What do you think of when you hear the phrase “multi-cloud”? Ok, besides stupid marketing people and their dumb words. You might think of companies with on-premises environments who are moving some workloads into a public cloud. Or those who organically use a few different clouds, picking the best one for each workload. While many suggest that you get the best value by putting everything on one provider, that clearly isn’t happening yet. And maybe it shouldn’t. Who knows. But can you get the best of each cloud while retaining some portability? I think you can.
One multi-cloud solution is to do the lowest-common-denominator thing. I really don’t like that. Multi-cloud management tools try to standardize cloud infrastructure but always leave me disappointed. And avoiding each cloud’s novel services in the name of portability is unsatisfying and leaves you at a competitive disadvantage. But why should we choose the cloud (Azure! AWS! GCP!) and runtime (Kubernetes! VMs!) before we’ve even written a line of code? Can’t we make those into boring implementation details, and return our focus to writing great software? I’d propose that with good app frameworks, and increasingly-standard interfaces, you can create great software that runs on any cloud, while still using their novel services.
In this post, I’ll build a RESTful API with Spring Boot and deploy it, without code changes, to four different environments, including:
- Local environment running MongoDB software in a Docker container.
- Microsoft Azure Cosmos DB with MongoDB interface.
- Amazon DocumentDB with MongoDB interface.
- MongoDB Enterprise running as a service within Pivotal Cloud Foundry
Side note: Ok, so multi-cloud sounds good, but it seems like a nightmare of ops headaches and nonstop dev training. That’s true, it sure can be. But if you use a good multi-cloud app platform like Pivotal Cloud Foundry, it honestly makes the dev and ops experience virtually the same everywhere. So, it doesn’t HAVE to suck, although there are still going to be challenges. Ideally, your choice of cloud is a deploy-time decision, not a design-time constraint.
Creating the app
In my career, I’ve coded (poorly) with .NET, Node, and Java, and I can say that Spring Boot is the fastest way I’ve seen to build production-quality apps. So, I chose Spring Boot to build my RESTful API. This API stores and returns information about cloud databases. HOW VERY META. I chose MongoDB as my backend database, and used the amazing Spring Data to simplify interactions with the data source.
From start.spring.io, I created a project with dependencies on spring-boot-starter-data-rest (auto-generated REST endpoints for interacting with databases), spring-boot-starter-data-mongodb (to talk to MongoDB), spring-boot-starter-actuator (for “free” health metrics), and spring-cloud-cloudfoundry-connector (to pull connection details from the Cloud Foundry environment). Then I opened the project and created a new Java class representing a CloudProvider.
package seroter.demo.cloudmongodb;
import org.springframework.data.annotation.Id;
public class CloudProvider {
@Id private String id;
private String providerName;
private Integer numberOfDatabases;
private Boolean mongoAsService;
public String getProviderName() {
return providerName;
}
public void setProviderName(String providerName) {
this.providerName = providerName;
}
public Integer getNumberOfDatabases() {
return numberOfDatabases;
}
public void setNumberOfDatabases(Integer numberOfDatabases) {
this.numberOfDatabases = numberOfDatabases;
}
public Boolean getMongoAsService() {
return mongoAsService;
}
public void setMongoAsService(Boolean mongoAsService) {
this.mongoAsService = mongoAsService;
}
}Thanks to Spring Data REST (which is silly powerful), all that was left was to define a repository interface. If all I did was create an annotate the interface, I’d get full CRUD interactions with my MongoDB collection. But for fun, I also added an operation that would return all the clouds that did (or did not) offer a MongoDB service.
package seroter.demo.cloudmongodb;
import java.util.List;
import org.springframework.data.mongodb.repository.MongoRepository;
import org.springframework.data.rest.core.annotation.RepositoryRestResource;
@RepositoryRestResource(collectionResourceRel = "clouds", path = "clouds")
public interface CloudProviderRepository extends MongoRepository<CloudProvider, String> {
//add an operation to search for a specific condition
List<CloudProvider> findByMongoAsService(Boolean mongoAsService);
}That’s literally all my code. Crazy.
Run using Dockerized MongoDB
To start this test, I wanted to use “real” MongoDB software. So I pulled the popular Docker image and started it up on my local machine:
docker run -d -p 27017:27017 --name serotermongo mongo
When starting up my Spring Boot app, I could provide database connection info (1) in an app.properties file, or, as (2) input parameters that require nothing in the compiled code package itself. I chose the file option for readability and demo purposes, which looked like this:
#local configuration
spring.data.mongodb.uri=mongodb://0.0.0.0:27017
spring.data.mongodb.database=demodb
#port configuration
server.port=${PORT:8080}After starting the app, I issued a base request to my API via Postman. Sure enough, I got a response. As expected, no data in my MongoDB database. Note that Spring Data automatically creates a database if it doesn’t find the one specified, so the “demodb” now existed.

I then issued a POST command to add a record to MongoDB, and that worked great too. I got back the URI for the new record in the response.

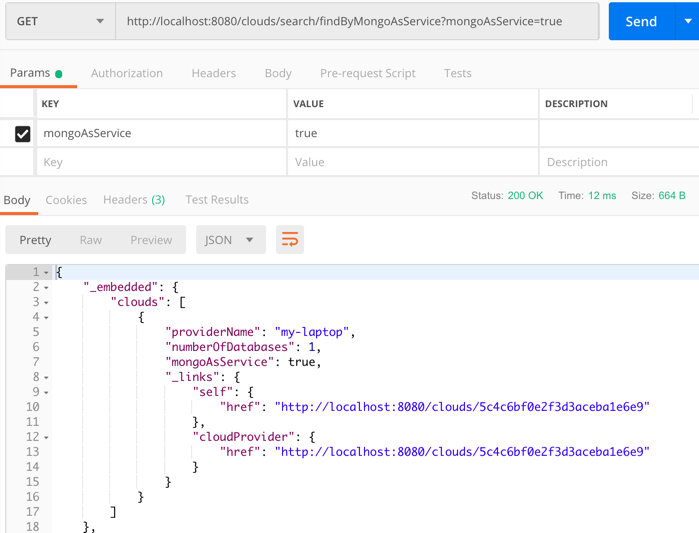
I also tried calling that custom “search” interface to filter the documents where “mongoAsService” is true. That worked.
So, running my Spring Boot REST API with a local MongoDB worked fine.
Run using Microsoft Azure Cosmos DB
Next up, I pointed this application to Microsoft Azure. One of the many databases in Azure is Cosmos DB. This underrated database offers some pretty amazing performance and scale, and is only available from Microsoft in their cloud. NO PROBLEM. It serves up a handful of standard interfaces, including Cassandra and MongoDB. So I can take advantage of all the crazy-great hosting features, but not lock myself into any of them.
I started by visiting the Microsoft Azure portal. I chose to create a new Cosmos DB instance, and selected which API (SQL, Cassandra, Gremlin, MongoDB) I wanted.
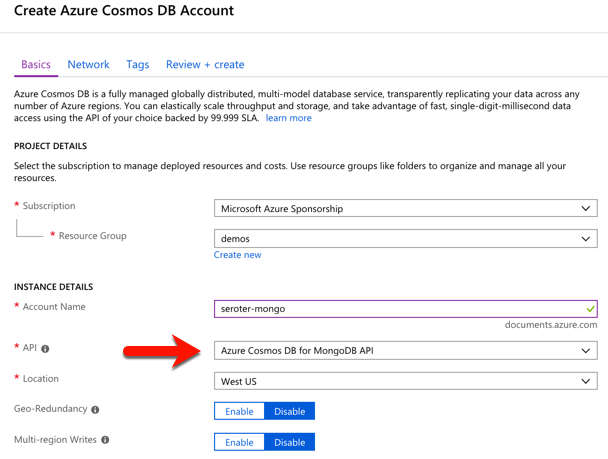
After a few minutes, I had an instance of Cosmos DB. If I had wanted to, I could have created a database and collection from the Azure portal, but I wanted to confirm that Spring Data would do it for me automatically.
I located the “Connection String” properties for my new instance, and grabbed the primary one.
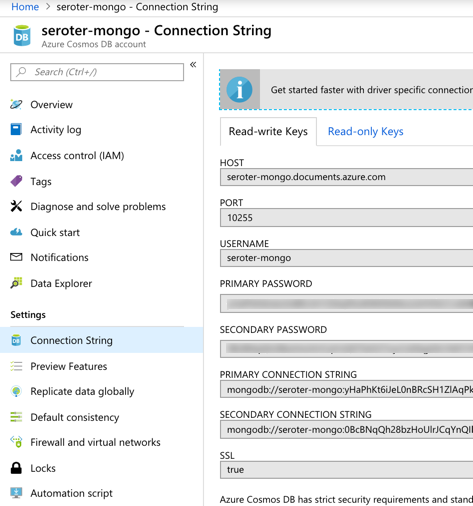
With that in hand, I went back to my application.properties file, commented out my “local” configuration, and added entries for the Azure instance.
#local configuration
#spring.data.mongodb.uri=mongodb://0.0.0.0:27017
#spring.data.mongodb.database=demodb
#port configuration
server.port=${PORT:8080}
#azure cosmos db configuration
spring.data.mongodb.uri=mongodb://seroter-mongo:<password>@seroter-mongo.documents.azure.com:10255/?ssl=true&replicaSet=globaldb
spring.data.mongodb.database=demodbI could publish this app to Azure, but because it’s also easy to test it locally, I just started up my Spring Boot REST API again, and pinged the database. After POSTing a new record to my endpoint, I checked the Azure portal and sure enough, saw a new database and collection with my “document” in it.
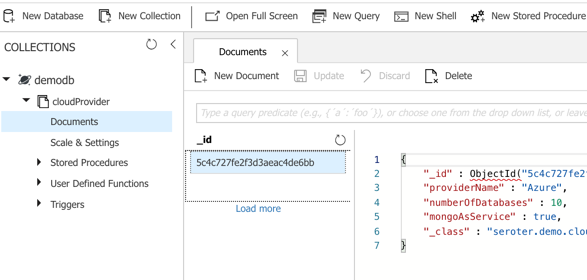
Here, I’m using a super-unique cloud database but don’t need to manage my own software to remain “portable”, thanks to Spring Boot and MongoDB interfaces. Wicked.
Run using Amazon DocumentDB
Amazon DocumentDB is the new kid in town. I wrote up an InfoQ story about it, which frankly inspired me to try all this out.
Like Azure Cosmos DB, this database isn’t running MongoDB software, but offers a MongoDB-compatible interface. It also offers some impressive scale and performance capabilities, and could be a good choice if you’re an AWS customer.
For me, trying this out was a bit of a chore. Why? Mainly because the database service is only accessible from within an AWS private network. So, I had to properly set up a Virtual Private Cloud (VPC) network and get my Spring Boot app deployed there to test out the database. Not rocket science, but something I hadn’t done in a while. Let me lay out the steps here.
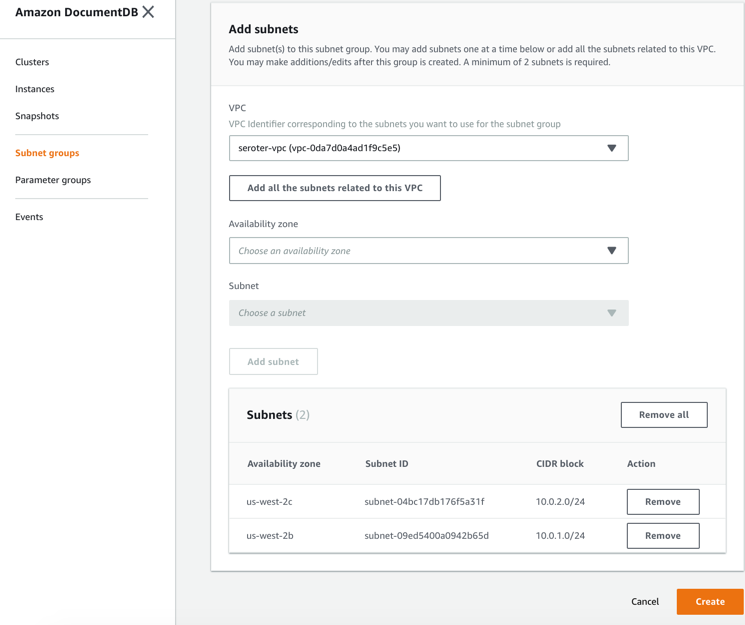
First, I created a new VPC. It had a single public subnet, and I added two more private ones. This gave me three total subnets, each in a different availability zone.

Next, I switched to the DocumentDB console in the AWS portal. First, I created a new subnet group. Each DocumentDB cluster is spread across AZs for high availability. This subnet group contains both the private subnets in my VPC.
I also created a parameter group. This group turned off the requirement for clients to use TLS. I didn’t want my app to deal with certs, and also wanted to mess with this capability in DocumentDB.
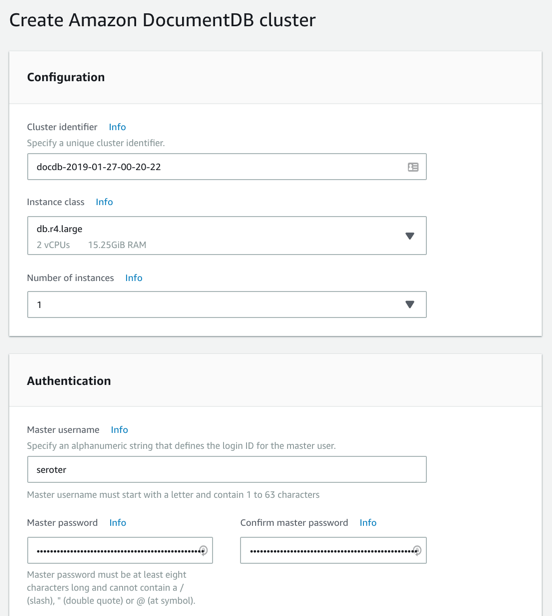
Next, I created my DocumentDB cluster. I chose an instance class to match my compute and memory needs. Then I chose a single instance cluster; I could have chosen up to 16 instances of primaries and replicas.
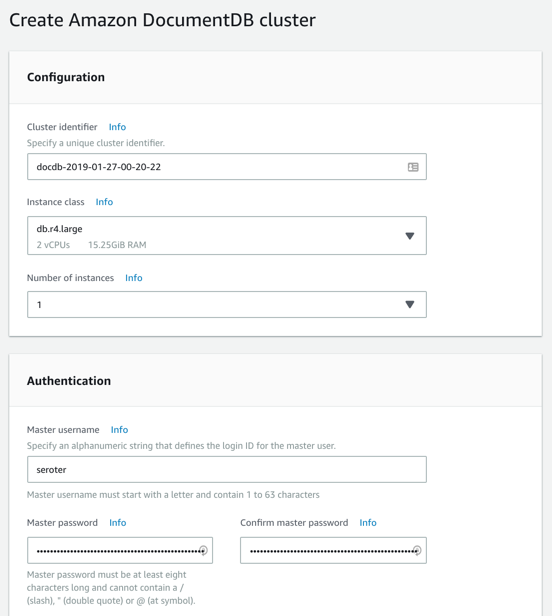
I also chose my pre-configured VPC and the DocumentDB subnet group I created earlier. Finally, I set my parameter group, and left default values for features like encryption and database backups.

After a few minutes, my cluster and instance were up and running. While this console doesn’t expose the ability to create databases or browse data, it does show me health metrics and cluster configuration details.

Next, I took the connection string for the cluster, and updated my application.properties file.
#local configuration
#spring.data.mongodb.uri=mongodb://0.0.0.0:27017
#spring.data.mongodb.database=demodb
#port configuration
server.port=${PORT:8080}
#azure cosmos db configuration
#spring.data.mongodb.uri=mongodb://seroter-mongo:<password>@seroter-mongo.documents.azure.com:10255/?ssl=true&replicaSet=globaldb
#spring.data.mongodb.database=demodb
#aws documentdb configuration
spring.data.mongodb.uri=mongodb://seroter:<password>@docdb-2019-01-27-00-20-22.cluster-cmywqx08yuio.us-west-2.docdb.amazonaws.com:27017
spring.data.mongodb.database=demodbNow to deploy the app to AWS. I chose Elastic Beanstalk as the application host. I selected Java as my platform, and uploaded the JAR file associated with my Spring Boot REST API.

I had to set a few more parameters for this app to work correctly. First, I set a SERVER_PORT environment variable to 5000, because that’s what Beanstalk expects. Next, I ensured that my app was added to my VPC, provisioned a public IP address, and chose to host on the public subnet. Finally, I set the security group to the default one for my VPC. All of this should ensure that my app is on the right network with the right access to DocumentDB.
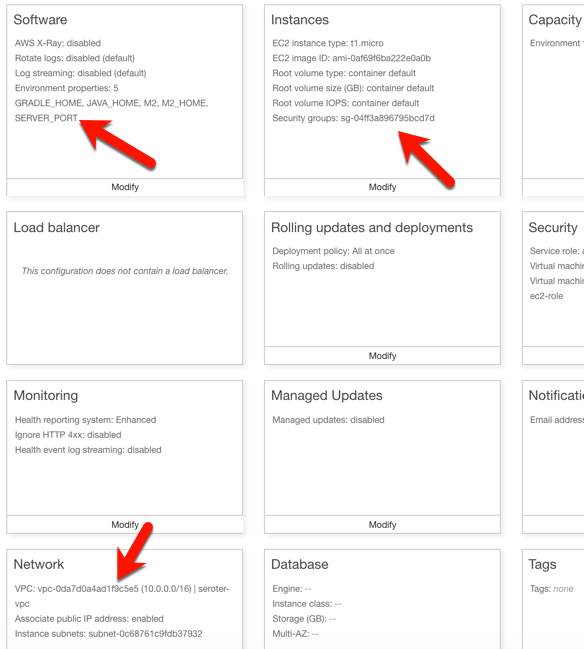
After the app was created in Beanstalk, I queried the endpoint of my REST API. Then I created a new document, and yup, it was added successfully.

So again, I used a novel, interesting cloud-only database, but didn’t have to change a lick of code.
Run using MongoDB in Pivotal Cloud Foundry
The last place to try this app out? A multi-cloud platform like PCF. If you did use something like PCF, the compute layer is consistent regardless of what public/private cloud you use, and connectivity to data services is through a Service Broker. In this case, MongoDB clusters are managed by PCF, and I get my own cluster via a Broker. Then my apps “bind” to that cluster.
First up, provisioning MongoDB. PCF offers MongoDB Enterprise from Mongo themselves. To a developer, this looks like a database-as–a-service because clusters are provisioned, optimized, backed up, and upgraded via automation. Via the command line or portal, I could provision clusters. I used the portal to get myself happy little instance.

After giving the service a name, I was set. As with all the other examples, no code changes were needed. I actually removed any MongoDB-related connection info from my application.properties file because that spring-cloud-cloudfoundry-connector dependency actually grabs the credentials from the environment variables set by the service broker.
One thing I *did* create for this environment — which is entirely optional — is a Cloud Foundry manifest file. I could pass these values into a command line instead of creating a declarative file, but I like writing them out. These properties simply tell Cloud Foundry what to do with my app.
---
applications:
- name: boot-seroter-mongo
memory: 1G
instances: 1
path: target/cloudmongodb-0.0.1-SNAPSHOT.jar
services:
- seroter-mongoWith that, I jumped to a terminal, navigated to a directory holding that manifest file, and typed cf push. About 25 seconds later, I had a containerized, reachable application that connected to my MongoDB instance.

Fortunately, PCF treats Spring Boot apps special, so it used the Spring Boot Actuator to pull health metrics and more. Above, you can see that for each instance, I saw extra health information for my app, and, MongoDB itself.
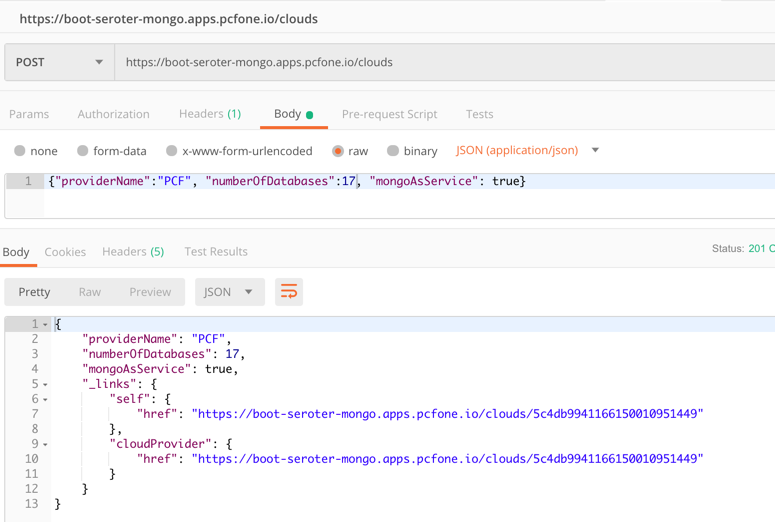
Once again, I sent some GET requests into my endpoint, saw the expected data, did a POST to create a new document, and saw that succeed.
Wrap Up
Now, obviously there are novel cloud services without “standard” interfaces like the MongoDB API. Some of these services are IoT, mobile, or messaging related —although Azure Event Hubs has a Kafka interface now, and Spring Cloud Stream keeps message broker details out of the code. Other unique cloud services are in emerging areas like AI/ML where standardization doesn’t really exist yet. So some applications will have a hard coupling to a particular cloud, and of course that’s fine. But increasingly, where you run, how you run, and what you connect to, doesn’t have to be something you choose up front. Instead, first you build great software. Then, you choose a cloud. And that’s pretty cool.

Leave a comment