This week, Confluent announced that there’s now a free trial for their Confluent Cloud. If you’re unfamiliar with either, Confluent is the company founded by the creators of Apache Kafka, and Confluent Cloud is their managed Kafka offering that runs on every major public cloud. There are various ways to kind-of use Kafka in the public cloud (e.g. Amazon Managed Streaming for Apache Kafka, Azure Event Hubs with Kafka interface), but what Confluent offers is the single, best way to use the full suite of Apache Kafka capabilities as a managed service. It’s now free to try out, so I figured I’d take it for a spin.
First, I went to the Confluent Cloud site and clicked the “try free” button. I was prompted to create an account.
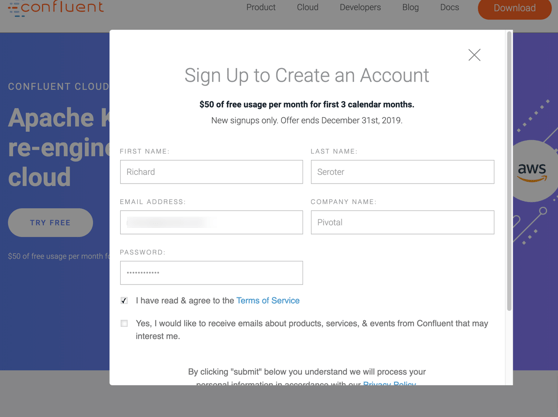
I was asked for credit card info to account for overages above the free tier (and after the free credits expire in 3 months), which I provided. With that, I was in.
First, I was prompted to create a cluster. I do what I’m told.
Here, I was asked to provide a cluster name, and choose a public cloud provider. For each cloud, I was shown a set of available regions. Helpfully, the right side also showed me the prices, limits, billing cycle, and SLA. Transparency, FTW!

While that was spinning up, I followed the instructions to install the Confluent Cloud CLI so that I could also geek-out at the command line. I like the the example CLI commands in the docs actually reflect the values of my environment (e.g. cluster name). Nice touch.
Within maybe a minute, my Kafka cluster was running. That’s pretty awesome. I chose to create a new topic with 6 partitions. I’m able to choose up to 60 partitions for a topic, and define other settings like data retention period, max size on disk, and cleanup policy.

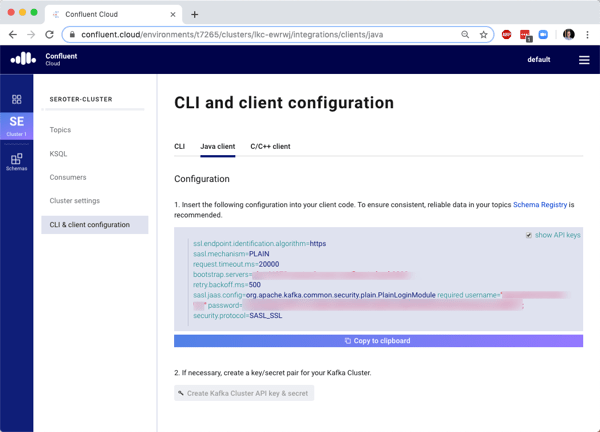
Before building an app to publish data to Confluent Cloud, I needed an API key and secret. I could create this via the CLI, or the dashboard. I generated the key via the dashboard, saved it (since I can’t see it again after generating), and saw the example Java client configuration updated with those values. Handy, especially because I’m going to talk to Kafka via Spring Cloud Stream!
Now I needed an app that would send messages to Apache Kafka in the Confluent Cloud. I chose Spring Boot because I make good decisions. Thanks to the Spring Cloud Stream project, it’s super-easy to interact with Apache Kafka without having to be an expert in the tech itself. I went to start.spring.io to generate a project. If you click this link, you can download an identical project configuration.
I opened up this project and added the minimum code and configuration necessary to gab with Apache Kafka in Confluent Cloud. I wanted to be able to submit an HTTP request and see that message published out. That required one annotation to create a REST controller, and one annotation to indicate that this app is a source to the stream. I then have a “Source” variable is autowired, which means it’s inflated by Spring Boot at runtime. Finally, I have a single operation that responds to an HTTP post command and writes the payload to the message stream. That’s it!
package com.seroter.confluentboot;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.cloud.stream.annotation.EnableBinding;
import org.springframework.cloud.stream.messaging.Source;
import org.springframework.messaging.support.GenericMessage;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@EnableBinding(Source.class)
@RestController
@SpringBootApplication
public class ConfluentBootApplication {
public static void main(String[] args) {
SpringApplication.run(ConfluentBootApplication.class, args);
}
@Autowired
private Source source;
@PostMapping("/messages")
public String postMsg(@RequestBody String msg) {
this.source.output().send(new GenericMessage<>(msg));
return "success";
}
}
The final piece? The application configuration. In the application.properties file, I set the handful of parameters, mostly around the target cluster, topic name, and credentials.
spring.cloud.stream.kafka.binder.brokers=pkc-41973.westus2.azure.confluent.cloud:9092
spring.cloud.stream.bindings.output.destination=seroter-topic
spring.cloud.stream.kafka.binder.configuration.sasl.jaas.config=org.apache.kafka.common.security.plain.PlainLoginModule required username="[KEY]" password="[SECRET]";
spring.cloud.stream.kafka.binder.configuration.sasl.mechanism=PLAIN
spring.cloud.stream.kafka.binder.configuration.security.protocol=SASL_SSL
I started up the app, confirmed that it connected (via application logs), and opened Postman to issue an HTTP POST command.

After switching back to the Confluent Cloud dashboard, I saw my messages pop up.

You can probably repeat this whole demo in about 10 minutes. As you can imagine, there’s a LOT more you can do with Apache Kafka than what I showed you. If you want an environment to learn Apache Kafka in depth, it’s now a no-brainer to spin up a free account in Confluent Cloud. And if you want to use a legit managed Apache Kafka for production in any cloud, this seems like a good bet as well.

Leave a comment