t be a fit for many apps and architectures. That said, if my app has me debating between integrating a dozen individual serverless services from a cloud provider, or Dark, I’m choosing Dark.

Leave a comment