
Trust. Without trust, AI coding assistants won’t become a default tool in a developer’s toolbox. Trust is the #1 concern of devs today, and it’s something I’ve struggled with in regards to getting the most relevant answers from an LLM. Specifically, am I getting back the latest information? Probably not, given that LLMs have a training cutoff date. Your AI coding assistant probably doesn’t (yet) know about Python 3.13, the most recent features of your favorite cloud service, or the newest architectural idea shared at a conference last week. What can you do about that?
To me, this challenge comes up in at least three circumstances. There are entirely new concepts or tools that the LLM training wouldn’t know about. Think something like pipe syntax as an alternative to SQL syntax. I wouldn’t expect a model trained last year to know about that. How about updated features to existing libraries or frameworks? I want suggestions that reflect the full feature set of the current technology and I don’t want to accidentally do something the hard (old) way. An example? Consider the new “enum type” structured output I can get from LangChain4J. I’d want to use that now! And finally, I think about improved or replicated framework libraries. If I’m upgrading from Java 8 to Java 23, or Deno 1 to Deno 2, I want to ensure I’m not using deprecated features. My AI tools probably don’t know about any of these.
I see four options for trusting the freshness of responses from your AI assistant. The final technique was brand new to me, and I think it’s excellent.
- Fine-tune your model
- Use retrieval augmented generation (RAG)
- Ground the results with trusted sources
- “Train” on the fly with input context
Let’s briefly look at the first three, and see some detailed examples of the fourth.
Fine-tune your model
Whether using commercial or open models, they all represent a point-in-time based on their training period. You could choose to repeatedly train your preferred model with fresh info about the programming languages, frameworks, services, and patterns you care about.
The upside? You can get a model with knowledge about whatever you need to trust it. The downside? It’s a lot of work—you’d need to craft a healthy number of examples and must regularly tune the model. That could be expensive, and the result wouldn’t naturally plug into most AI coding assistance tools. You’d have to jump out of your preferred coding tool to ask questions of a model elsewhere.
Use RAG
Instead of tuning a serving a custom model, you could choose to augment the input with pre-processed content. You’ll get back better, more contextual results when taking into account data that reflects the ideal state.
The upside? You’ll find this pattern increasingly supported in commercial AI assistants. This keeps you in your flow without having to jump out to another interface. GitHub Copilot offers this, and now our Gemini Code Assist provides code customization based on repos in GitHub or GitLab. With Code Assist, we handle the creation and management of the code index of your repos, and you don’t have to manually chunk and store your code. The downside? This only works well if you’ve got the most up-to-date data in an indexed source repo. If you’ve got old code or patterns in there, that won’t help your freshness problem. And while these solutions are good for extra code context, they may not support a wider range of possible context sources (e.g. text files).
Ground the results
This approach gives you more confidence that the results are accurate. For example, Google Cloud’s Vertex AI offers “ground with Google Search” so that responses are matched to real, live Google Search results.

If I ask a question about upgrading an old bit of Deno code, you can see that the results are now annotated with reference points. This gives me confidence to some extent, but doesn’t necessarily guarantee that I’m getting the freshest answers. Also, this is outside of my preferred tool, so it again takes me out of a flow state.
Train on the fly
Here’s the approach I just learned about from my boss’s boss, Keith Ballinger. I complained about freshness of results from AI assistance tools, and he said “why don’t you just train it on the fly?” Specifically, pass the latest and greatest reference data into a request within the AI assistance tool. Mind … blown.
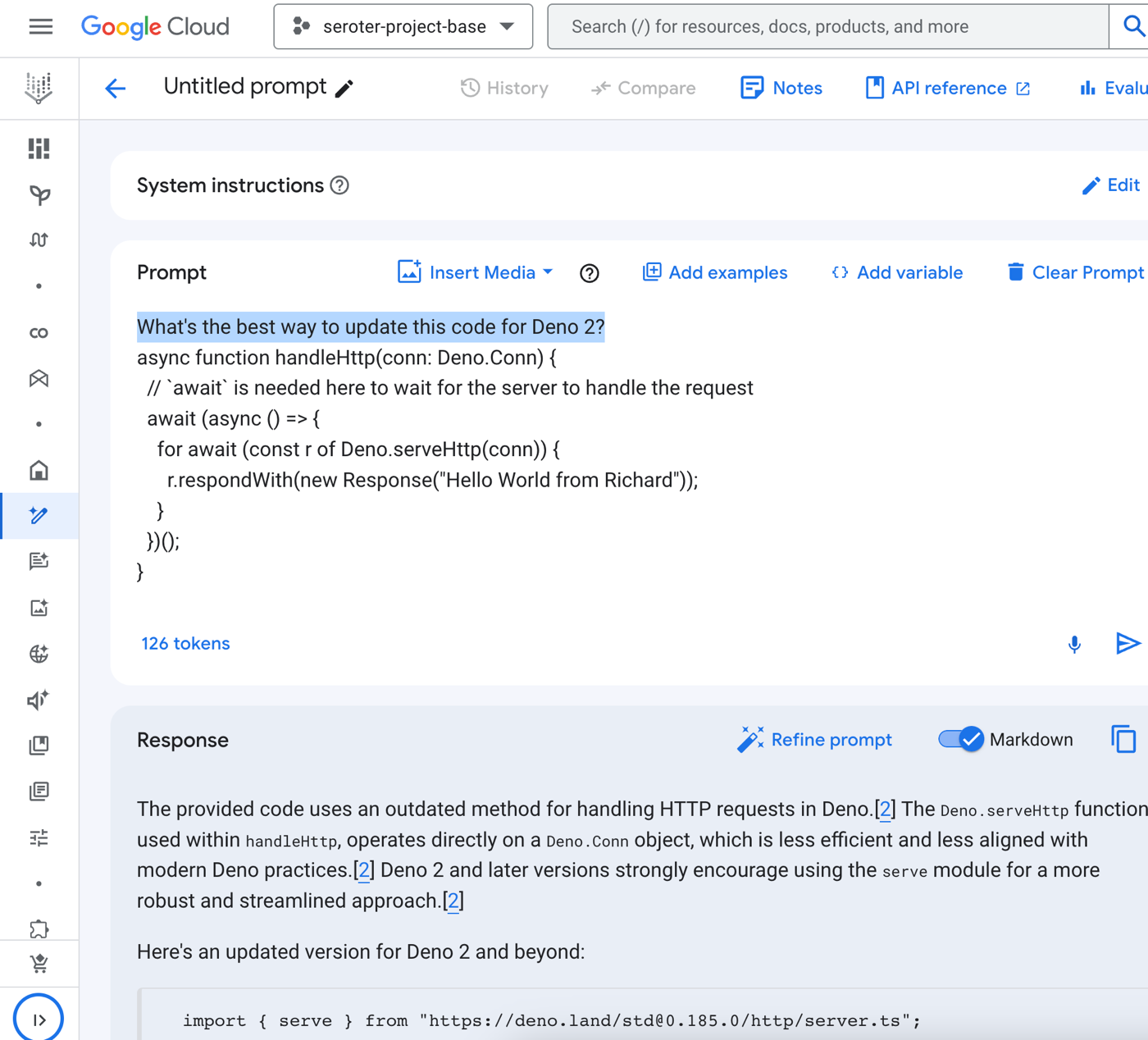
How might it handle entirely new concepts or tools? Let’s use that pipe syntax example. In my code, I want to use this fresh syntax instead of classic SQL. But there’s no way my Gemini Code Assist environment knows about that (yet). Sure enough, I just get back a regular SQL statement.
But now, Gemini Code Assist supports local codebase awareness, up to 128,000 input tokens! I grabbed the docs for pipe query syntax, saved as a PDF, and then asked Google AI Studio to produce a Markdown file of the docs. Note that Gemini Code Assist isn’t (yet) multi-modal, so I need Markdown instead of passing in a PDF or image. I then put a copy of that Markdown file in a “training” folder within my app project. I used the new @ mention feature in our Gemini Code Assist chat to specifically reference the syntax file when asking my question again.

Wow! So by giving Gemini Code Assist a reference file of pipe syntax, it was able to give me an accurate, contextual, and fresh answer.
What about updated features to existing libraries or frameworks? I mentioned the new feature of LangChain4J for the Gemini model. There’s no way I’d expect my coding assistant to know about a feature added a few days ago. Once again, I grabbed some resources. This time, I snagged the Markdown doc for Google Vertex AI Gemini from the LangChain4J repo, and converted a blog post from Guillaume to Markdown using Google AI Studio.
My prompt to the Gemini Code Assist model was “Update the service function with a call to Gemini 1.5 Flash using LangChain4J. It takes in a question about a sport, and the response is mapped to an enum with values for baseball, football, cricket, or other.” As expected, the first response was a good attempt, but it wasn’t fully accurate. And it used a manual way to map the response to an enum.
What if I pass in both of those training files with my prompt? I get back exactly the syntax I wanted for my Cloud Run Function!

So great. This approach requires me to know what tech I’m interested in up front, but still, what an improvement!
Final example. How about improved or replicated framework libraries? Let’s say I’ve got a very old Deno app that I created when I first got excited about this excellent JavaScript runtime.
// from https://deno.com/blog/v1.35#denoserve-is-now-stable
async function handleHttp(conn: Deno.Conn) {
// `await` is needed here to wait for the server to handle the request
await (async () => {
for await (const r of Deno.serveHttp(conn)) {
r.respondWith(new Response("Hello World from Richard"));
}
})();
}
for await (const conn of Deno.listen({ port: 8000 })) {
handleHttp(conn);
}
This code uses some libraries and practices that are now out of date. When I modernize this app, I want to trust that I’m doing it the best way. Nothing to fear! I grabbed the Deno 1.x to 2.x migration guide, a blog post about the new approach to web servers, and the launch blog for Deno 2. The result? Impressive, including a good description of why it generated the code this way.

I could imagine putting the latest reference apps into a repo and using Gemini Code Assist’s code customization feature to pull that automatically into my app. But this demonstrated technique gives me more trust in the output of tool when freshness is paramount. What do you think?

Leave a reply to Dew Drop – October 15, 2024 (#4286) – Morning Dew by Alvin Ashcraft Cancel reply