Function-as-a-service gets all the glory in the serverless world, but the eventing backplane is the unheralded star of modern architectures, serverless or otherwise. Don’t get me wrong, scale-to-zero compute is cool. But is your company really transforming because you’re using fewer VMs? I’d be surprised. No, it seems that big benefits comes from a reimagined architecture, often powered by (managed) software that emit and consume events. If you have this in place, creative developers can quickly build out systems by tapping into event streams. If you have a large organization, and business systems that many IT projects tap into, this sort of event-driven architecture can truly speed up delivery.
But I doubt that most existing software at your company is powered by triggers and events. How can you start being more event-driven with all the systems you have in place now? In this post, I’ll look at three techniques I’ve used or seen.
First up, what do you need at your disposal? What’s the critical tech if you want to event-enable your existing SaaS or on-premises software? How about:
- Event bus/backbone. You need an intermediary to route events among systems. It might be on-premises or in the public cloud, in-memory or persistent, open source or commercial. The important thing is having a way to fan-out the information instead of only offering point-to-point linkages.
- Connector library. How are you getting events to and from software systems? You may use HTTP APIs or some other protocol. What you want is a way to uniformly talk to most source/destination systems without having to learn the nuances of each system. A series of pre-built connectors play a big part.
- Schema registry. Optional, but important. What do the events looks like? Can I discover the available events and how to tap into them?
- Event-capable targets. Your downstream systems need to be able to absorb events. They might need a translation layer or buffer to do so.
MOST importantly, you need developers/architects that understand asynchronous programming, stateful stream processing, and distributed systems. Buying the technology doesn’t matter if you don’t know how to best use it.
Let’s look at how you might use these technologies and skills to event-ify your systems. In the comments, tell me what I’m missing!
Option #1: Light up natively event-driven capabilities in the software
Some software is already event-ready and waiting for you to turn it on! Congrats if you use a wide variety of SaaS systems like Salesforce (via outbound messaging), Oracle Cloud products (e.g. Commerce Cloud), GSuite (via push notifications), Office 365 (via graph API) and many more. Heck, even some cloud-based databases like Azure Cosmos DB offer a change feed you can snack on. It’s just a matter of using these things.
On-premises software can work here as well. A decade ago, I worked at Amgen and we created an architecture where SAP events were broadcasted through a broker, versus countless individual systems trying to query SAP directly. SAP natively supported eventing then, and plenty of systems do now.
For either case—SaaS systems or on-premises software—you have to decide where the events go. You can absolutely publish events to single-system web endpoints. But realistically, you want these events to go into an event backplane so that everyone (who’s allowed) can party on the event stream.
AWS has a nice offering that helps here. Amazon EventBridge came out last year with a lot of fanfare. It’s a fully managed (serverless!) service for ingesting and routing events. EventBridge takes in events from dozens of AWS services, and (as of this writing) twenty-five partners. It has a nice schema registry as well, so you can quickly understand the events you have access to. The list of integrated SaaS offerings is a little light, but getting better.
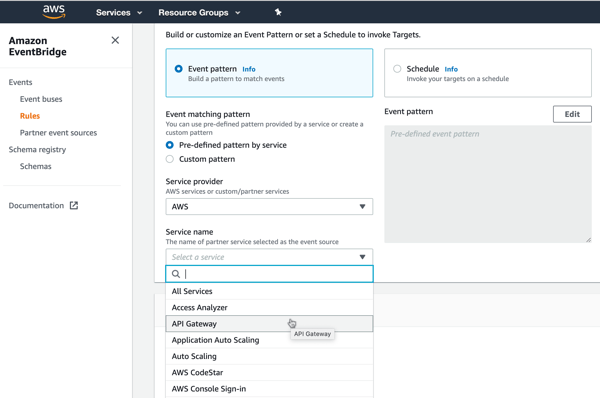
Given their long history in the app integration space, Microsoft also has a good cloud story here. Their eventing subsystem, called Azure Event Grid, ingests events from Azure (or custom) sources, and offers sophisticated routing rules. Today, its built-in event sources are all Azure services. If you’re looking to receive events from a SaaS system, you bolt on Azure Logic Apps. This service has a deep array of connectors that talk to virtually every system you can think of. Many of these connectors—including SharePoint, Salesforce, Workday, Microsoft Dynamics 365, and Smartsheet—support push-based triggers from the SaaS source. It’s fairly easy to create a Logic App that receives a trigger, and publishes to Azure Event Grid.

And you can always use “traditional” service brokers like Microsoft’s BizTalk Server which offer connectors, and pub/sub routing on any infrastructure, on-premises or off.
Option #2: Turn request-driven APIs into event streams
What if your software doesn’t have triggers or webhooks built in? That doesn’t mean you’re out of luck.
Virtually all modern packaged (on-premises or SaaS) software offers APIs. Even many custom-built apps do. These APIs are mostly request-response based (versus push-based async, or request-stream) but we can work with this.
One pattern? Have a scheduler call those request-response APIs and turn the results into broadcasted events. Is it wasteful? Yes, polling typically is. But, the wasted polling cycles are worth it if you want to create a more dynamic architecture.
Microsoft Azure users have good options. Specifically, you can quickly set up an Azure Logic App that talks to most everything, and then drops the results to Azure EventGrid for broadcast to all interested parties. Logic Apps also supports debatching, so you can parse the polled results and create an outbound stream of individual events. Below, every minute I’m listing records from ServiceNow that I publish to EventGrid.

Note that Amazon EventBridge also supports scheduled invocation of targets. Those targets include batch job queues, code pipelines, ECS tasks, Lambda functions, and more.
Option #3: Hack the subsystems to generate events
You’ll have cases where you don’t have APIs at all. Just give up? NEVER.
A last resort is poking into the underlying subsystems. That means generating events from file shares, FTP locations, queues, and databases. Now, be careful here. You need to REALLY know your software before doing this. If you create a change feed for the database that comes with your packaged software, you could end up with data integrity issues. So, I’d probably never do this unless it was a custom-built (or well-understood) system.
How do public cloud platforms help? Amazon EventBridge primarily integrates with AWS services today. That means if your custom or packaged app runs in AWS, you can trigger events off the foundational pieces. You might trigger events off EC2 state changes, new objects added to S3 blob storage, deleted users in the identity management system, and more. Most of these are about the service lifecycle, versus about the data going through the service, but still useful.
In Azure, the EventGrid service ingests events from lots of foundational Azure services. You can listen on many of the same types of things that Amazon EventBridge does. That includes blob storage, although nothing yet on virtual machines.
Your best bet in Azure may be once again to use Logic Apps and turn subsystem queries into an outbound event stream. In this example, I’m monitoring IBM DB2 database changes, and publishing events.
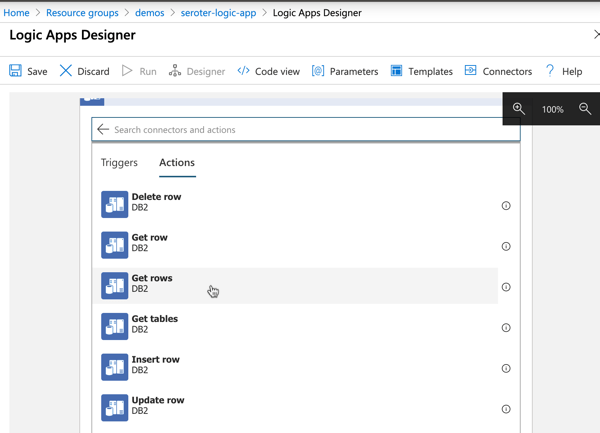
I could do the same with triggers on FTP locations …
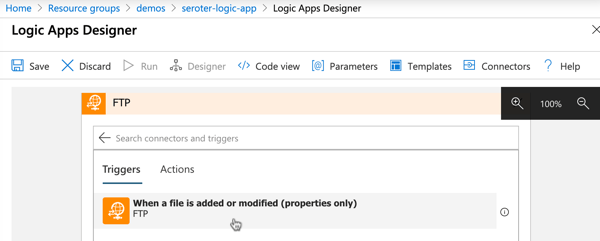
… and file shares.

In all those cases, it’s fairly straightforward to publish the queried items to Azure EventGrid for fan-out processing to trigger-based recipient systems
Ideally, you have option #1 at your disposal. If not, you can selectively choose #2 or #3 to get more events flowing in your architecture. Are there other patterns and techniques you use to generate events out of existing systems?