My company has an increasingly mature Operational Data Store (ODS) strategy where agreed-upon enterprise entities are added to shared repositories and accessible across the organization. These repositories are typically populated via batch loads from the source system. The ODS is used to keep systems which are dependent on the source system from bombarding the source with bulk data load processing requests. Independent of our ODS landscape, we have BizTalk Server doing fan-outs of real-time data from source systems to subscribers who can handle real-time data events. My smart architect buddy Ian is proposing a change to our model, and I thought I’d see what you all think.
So this is a summary of what our landscape looks like today:
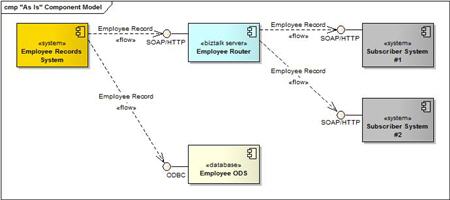
Notice that in this case, our ESB (BizTalk Server) is populated independently of our ODS. What Ian wants us to do is populate all of our ODSs from our ESB (thus making it just another real-time subscriber), and then throw a “get” interface on the ODS for request/reply operations which would have previously gone against the source system (see below). Below notice that the second subscriber of data receives real-time feeds from BizTalk, but also can query the ODS for data as well.
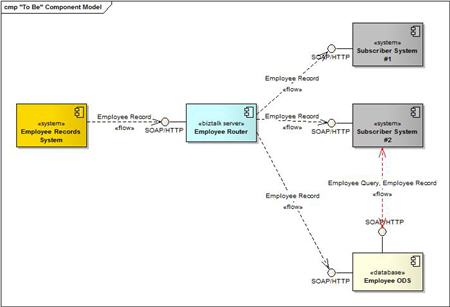
I guess I’ve typically thought of an ODS as being for batch interactions only, and not something that should be queried via request/response operations. If I need real-time data, I’d always go to the source itself. However, there are lots of benefits to this proposed model:
- Decouple clients from source system
- Remove any downstream impact on source system maintenance schedules
- Don’t require additional load, interfaces or adapters on source system (although most enterprise systems should be able to handle the incremental load of request/response queries).
- All the returned entities are already in a flattened, enterprise format as opposed to how they are represented in the source system
Now, before declaring that we never go to source systems and always hit an ODS (which would be insane), here are some considerations we’ve thought about:
- This should only be for shared enterprise entities that are distributed around the organization.
- There is only a “get by ID” operation on the ODS vs. any sort of “update” or “delete” operations. Clearly having any sort of “change” operations would be nuts and cause a data consistency nightmare.
- The availability/reliability of the platform hosting the ODS must meet or exceed that of the source system.
- We must be assured that the source system can publish a real-time event/data message. No “quasi-real-time” where updates are pushed out every hour.
- This model should not be used for entities where we need to be 110% sure that the data is current (e.g. financial data, extremely volatile data).
Now, there still may be a reliance by clients on the source system if the shared entity doesn’t contain every property required by the client. And in a truly event-driven model, maybe the non-ODS subscribers should only get event notifications and be expected to ping the ODS (which receives the full data message) if they want more data than what exists in the event message. But other than that, are there other things I’ve missed or considerations I should weigh more heavily one way or the other? Share with me.
Technorati Tags: BizTalk, SOA, architecture

Leave a comment