Are all serverless compute platforms—typically labeled Function-as-a-Service—the same? Sort of. They all offer scale-to-zero compute triggered by events and billed based on consumed resources. But I haven’t appreciated the nuances of these offerings, until now. Last week, Laurence Hecht did great work analyzing the latest CNCF survey data. It revealed which serverless (compute) offerings have the most usage. To be clear, this is about compute, not databases, API gateways, workflow services, queueing, or any other managed services.
To me, the software in that list falls into one of three categories: connective compute, platform expanding, and full stack apps. Depending on what you want to accomplish, one may be better than the others. Let’s look at those three categories, see which platforms fall into each one, and see an example in action.
Category 1: Connective Compute
| Trigger / Destination | Signature | Packaging | Deployment |
| Database, storage, message queue, API Gateway, CDN, Monitoring service | Handlers with specific parameters | ZIP archive, containers | Web portal, CLI, CI/CD pipelines |
The best functions are small functions that fill the gaps between managed services. This category is filled with products like AWS Lambda, Microsoft Azure Functions, Google Cloud Functions, Alibaba Cloud Functions, and more. These functions are triggered when something happens in another managed service—think of database table changes, messages reaching a queue, specific log messages hitting the monitoring system, and files uploaded to storage. With this category of serveless compute, you stitch together managed services into apps, writing as little code as possible. Little-to-none of your existing codebase transfers over, as this caters to greenfield solutions based on a cloud-first approach.
AWS Lambda is the grandaddy of them all, so let’s take a look at it.
In my example, I want to read messages from a queue. Specifically, have an AWS Lambda function read from Amazon SQS. Sounds simple enough!
You can write AWS Lambda functions in many ways. You can also deploy them in many ways. There are many frameworks that try to simplify the latter, as you would rarely deploy a single function as your “app.” Rather, a function is part of a broader collection of resources that make up your system. Those resources might be described via the AWS Serverless Application Model (SAM), where you can lay out all the functions, databases, APIs and more that should get deployed together. And you could use the AWS Serverless Application Repository to browse and deploy SAM templates created by you, or others. However you define it, you’ll deploy your function-based system via the AWS CLI, AWS console, AWS-provided CI/CD tooling, or 3rd party tools like CircleCI.
For this simple demo, I’m going to build a C#-based function and deploy it via the AWS console.
First up, I went to the AWS console and defined a new queue in SQS. I chose the “standard queue” type.

Next up, creating a new AWS Lambda function. I gave it a name, chose .NET Core 3.1 as my runtime, and created a role with basic permissions.
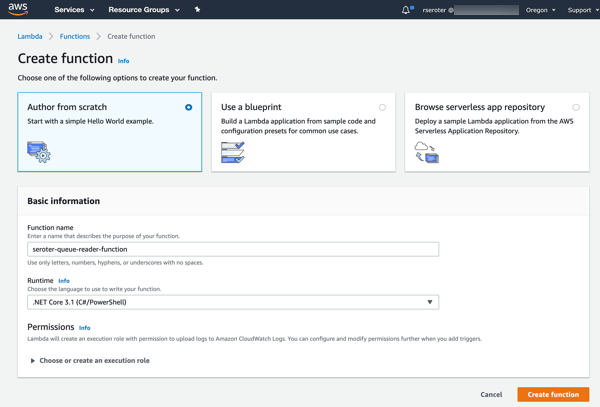
After clicking “create function”, I get a overview screen that shows the “design” of my function and provides many configuration settings.
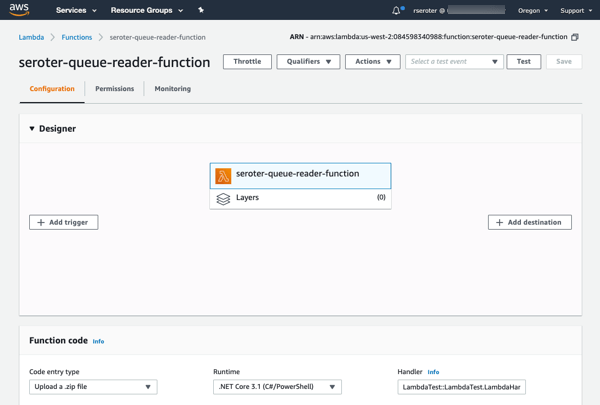
I clicked “add trigger” to specify what event kicks off my function. I’ve got lots of options to choose from, which is the hallmark of a “connective compute” function platform. I chose SQS, selected my previously-created queue from the dropdown list, and clicked “Add.”
Now all I have to do is the write the code that handles the queue message. I chose VS Code as my tool. At first, I tried using the AWS Toolkit for Visual Studio Code to generate a SAM-based project, but the only template was an API-based “hello world” one that forced me to retrofit a bunch of stuff after code generation. So, I decided to skip SAM for now, and code the AWS Lambda function directly, by itself.
The .NET team at AWS has done below-the-radar great work for years now, and their Lambda tooling is no exception. They offer a handful of handy templates you can use with the .NET CLI. One basic command installs them for you: dotnet new -i Amazon.Lambda.Templates
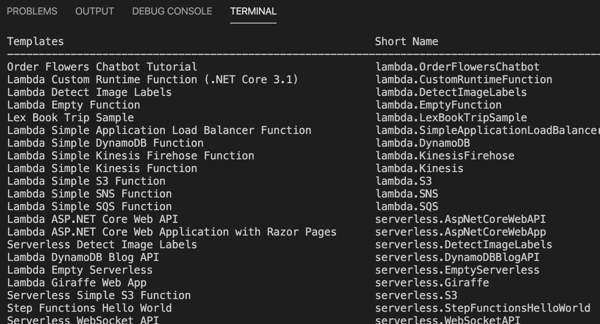
I chose to create a new project by entering dotnet new lambda.sqs. This produced a pair of projects, one with the function source code, and one that has unit tests. The primary project also has a aws-lambda-tools-default.json file that includes command line options for deploying your function. I’m not sure if I need it given I’m deploying via CLI, but I updated references to .NET Core 3.1 anyway. Note that the “function-handler” value *is* important, as we’ll need that shortly. This tells Lambda which operation (in which class) to invoke.
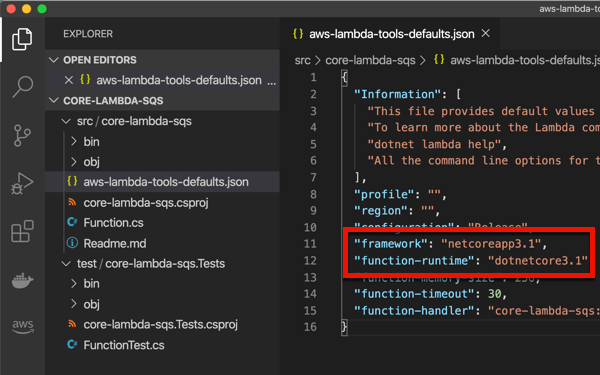
I kept the generated function code, which simply prints out the contents of the message pulled from Amazon SQS.
I successfully built the project, and then had to “publish” it to get the right assets for packaging. This publish command ensures that configuration files get bundled up as well:
dotnet publish /p:GenerateRuntimeConfigurationFiles=true
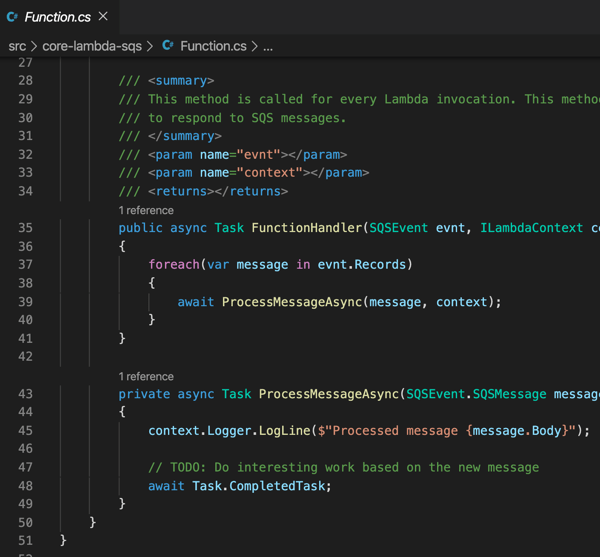
Now, all I have to do is zip up the resulting files in the “publish” directory. With those DLLs and *.json files zipped up, I return to the AWS console to upload my code. In most cases, you’re going to stash the archive file in Amazon S3 (either manually, or as the result of a CI process). Here, I uploaded my ZIP file directly, AND, set the function handler value equal to the “function-handler” value from my configuration file.
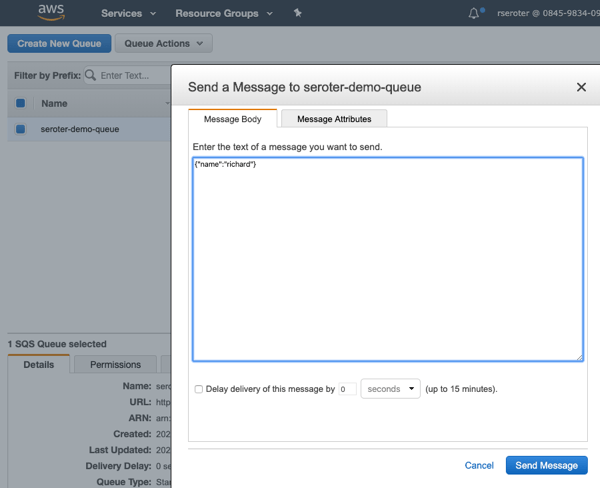
After I click “save”, I get a notice that my function was updated. I went back to Amazon SQS, and sent a few messages to the queue, using the “send a message” option.
After a moment, I saw entries in the “monitoring” view of the AWS Lambda console, and drilled into the CloudWatch logs and saw that my function wrote out the SQS payloads.

I’m impressed at how far the AWS Lambda experience has come since I first tried it out. You’ll find similarly solid experiences from Microsoft, Google and others as you use their FaaS platforms as glue code to connect managed services.
Category 2: Platform Expanding
| Trigger / Destination | Signature | Packaging | Deployment |
| HTTP | Handlers with specific parameters | code packages | Web portal, CLI |
There’s a category of FaaS that, to me, isn’t about connecting services together, as much as it’s about expanding or enriching the capabilities of a host platform. From the list above, I’d put offerings like Cloudflare Workers, Twilio Functions, and Zeit Serverless Functions into that bucket.
Most, if not all, of these start with an HTTP request and only support specific programming languages. For Twilio, you can use their integrated FaaS to serve up tokens, call outbound APIs after receiving an SMS, or even change voice calls. Zeit is an impressive host for static sites, and their functions platform supports backend operations like authentication, form submissions, and more. And Cloudflare Workers is about adding cool functionality whenever someone sends a request to a Cloudfare-managed domain. Let’s actually mess around with Cloudflare Workers.
I go to my (free) Cloudflare account to get started. You can create these running-at-the-edge functions entirely in the browser, or via the Wrangler CLI. Notice here that Workers support JavaScript, Rust, C, and C++.
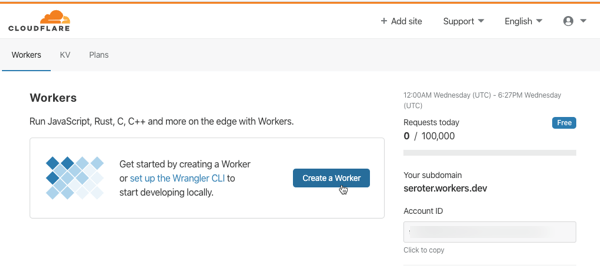
After I click “create a Worker”, I’m immediately dropped into a web console where I can author, deploy, and test my function. And, I get some sample code that represents a fully-working Worker. All workers start by responding to a “fetch” event.
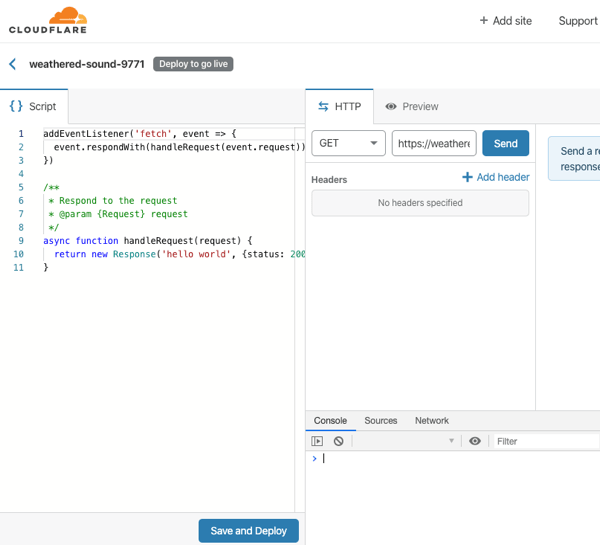
I don’t think you’d use this to create generic APIs or standalone apps. No, you’d use this to make the Cloudflare experience better. They handily have a whole catalog of templates to inspire you, or do your work for you. Most of these show examples of legit Cloudflare use cases: inspect and purge sensitive data from responses, deny requests missing an authorization header, do A/B testing based on cookies, and more. I copied the code from the “redirect” template which redirects requests to a different URL. I changed a couple things, clicked “save and deploy” and called my function.
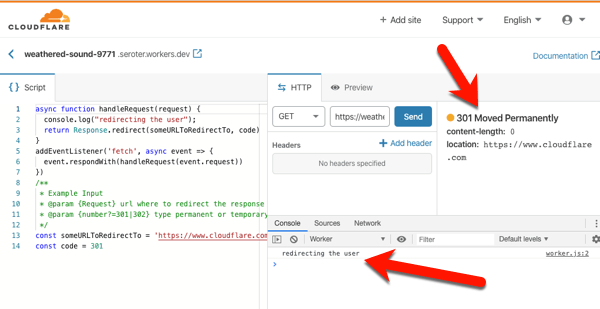
On the left is my code. In the middle is the testing console, where I submitted a GET request, and got back a “301 Moved Permanently” HTTP response. I also see a log entry from my code. If you call my function in your browser, you’ll get redirected to cloudflare.com.
That was super simple. The serverless compute products in this category have a constrained set of functionality, but I think that’s on purpose. They’re meant to expand the set of problems you can solve with their platform, versus creating standalone apps or services.
Category 3: Full Stack Apps
| Trigger / Destination | Signature | Packaging | Deployment |
| HTTP, queue, time | None | Containers | Web portal, CLI, CI/CD pipelines |
This category—which I can’t quite figure out the right label for—is about serverless computing for complete web apps. These aren’t functions, per-se, but run on a serverless stack that scales to zero and is billed based on usage. The unit of deployment is a container, which means you are providing more than code to the platform—you are also supplying a web server. This can make serverless purists squeamish since a key value prop of FaaS is the outsourcing of the server to the platform, and only focusing on your code. I get that. The downside of that pure FaaS model is that it’s an unforgiving host for any existing apps.
What fits in this category? The only obvious one to me is Google Cloud Run, but AWS Fargate kinda fits here too. Google Cloud Run is based on the popular open source Knative project, and runs as a managed service in Google Cloud. Let’s try it out.
First, install the Google Cloud SDK to get the gcloud command line tool. Once the CLI gets installed, you do a gcloud init in order to link up your Google Cloud credentials, and set some base properties.
Now, to build the app. What’s interesting here, is this is just an app. There’s no special format or method signature. The app just has to accept HTTP requests. You can write the app in any language, use any base image, and end up with a container of any size. The app should still follow some basic cloud-native patterns around fast startup and attached storage. This means—and Google promotes this—that you can migrate existing apps fairly easily. For my example, I’ll use Visual Studio for Mac to build a new ASP.NET Web API project with a couple RESTful endpoints.
The default project generates a weather-related controller, so let’s stick with that. To show that Google Cloud Run handles more than one endpoint, I’m adding a second method. This one returns a forecast for Seattle, which has been wet and cold for months.
namespace seroter_api_gcr.Controllers
{
[ApiController]
[Route("[controller]")]
public class WeatherForecastController : ControllerBase
{
private static readonly string[] Summaries = new[]
{
"Freezing", "Bracing", "Chilly", "Cool", "Mild", "Warm", "Balmy", "Hot", "Sweltering", "Scorching"
};
private readonly ILogger<WeatherForecastController> _logger;
public WeatherForecastController(ILogger<WeatherForecastController> logger)
{
_logger = logger;
}
[HttpGet]
public IEnumerable<WeatherForecast> Get()
{
var rng = new Random();
return Enumerable.Range(1, 5).Select(index => new WeatherForecast
{
Date = DateTime.Now.AddDays(index),
TemperatureC = rng.Next(-20, 55),
Summary = Summaries[rng.Next(Summaries.Length)]
})
.ToArray();
}
[HttpGet("seattle")]
public WeatherForecast GetSeattleWeather()
{
return new WeatherForecast { Date = DateTime.Now, Summary = "Chilly", TemperatureC = 6 };
}
}
}
If I were doing this the right way, I’d also change my Program.cs file and read the port from a provided environment variable, as Google suggests. I’m NOT going to do that, and instead will act like I’m just shoveling an existing, unchanged API into the service.
The app is complete and works fine when running locally. To work with Google Cloud Run, my app must be containerized. You can do this a variety of ways, including the most reasonable, which involves Google Cloud Build and continuous delivery. I don’t roll like that. WE’RE DOING IT BY HAND.
I will cheat and have Visual Studio give me a valid Dockerfile. Right-click the project, and add Docker support. This creates a Docker Compose project, and throws a Dockerfile into my original project.
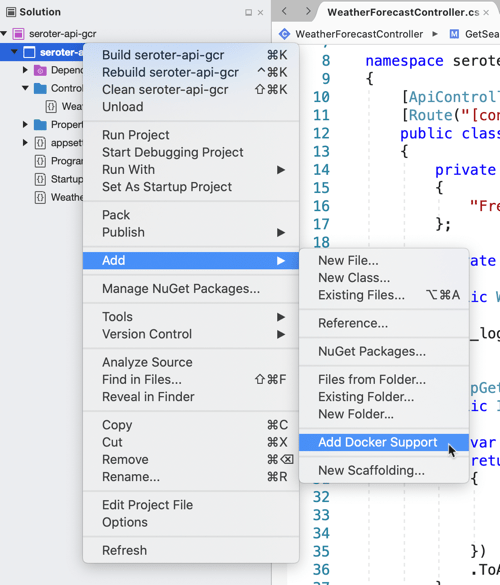
Let’s make one small tweak. In the Dockerfile, I’m exposing port 5000 from my container, and setting an environment variable to tell my app to listen on that port.

I opened my CLI, and navigated to the folder directly above this project. From there, I executed a Docker build command that pointed to the generated Dockerfile, and tagged the image for Google Container Registry (where Google Cloud Run looks for images).
docker build --file ./seroter-api-gcr/Dockerfile . --tag gcr.io/seroter/seroter-api-gcr
That finished, and I had a container image in my local registry. I need to get it up to Google Container Registry, so I ran a Docker push command.
docker push gcr.io/seroter/seroter-api-gcr
After a moment, I see that container in the Google Container Registry.

Neat. All that’s left is to spin up Google Cloud Run. From the Google Cloud portal, I choose to create a new Google Cloud Run service. I choose a region and name for my service.

Next up, I chose the container image to use, and set the container port to 5000. There are lots of other settings here too. I can create a connection to managed services like Cloud SQL, choose max requests per container, set the request timeout, specify the max number of container instances, and more.
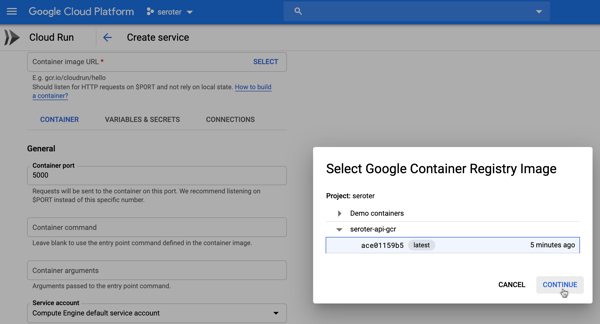
After creating the service, I only need to wait a few seconds before my app is reachable.
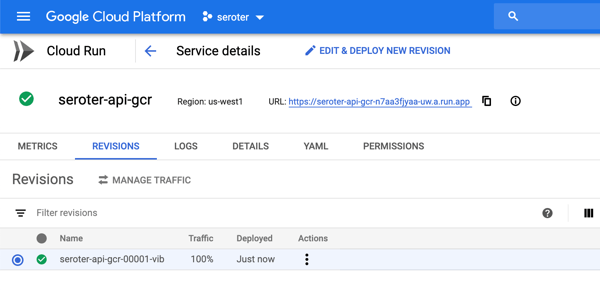
As expected, I can ping both API endpoints and get back a result. After a short duration, the service spins compute down to zero.

Wrap up
The landscape of serverless computing is broader than you may think. Depending on what you’re trying to do, it’s possible to make a sub-optimal choice. If you’re working with many different managed services and writing code to connect them, use the first category. If you’re enriching existing platforms with bits of compute functionality, use the second category. And if you’re migrating or modernizing existing apps, or have workloads that demand more platform flexibility, choose the third. Comments? Violent disagreement? Tell me below.

Leave a comment