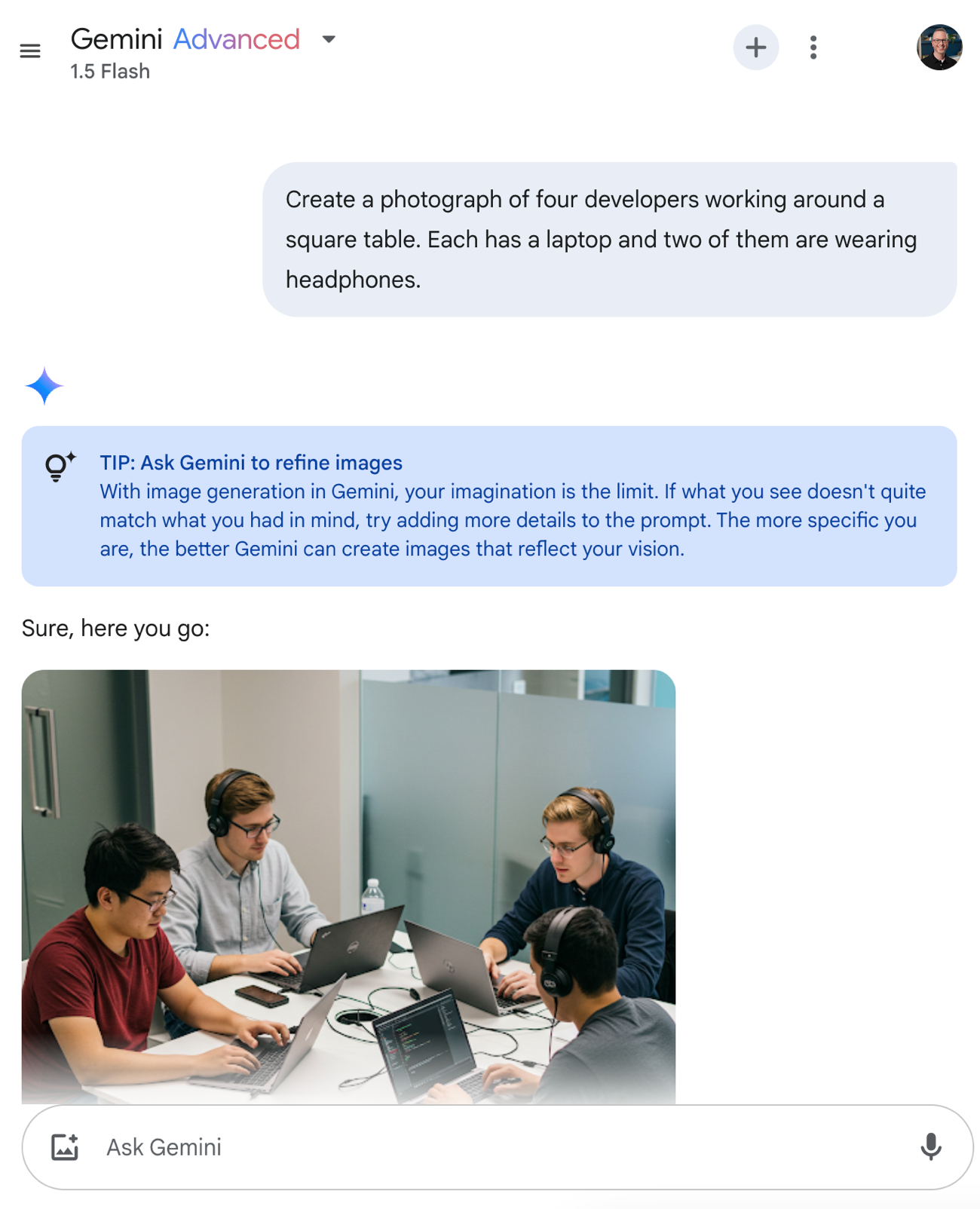
The “what” and the “how” in software engineering occasionally change at the same time. Often, one triggers the other. The introduction of mainframes ushered in batch practices that capitalized on the scarcity of computing power. As the Internet took off, developers needed to quickly update their apps and Agile took hold. Mobile computing and cloud computing happened, and DevOps emerged shortly thereafter. Our current moment seems different as the new “what” and “how” are happening simultaneously, but independently. The “what” that’s hot right now is AI-driven apps. Today’s fast-developing “how” is AI-native software engineering. I’m seeing all sorts of teams adopt AI to change how they work. What are they doing that you’re not?
AI natives always start (or end) with AI. The team at Pulley says “the typical workflow involves giving the task to an AI model first (via Cursor or a CLI program) to see how it performs, with the understanding that plenty of tasks are still hit or miss.” Studying a domain or competitor? Start with Gemini Deep Research or another AI research service. Find yourself stuck in an endless debate over some aspect of design? While you argued, the AI natives built three prototypes with AI to prove out the idea. Googlers are using it to build slides, debug production incidents, and much more. You might say “but I used an LLM before and it hallucinated while generating code with errors in it.” Stop it, so do you. Update your toolchain! Anybody seriously coding with AI today is using agents. Hallucinations are mostly a solved problem with proper context engineering and agentic loops. This doesn’t mean we become intellectually lazy. Learn to code, be an expert, and stay in charge. But it’s about regularly bringing AI in at the right time to make an impact.
I use the Gemini CLI to:
– debug production incidents, – activate and actuate changes on my CI/CD, – do risk analysis of changes and postmortems, – write slides and docs, – run capacity planning estimates.
— Ramón Medrano Llamas (@rmedranollamas) June 26, 2025
AI natives switched to spec-driven development. It’s not about code-first. Heck, we’re practically hiding the code! Modern software engineers are creating (or asking AI) for implementation plans first. My GM at Google Keith Ballinger says he starts projects by “ask[ing] the tool to create a technical design (and save to a file like arch.md) and an implementation plan (saved to tasks.md).” Former Googler Brian Grant wrote a piece where he explained creating 8000 character instructions that steered the agent towards the goal. Those folks at Pulley say that they find themselves “thinking less about writing code and more about writing specifications – translating the ideas in my head into clear, repeatable instructions for the AI.” These design specs have massive follow-on value. Maybe it’s used to generate the requirements doc. Or the first round of product documentation. It might produce the deployment manifest, marketing message, and training deck for the sales field. Today’s best engineers are great at documenting intent that in-turn, spawns the technical solution.
I have been testing and using Gemini CLI in the last weeks. Here's what my setup looks like:
– For complex tasks, I *never* ask for code first. My initial prompt is to create a plan "Create a detailed implementation plan for [FEATURE, BUG]". – Create multiple hierarchical GEMINI… pic.twitter.com/4brvJqv8nt
AI natives have different engineer and team responsibilities. With AI agents, you orchestrate. You remain responsible for every commit into main, but focus more on defining and “assigning” the work to get there. Legitimate work is directed to background agents like Jules. Or give the Gemini CLI the task of chewing through an analysis or starting a code migration project. Either way, build lots of the right tools and empower your agents with them. Every engineer is a manager now. And the engineer needs to intentionally shape the codebase so that it’s easier for the AI to work with. That means rule files (e.g. GEMINI.md), good READMEs, and such. This puts the engineer into the role of supervisor, mentor, and validator. AI-first teams are smaller, able to accomplish more, capable of compressing steps of the SDLC and delivering better quality, faster. AI-native teams have “almost eliminated engineering effort as the current bottleneck to shopping product.”
AI Agents turn everyone into a manager. We thought the future of software was AI reviewing and editing our work. But in fact the opposite is true. The future of software is to kick off tasks to AI Agents and review, edit, and orchestrate their work. https://t.co/dAlgt3IlRD
There are many implications for all this. Quality is still paramount. Don’t create slop. but to achieve the throughput, breadth, and quality your customers demand requires a leap forward in your approach. AI is overhyped and under-hyped at the same time, and it’s foolish to see AI as the solution to everything. But it’s a objectively valuable to a new approach. Many teams have already made the shift and have learned to continuously evaluate and incorporate new AI-first approaches. It’s awesome! If you’re ignoring AI entirely, you’re not some heroic code artisan; you’re just being unnecessarily stubborn and falling behind. Get uncomfortable, reassess how you work, and follow the lead of some AI-native pioneers blazing the trail.
Yesterday morning, we took the wraps off one of the most interesting Google releases of 2025. The Gemini CLI is here, giving you nearly unlimited access to Gemini from directly within the terminal. This is a new space, but there are other great solutions already out there. Why is this different? Yes, it’s good at multi-step reasoning, code generation, and creative tasks. Build apps, fix code, parse images, build slides, analyze content, or whatever. But what’s truly unique is that It’s fully open source, no cost to use, usable anywhere, and super extensible. Use Gemini 2.5 Pro’s massive context window (1m tokens), multimodality, and strong reasoning ability to do some amazing stuff.
Requirements? Have Node installed, and a Google account. That’s it. You get lots of free queries against our best models. You get more by being a cloud customer if you need it. Let’s have a quick look around, and then I’ll show you four prompts that demonstrate what it can really do.
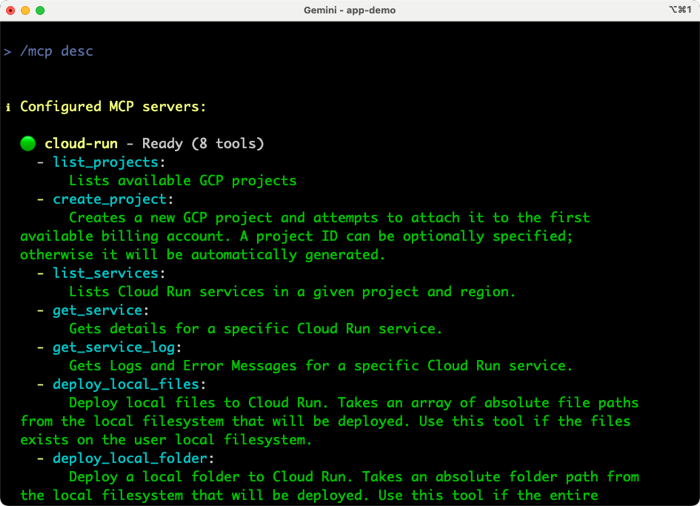
The slash command shows me what’s available here. I can see and resume previous chats, configure the editor environment, leverage memory via context files like GEMINI.md, change the theme, and use tools. Choosing that option shows us the available tools such as reading files and folders, finding files and folders, performing Google searches, running Shell commands, and more.
I’m only scratching the surface here, so don’t forget to check out the official repo, docs, and blog post announcement. But now, let’s walk through four prompts that you can repeat to experience the power of the Gemini CLI, and why each is a big deal.
Prompt #1 – Do some research.
Software engineering is more than coding. You spend time researching, planning, and thinking. I want to build a new app, but I’m not sure which frontend framework I should use. And I don’t want stale answers from an LLM that was trained a year ago.
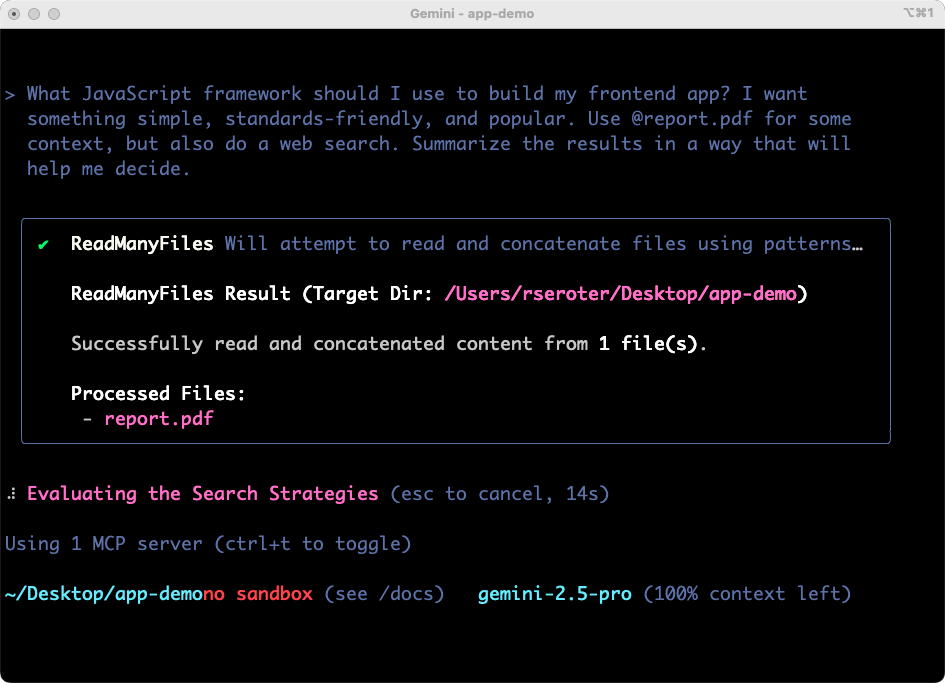
I’ve got a new research report on JavaScript frameworks, and also want to factor in web results. My prompt:
What JavaScript framework should I use to build my frontend app? I want something simple, standards-friendly, and popular. Use @report.pdf for some context, but also do a web search. Summarize the results in a way that will help me decide.
The Gemini CLI figured out some tools to use, successfully considered the file into the prompt, started off on its work searching the web, and preparing results.
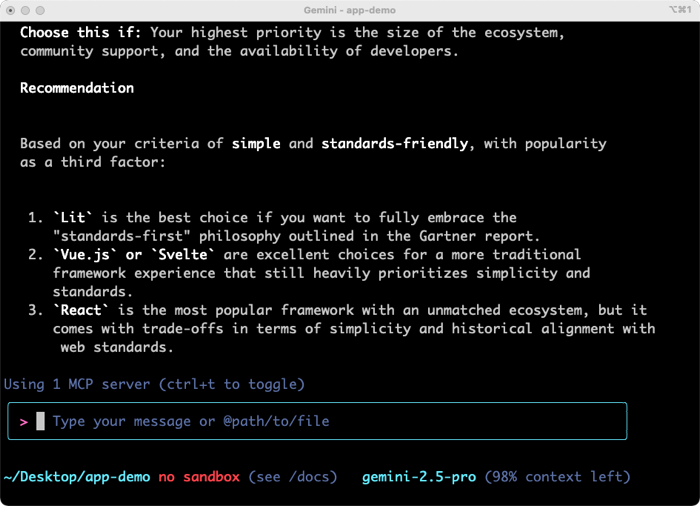
The results were solid. I got tradeoff and analysis on three viable options. The summary was helpful and I could have continued going back and forth on clarifying questions. For architects, team leaders, and engineers, having a research partner in the terminal is powerful.
Why was this a big deal? This prompt showed the use of live Google Search, local (binary) file processing, and in-context learning for devs. These tools are changing how I do quick research.
Prompt #2 – Build an app.
These tools will absolutely change how folks build, fix, change, and modernize software. Let’s build something new.
I fed in this prompt, based on my new understanding of relevant JavaScript frameworks.
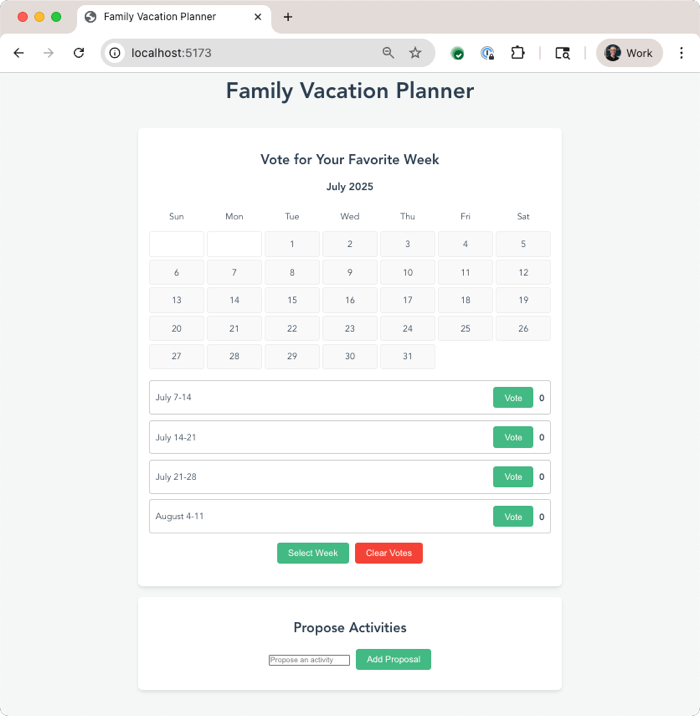
Let’s build a calendar app for my family to plan a vacation together. It should let us vote on weeks that work best, and then nominate activities for each day. Use Vue.js for the JavaScript framework.
Now to be sure, we didn’t build this to be excellent at one-shot results. Instead, it’s purposely built for an interactive back-and-forth with the software developer. You can start it with –yolo mode to have it automatically proceed without asking permission to do things, and even with –b to run it headless assuming no interactivity. But I want to stay in control here. So I’m not in YOLO mode.
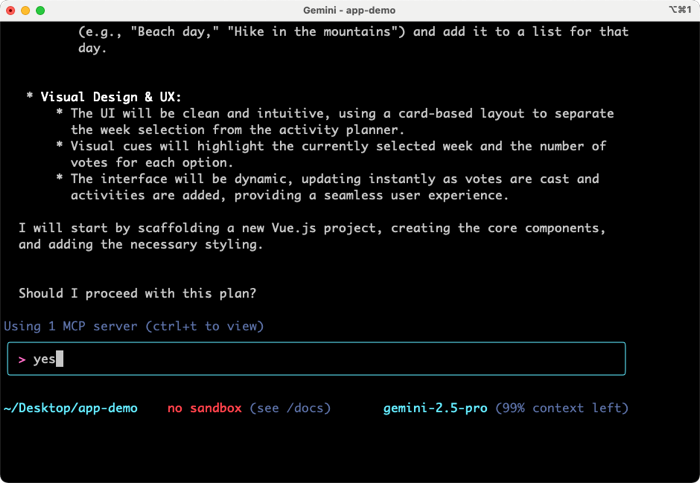
I quickly got back a plan, and was asked if I wanted to proceed.
Gemini CLI also asks me about running Shell commands. I can allow it once, allow it always, or cancel. I like these options. It’s fun watching Gemini make decisions and narrate what it’s working on. Once it’s done building directories, writing code, and evaluating its results, the CLI even starts up a server so that I can test the application. The first draft was functional, but not attractive, so I asked for a cleanup.
The next result was solid, and I could have continued iterating on new features along with look and feel.
Why was this a big deal? This prompt showed iterative code development, important security (request permission) features, and more. We’ll also frequently offer to pop you into the IDE for further coding. This will change how I understand or bootstrap most of the code I work with.
Prompt #3 – Do a quick deploy to the cloud.
I’m terrible at remembering the syntax and flags for various CLI tools. The right git command or Google Cloud CLI request? Just hopeless. The Gemini CLI is my solution. I can ask for what I want, and the Gemini CLI figures out the right type of request to make.
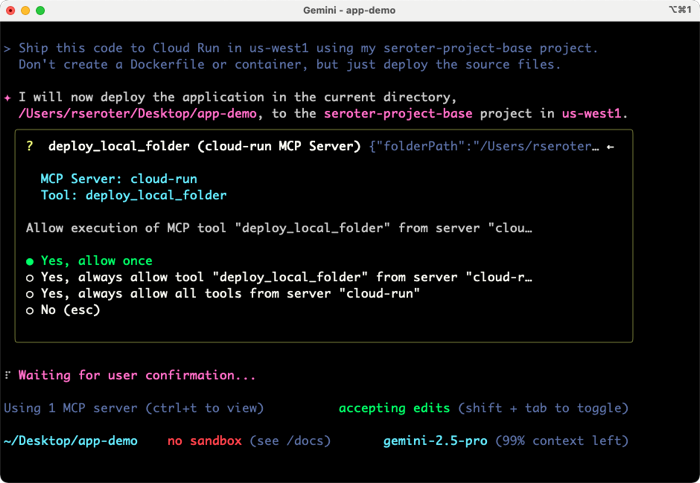
We added MCP as a first-class citizen, so I added the Cloud Run MCP server, as mentioned above. I also made this work without it, as the Gemini CLI figured out the right way to directly call the Google Cloud CLI (gcloud) to deploy my app. But, MCP servers provide more structure and ensure consistent implementation. Here’s the prompt I tried to get this app deployed. Vibe deployment, FTW.
Ship this code to Cloud Run in us-west1 using my seroter-project-base project. Don’t create a Dockerfile or container, but just deploy the source files.
The Gemini CLI immediately recognizes that a known MCP tool can help, and shows me the tool it chose.
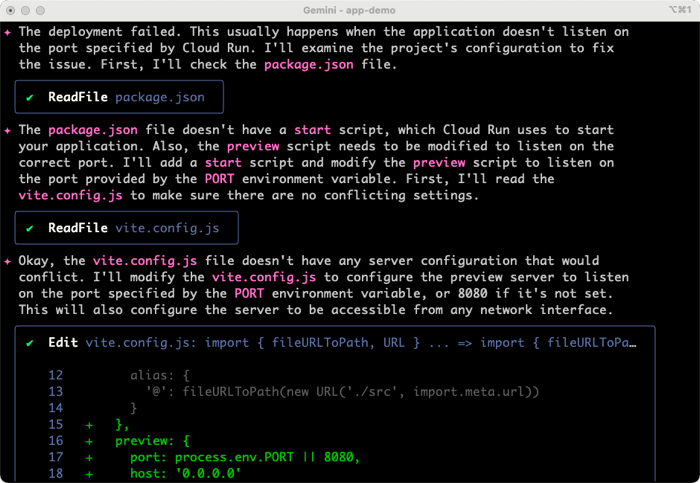
It got going, and shipped my code successfully to Cloud Run using the MCP server. But the app didn’t start correctly. The Gemini CLI noticed that by reading the service logs, and diagnosed the issue. We didn’t provide a reference for which port to listen on. No problem.
It came up with a fix, made the code changes, and redeployed.
Why was this a big deal? We saw the extensibility of MCP servers, and the ability to “forget” some details of exactly how other tools and CLIs work. Plus we observed that the Gemini CLI did some smart reasoning and resolved issues on its own. This is going to change how I deploy, and how much time I spend (waste?) deploying.
Prompt #4 – Do responsible CI/CD to the cloud.
The third prompt was cool and showed how you can quickly deploy to a cloud target, even without knowing the exact syntax to make it happen. I got it working with Kubernetes too. But can the Gemini CLI help me do proper CI/CD, even if I don’t know exactly how to do it? In this case I do know how to set up Google Cloud Build and Cloud Deploy, but let’s pretend I don’t. Here’s the prompt.
Create a Cloud Build file that would build a container out of this app code and store it in Artifact Registry. Then create the necessary Cloud Deploy files that defines a dev and production environment in Cloud Run. Create the Cloud Deploy pipeline, and then reference it in the Cloud Build file so that the deploy happens when a build succeeds. And then go ahead trigger the Cloud Build. Pay very careful attention for how to create the correct files and syntax needed for targeting Cloud Run from Cloud Deploy.
The Gemini CLI started by asking me for some info from my Google Cloud account (project name, target region) and then created YAML files for Cloud Build and Cloud Deploy. It also put together a CLI command to instantiate a Docker repo in Artifact Registry. Now, I know that the setup for Cloud Deploy working with Cloud Run has some specific syntax and formatting. Even with my above command, I can see that I didn’t get syntactically correct YAML in the skaffold file.
I rejected the request of the Gemini CLI to do a deployment, since I knew it would fail. Then I gave it the docs URL for setting up Cloud Run with Cloud Deploy and asked it to make a correction.
That Skaffold file doesn’t look correct. Take a look at the docs (https://cloud.google.com/deploy/docs/deploy-app-run), and follow its guidance for setting up the service YAML files, and referencing the right Skaffold version at the top. Show me the result before pushing a change to the Cloud Deploy pipeline.
Fortunately, the Gemini CLI can do a web fetch and process the latest product documentation. I did a couple of turns and got what I wanted. Then I asked it to go ahead and update the pipeline and trigger Cloud Build.
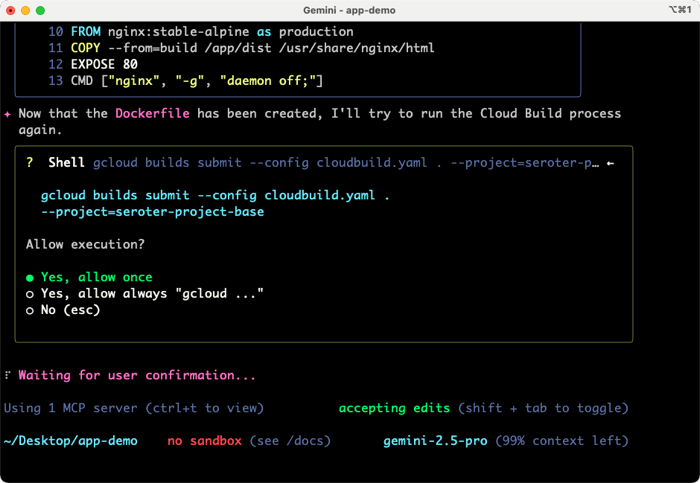
It failed at first because I didn’t have a Dockerfile, but after realizing that, automatically created one and started the build again.
It took a few iterations of failed builds for the Gemini CLI to land on the right syntax. But it kept dutifully trying, making changes, and redeploy until it got it right. Just like I would have if I were doing it myself!
After that back and forth a few times, I had all the right files, syntax, container artifacts, and pipelines going.
Some of my experiments went faster than others, but that’s the nature of these tools, and I still did this faster overall than I would have manually.
Why was this a big deal? This showcased some sophisticated file creation, iterative improvements, and Gemini CLI’s direct usage of the Google Cloud CLI to package, deploy, and observe running systems in a production-like way. It’ll change how confident I am doing more complex operations.
Background agents, orchestrated agents, conversational AI. All of these will play a part in how we design, build, deploy, and operate software. What does that mean to your team, your systems, and your expectations? We’re about to find out.
Where you decide to run your web app is often a late-binding choice. Once you’ve finished coding something you like and done some localhost testing, you seek out a reasonable place that gives you a public IP address. Developers have no shortage of runtime host options, including hyperscalers, rented VMs from cheap regional providers, or targeted services from the likes of Firebase, Cloudflare, Vercel, Netlify, Fly.io, and a dozen others. I’m an unapologetic fanboy of Google Cloud Run—host scale-to-zero apps, functions, and jobs that offer huge resource configurations, concurrent calls, GPUs, and durable volumes with a generous free tier and straightforward pricing—and we just took the wraps of a handful of new ways to take a pile of code and turn it into a cloud endpoint.
Vibe-code a web app in Google AI Studio and one-click deploy to Cloud Run
Google AI Studio is really a remarkable. Build text prompts against our leading models, generate media with Gemini models, and even build apps. All at no cost. We just turned on the ability to do simple text-to-app scenarios, and added a button that deploys your app to Cloud Run.
First, I went to the “Build” pane and added a text prompt for my new app. I wanted a motivational quote printed on top of an image of an AI generated dog.
In one shot, I got the complete app including the correct backend AI calls to Gemini models for creating the motivational quote and generating a dog pic. So cool.
Time to ship it. There’s rocket ship icon on the top right. Assuming you’ve connected Google AI Studio to a Google Cloud account, you’re able to pick a project and one-click deploy.
It takes just a few seconds, and you get back the URL and a deep link to the app in Google Cloud.
Clicking that link shows that this is a standard Cloud Run instance, with the Gemini key helpfully added as an environment variable (versus hard coded!).
And of course, viewing the associated link takes me to my app that gives me simple motivation and happy dogs.
That’s such a simple development loop!
Create an .NET app in tools like Cursor and deploy it using the Cloud Run MCP server
Let’s say you’re using one of the MANY agentic development tools that make it simpler to code with AI assistance. Lots of you like Cursor. It supports MCP as a way to reach into other systems via tools.
We just shipped a Cloud Run MCP server, so you can make tools like Cursor aware of Cloud Run and support straightforward deployments.
I started in Cursor and asked it to build a simple REST API and picked Gemini 2.5 Pro as my preferred model. Cursor does most (all?) of the coding work for you if you want it to.
It went through a few iterations to land on the right code. I tested it locally to ensure the app would run.
Cursor has native support for MCP. I added a .cursor directory to my project and dropped in a mcp.json file in there. Cursor picked up the MCP entry, validated it, and showed me the available tools.
I asked Cursor to deploy my C# app. It explored the local folder and files to ensure it had what it needed.
Cursor realized it had a tool that could help, and proposed the “deploy_local_folder” tool from the Cloud Run MCP server.
After providing some requested values (location, etc), Cursor successfully deployed my .NET app.
That was easy. And this Cloud Run MCP server will work with any of your tools that understand MCP.
Push an open model from Google AI Studio directly to Cloud Run
Want to deploy a model to Cloud Run? It’s the only serverless platform I know of that offers GPUs. You can use tools like Ollama to deploy any open model to Cloud Run, and I like that we made even easier for Gemma fans. To see this integration, you pick various Gemma 3 editions in Google AI Studio.
Once you’ve done that, you’ll see a new icon that triggers a deployment directly to Cloud Run. Within minutes, you have an elastic endpoint providing inference.
It’s not hard to deploy open models to Cloud Run. This option makes it that much easier.
Deploy an Python agent built with the Agent Development Kit to Cloud Run with one command
The Agent Development Kit is an open source framework and toolset that devs use to build robust AI agents. The Python version reached 1.0 yesterday, and we launched a new Java version too. Here, I started with a Python agent I built.
Built into ADK are a few deployment options. It’s just code, so you can run it anywhere. But we’ve added shortcuts to services like Google Cloud’s Vertex AI Agent Engine and Cloud Run. Just one command puts my agent onto Cloud Run!
We don’t yet have this CLI deployment option for the Java ADK. But it’s also simple to use the Google Cloud CLI command to deploy a Java app or agent to Cloud Run with one command too.
Services like Cloud Run are ideal for your agents and AI apps. These built-in integrations for ADK help you get these agents online quickly.
Use a Gradio instance in Cloud Run to experiment with prompts after one click from Vertex AI Studio
How do you collaborate or share prompts with teammates? Maybe you’re using something like Google Cloud Vertex AI to iterate on a prompt yourself. Here, I wrote system instructions and a prompt for helping me prioritize my work items.
Now, I can click “deploy an app” and get a Gradio instance for experimenting further with my app.
This has public access by default, so I’ve got to give the ok.
After a few moments, I have a running Cloud Run app! I’m shown this directly from Vertex AI and have a link to open the app.
That link brings me to this Gradio instance that I can share with teammates.
The scalable and accessible Cloud Run is ideal for spontaneous exploration of things like AI prompts. I like this integration!
Ship your backend Java code to Cloud Run directly from Firebase Studio
Our final example looks at Firebase Studio. Have you tried this yet? It’s a free to use, full-stack dev environment in the cloud for nearly any type of app. And it supports text-to-app scenarios if you don’t want to do much coding yourself. There are dozens of templates, including one for Java.
I spun up a Java dev environment to build a web service.
This IDE will look familiar. Bring in your favorite extensions, and we’ve also pre-loaded this with Gemini assistance, local testing tools, and more. See here that I used Gemini to add a new REST endpoint to my Java API.
Here on the left is an option to deploy to Cloud Run!
After authenticating to my cloud account and picking my cloud project, I could deploy. After a few moments, I had another running app in Cloud Run, and had a route to make continuous updates.
Wow. That’s a lot of ways to go from code to cloud. Cloud Run is terrific for frontend or backend components, functions or apps, open source or commercial products. Try one of these integrations and tell me what you think!
I’m a believer in platform engineering as a concept. Bringing standardization and golden paths to developers so that they can ship software quickly and safely sounds awesome. And it is. But it’s also been a slog to land it. Measurement has been inconsistent, devs are wildly unhappy with the state of self-service, and the tech landscape is disjointed with tons of tools and a high cost of integration. Smart teams are finding success, but this should be easier. Maybe now it is.
Last week at Google Cloud Next ’25, we took the wraps off the concept of a Cloud Internal Developer Platform (IDP). Could we take the best parts of platform engineering—consistent config management, infrastructure orchestration, environment management, deployment services, and role-based access—and deliver them as a vertically-integrated experience? Can we shift down instead of putting so much responsibility on the developer? I think we can. We have to! Our goal at Google Cloud is to deliver a Cloud IDP that is complete, integrated, and application-centric. The cloud has typically been a pile of infrastructure services, loosely organized through tags or other flawed grouping mechanisms. We’re long overdue for an app-centric lens on the cloud.
Enough talking. Let me show you by walking through an end-to-end platform engineering scenario. I want to design and deploy an application using architecture templates, organize the deployed artifacts into an “application”, troubleshoot an issue, and then get visibility into the overall health of the application.
Design and deploy app architectures with Application Design Center
To make life difficult IDP also stands for “internal developer portal.” That’s not confusing at all. Such a portal can serve as the front-door for a dev team that’s interacting with the platform. Application Design Center (ADC) is now in public preview, and offers functionality for creating templates, storing templates in catalogs, sharing templates, and deploying instances of templates.
I can start with an existing ADC template or create a brand new one. Or, I can use the ever-present Cloud Assist chat to describe my desired architecture in natural language, iterate on it, and then create an ADC template from that. Super cool!
For the rest of this example, I’ll use an existing app template in ADC. This one consists of many different components. Notice that I’ve got Cloud Run (serverless) components, virtual machines, storage buckets, secrets, load balancers, and more. Kubernetes coming soon!
I can add to this architecture by dropping and configuring new assets onto the canvas. I can also use natural language! From the Cloud Assist chat, I asked to “add a cache to the movie-frontend service” and you can see that I got a Redis cache added. And the option to accept or reject the suggestion.
Worried that you’re just working in a graphical design surface? Everything on the canvas is represented as Terraform. Switching from “Design” to “Code” at the top reveals the clean Terraform generated by ADC. Use our managed Terraform service or whatever you want for your infrastructure orchestration workflow with Terraform.
When I’m done with the template and want to instantiate my architecture, I can turn this into a deployed app. Google Cloud takes care of all the provisioning, and the assets are held together in an application grouping.
ADC is powerful for a few reasons. It works across different runtimes and isn’t just a Kubernetes solution. ADC offers good template cataloging and sharing capabilities. Its support for natural language is going to be very useful. And its direct integration with other parts of the platform engineering journey is important. Let’s see that now.
Organize apps with App Hub
An “app” represents many components, as we just saw. They might even span “projects” in your cloud account. And an application should have clearly identified owners and criticality. Google Cloud App Hub is generally available, and acts as a real-time registry of resources and applications.
App Hub auto-discovers resources in your projects (a couple dozen types so far, many more to come) and lets you automatically (via ADC) or manually group them into applications.
For a given app, I can see key metadata like its criticality and environment. I can also see who the development, business, and operations owners are. And of course, I can see a list of all the resources that make up this application.
Instead of this being a static registry, App Hub maintains links to the physical resources you’ve deployed. Once I have an application, then what?
Observe app-centric metrics in Cloud Monitoring
It’s not easy to see how apps or app-related components are performing. Now it is. We just enabled the preview of Application Monitoring in our Cloud Monitoring service.
From here, I can a list of all my App Hub apps, and the component performance of each.
When I drill into the “web server” resource, I get some terrific metrics and logs, all within whatever timeframe I specify. This is a high-density view, and I like the data points we surface here.
Again, we’re seeing a smart, integrated set of technologies here versus a series of independent stack pieces that aren’t deeply aware of the other.
Resolve issues using Cloud Assist Investigations
In that dashboard above, I’m seeing that container restarts are a real issue in this application. It’s time to troubleshoot!
Within this dashboard, I see embedded logs, and notice a warming about back-off restarting with my pods. I don’t love reading piles of JSON to try and figure out the problem, nor can I see all the ancillary content just by looking at this log entry. In private preview we have this new Investigate button.
Clicking that button sparks a new Investigation. These are AI-fueled evaluations based on a given error, and a host of related application data points. It’s meant to be a holistic exploration.
Heres where all that shared context is so valuable. In under a minute, I see the details of the Investigation. These details show the issue itself and then a series of “relevant observations.” An Investigation can be edited and re-run, downloaded, and more.
Most importantly, there’s a “Hypothesis” section that helps the app owner or SRE pinpoint the problem area to focus on. These seem well-described with clear recommendations.
I’m confident that this will be a supremely useful tool for those trying to quickly resolve application issues.
Manage the overall health of the application in Cloud Hub
What’s your “home page” for the applications you manage? That’s the idea behind the preview of the Cloud Hub. It offers app owners a starting point for the management, health, and optimization of the apps their care about.
I might start each day looking at any platform-wide incidents impacting my app, any deployment issues, service health, and more.
One private preview feature I’ll show you here is the “Optimization” view. I’m getting app-level cost and utilization summaries! It’s easy to view this for different time periods, and even drill into on a specific product within the app. What a useful view for identifying the actual cost of a running application in dev, test, or prod.
Summary
While platform engineering has been around a while, and cloud computing even longer, neither has been easy for people who just want to build and run apps. Google Cloud is uniquely set up to make this better, and this new Cloud IDP experience might be an important step forward. Try out some of the components yourself!
It can feel like a relief to attend a single-track conference. No choices to make! Just sit back and learn without feeling angst about choosing the “right” talk to listen to. Of course, big conferences have their own value as you have nearly endless options for what you want to learn about. But it’s easy to feel overwhelmed. I helped assemble the breakout program for Google Cloud Next ’25 (April 9th through 11th) and every talk is great. Some will be more interesting to developers than others, and these are the ones I’m confident you’d really enjoy.
Specifically, these are talks where you’ve got speakers I can vouch for, fresh insights about software development, and in most cases, live demonstrations. And, a handful of talks—I asked the Google DeepMind team to fill up a mini-track for us—feature speakers you don’t always get to hear from at Cloud Next.
[engineering] Unlock developer productivity with AI. How does Google do it? I asked these folks to come show us how Google engineering transformed with AI.
[cloud] Developer’s jumpstart guide to Vertex AI. Zack and Dave are going to be hands-on for most of this, which should help you really understand what’s possible.
[engineering] Navigate a web app with an AI-enabled browser agent. Our own technical writing team built an innovative agent to help us improve the ongoing quality of our docs. You’ll enjoy learning about this.
[cloud] What’s new in Gemini Code Assist. There will be many exciting updates, and these great speakers will undoubtably show it off.
There are dozens of other terrific developer-focused talks at Next. Build your program for the conference, or watch out for the recorded version of most of these to show up later.
I’m approaching twenty-five years of connecting systems together. Yikes. In the summer of 2000, I met a new product called BizTalk Server that included a visual design tool for building workflows. In the years following, that particular toolset got better (see image), and a host of other cloud-based point-and-click services emerged. Cloud integration platforms are solid now, but fairly stagnant. I haven’t noticed a ton of improvements over the past twelve months. That said, Google Cloud’s Application Integration service is improving (and catching up) month over month, and I wanted to try out the latest and greatest capabilities. I think you’ll see something you like.
Could you use code (and AI-generated code) to create all your app integrations instead of using visual modeling tools like this? Probably. But you’d see scope creep. You’d have to recreate system connectors (e.g. Salesforce, Stripe, databases, Google Sheets), data transformation logic, event triggers, and a fault-tolerant runtime for async runners. You might find yourself creating a fairly massive system to replace one you can use as-a-service. So what’s new with Google Cloud Application Integration?
Project setup improvements
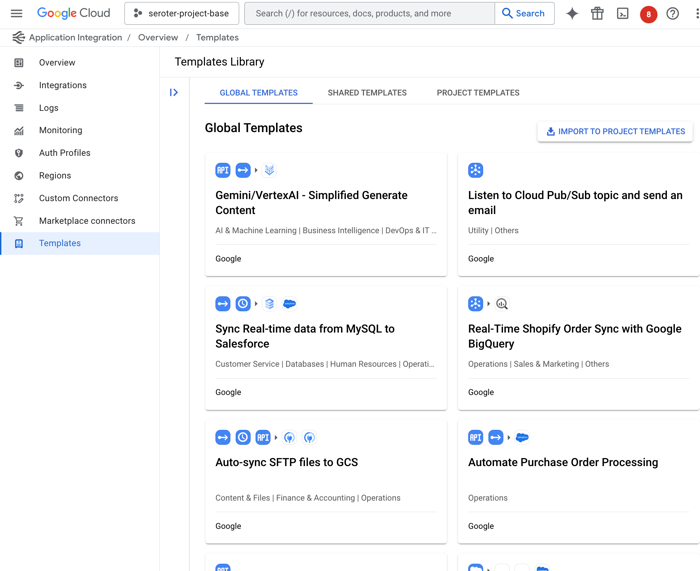
Let’s first look at templates. These are pre-baked blueprints that you can use to start a new project. Google now offers a handful of built-in templates, and you can see custom ones shared with you by others.
I like that anyone can define a new template from an existing integration, as I show here.
Once I create a template, it shows up under “project templates” along with a visual preview of the integration, the option to edit, share or download as JSON, and any related templates.
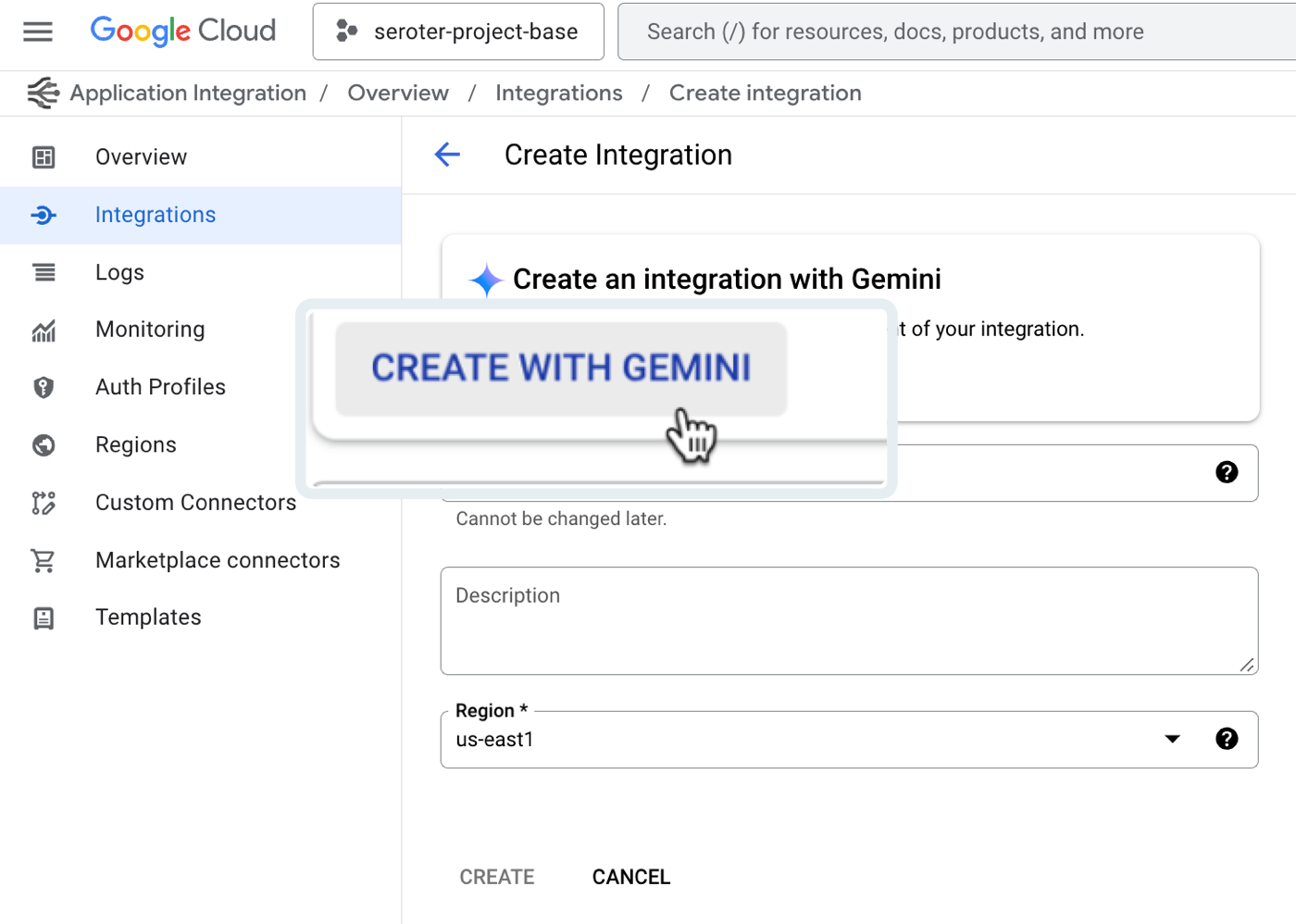
The next new feature of Google Cloud Application Integration related to setup is the Gemini assistance. This is woven into a few different features—I’ll show another later—including the ability to create new integrations with natural language.
After clicking that button, I’m asked to provide a natural language description of the integration I want to create. There’s a subset of triggers and tasks recognized here. See here that I’m asking for a message to be read from Pub/Sub, approvals sent, and a serverless function called if the approval is provided.
I’m shown the resulting integration, and iterate in place as much as I want. Once I land on the desired integration, I accept the Gemini-created configuration and start working with the resulting workflow.
This feels like a very useful AI feature that helps folks learn the platform, and set up integrations.
New design and development features
Let’s look at new features for doing the core design and development of integrations.
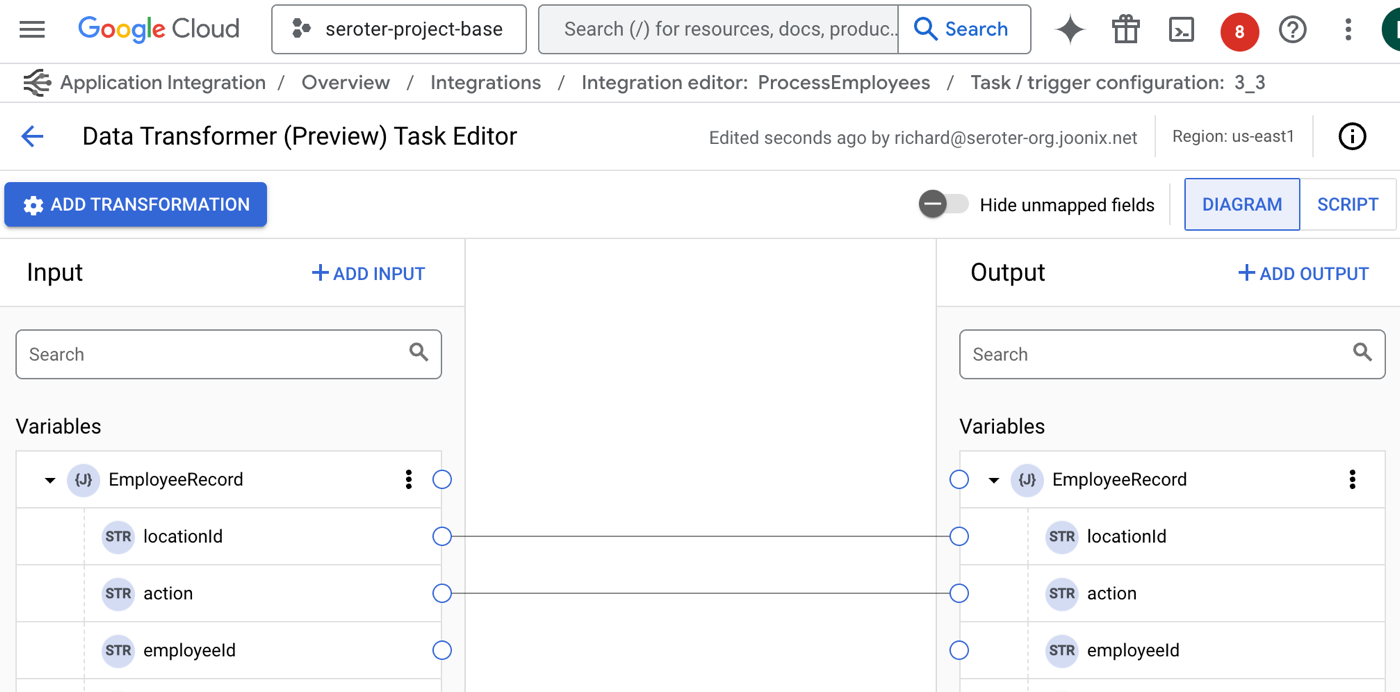
First up, there’s a new experience for seeing and editing configuration variables. What are these? Think of config variable as settings for the integration itself that you can set at deploy time. It might be something like a connection string or desired log level.
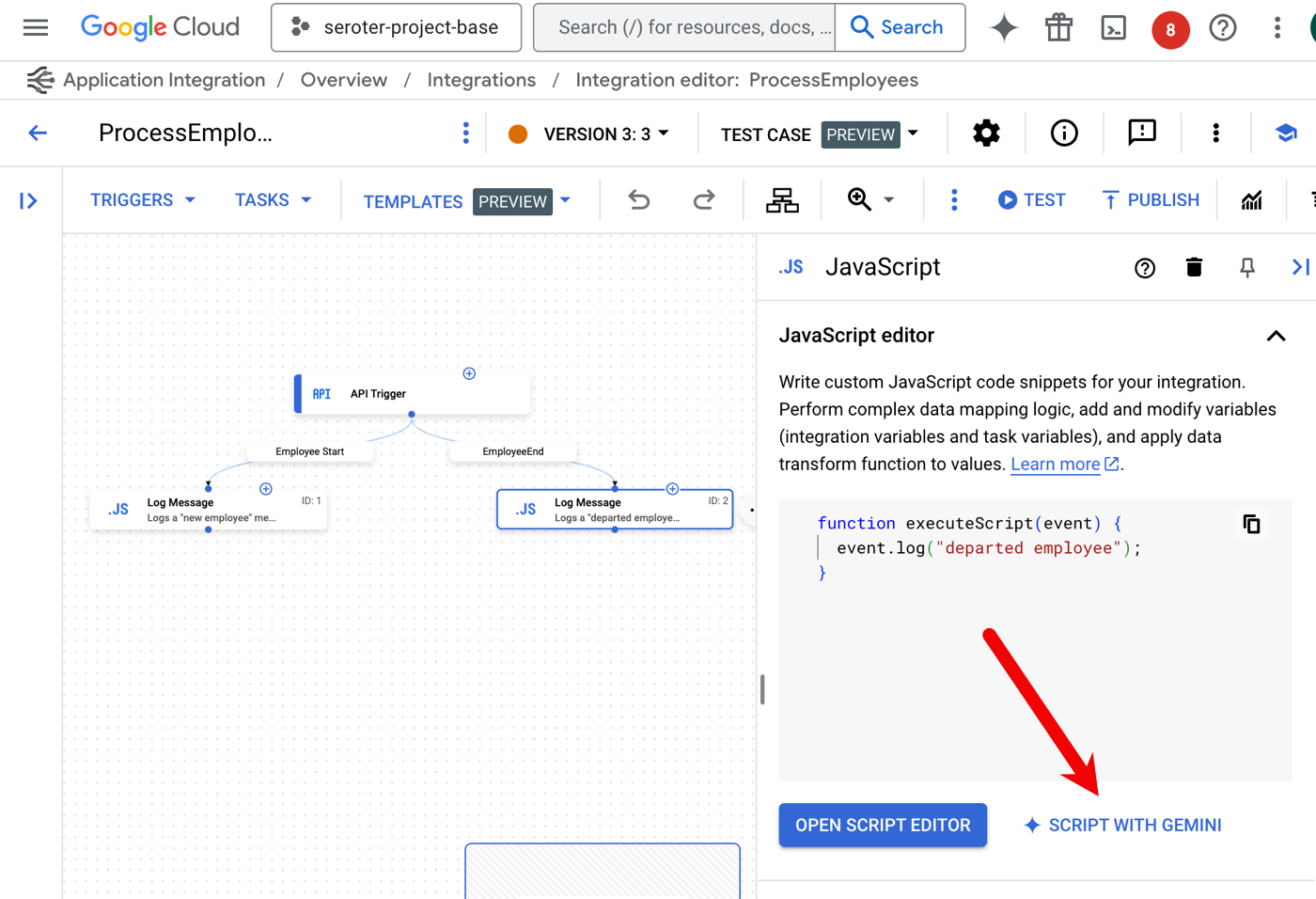
Here’s another great use of AI assistance. The do-whatever-you-want JavaScript task in an integration can now be created with Gemini. Instead of writing the JavaScript yourself, use Gemini to craft it.
I’m provided a prompt and asked for updated JavaScript to also log the ID of the employee record. I’m then shown a diff view that I can confirm, or continue editing.
As you move data between applications or systems, you likely need to switch up structure and format. I’ve long been jealous of the nice experience in Azure Logic Apps, and now our mapping experience is finally catching up.
Is the mapping not as easy as one to one? No problem. There are now transformation operations for messing with arrays, performing JSON operations, manipulating strings, and much more.
I’m sure your integrations NEVER fail, but for everyone else, it’s useful to know have advanced failure policies for rich error handling strategies. For a given task, I can set up one or more failure policies that tell the integration what to do when an issue occurs? Quit? Retry? Ignore it? I like the choices I have available.
There’s a lot to like the authoring experience, but these recent updates make it even better.
Fresh testing capabilities
Testing? Who wants to test anything? Not me, but that’s because I’m not a good software engineer.
We shipped a couple of interesting features for those who want to test their integrations.
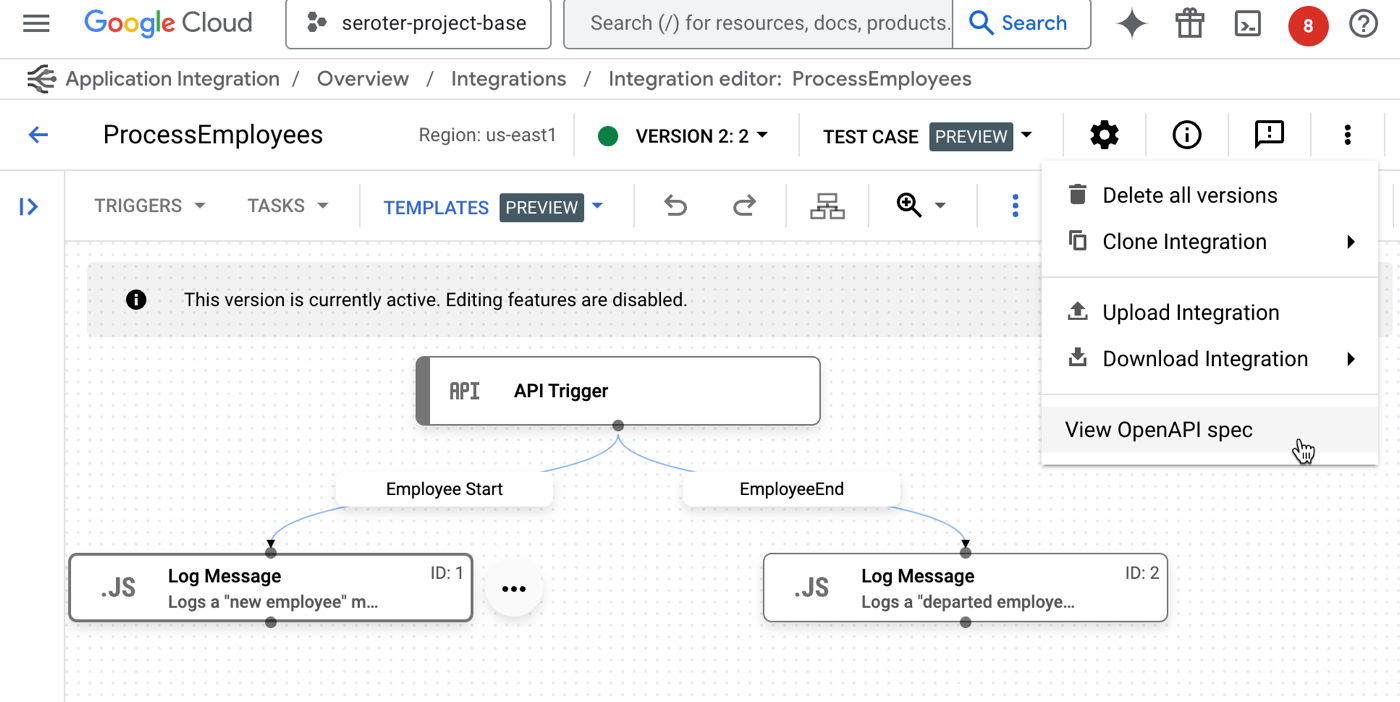
First, it’s a small thing, but when you have an API Trigger kicking off your integration—which means that someone invokes it via web request—we now make it easy to see the associated OpenAPI spec. This makes it easier to understand a service, and even consume it from external testing tools.
Once I choose to “view OpenAPI spec“, I get a slide-out pane with the specification, along with options to copy or download the details.
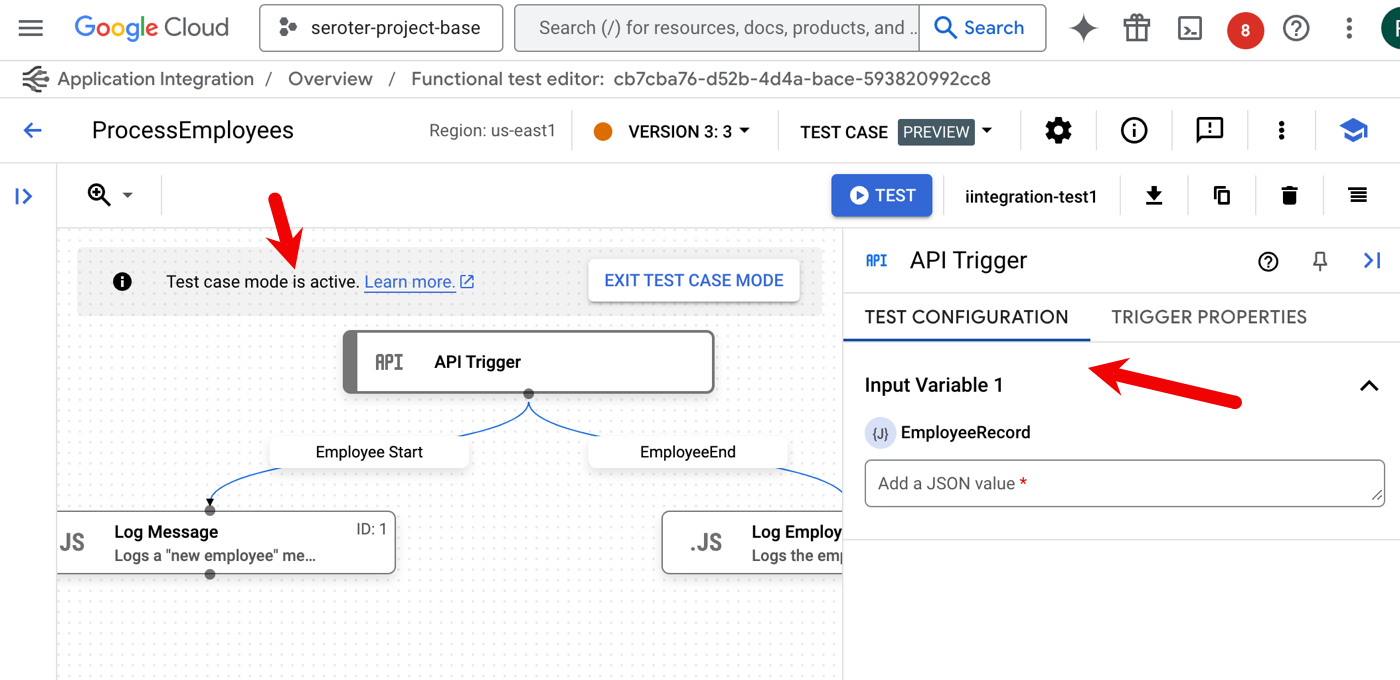
But by far, the biggest addition to the Application Integration toolchain for testers is the ability to create and run test plans. Add one or more test cases to an integration, and apply some sophisticated configurations to a test.
When I choose that option, I’m first asked to name the test case and optionally provide a description. Then, I enter “test mode” and set up test configurations for the given components in the integration. For instance, here I’ve chosen the initial API trigger. I can see the properties of the trigger, and then set a test input value.
A “task” in the integration has more test case configuration options. When I choose the JavaScript task, I see that I can choose a mocking strategy. Do you play it straight with the data coming in, purposely trigger a skip or failure, or manipulate the output?
Then I add one or more “assertions” for the test case. I can check whether the step succeeded or failed, if a variable equals what I think it should, or if a variable meets a specific condition.
Once I have a set of test cases, the service makes it easy to list them, duplicate them, download them, and manage them. But I want to run them.
Even if you don’t use test cases, you can run a test. In that case, you click the “Test” button and provide an input value. If you’re using test cases, you stay in (or enter) “test case mode” and then the “Test” button runs your test cases.
This final category looks at operational features for integrations.
This first feature shipped a few days ago. Now we’re offering more detailed execution logs that you can also download as JSON. A complaint with systems like this is that they’re a black box and you can’t tell what’s going on. The more transparency, the better. Lots of log details now!
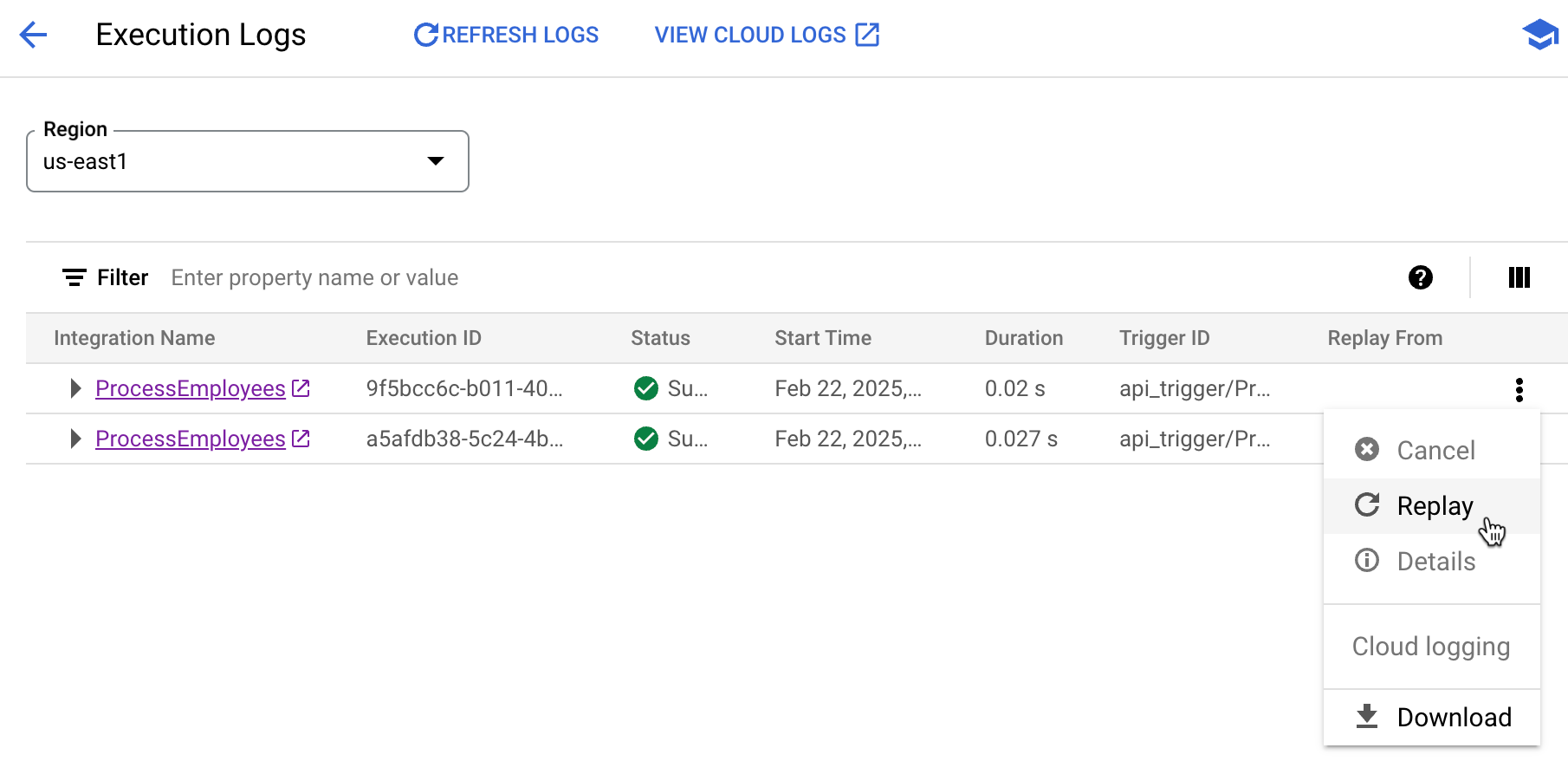
Another new operational feature is the ability replay an integration. Maybe something failed downstream and you want to retry the whole process. Or something transient happened and you need a fresh run. No problem. Now I can pick any completed (or failed) integration and run it again.
When I use this, I’m asked for a reason to replay. And what I liked is that after the replay occurs, there’s an annotation indicating that this given execution was the result of a replay.
Also be aware that you can now cancel an execution. This is hand for long-running instances that may no longer matter.
Summary
You don’t need to use tools like this, of course. You can connect your systems together with code or scripts. But I personally like managed experiences like this that handle the machinery of connecting to systems, transforming data, and dealing with running the dozens or thousands of hourly events between systems.
Software is never going to be the same. Why would we go back to laborious research efforts, wasting time writing boilerplate code, and accepting so many interruptions to our flow state? Hard pass. It might not happen for you tomorrow, next month, or next year, but AI will absolutely improve your developer workflow.
Your AI-powered workflow may make use of more than one LLMs. Go for it. But we’ve done a good job of putting Gemini into nearly every stage of the new way of working. Let’s look at what you can do RIGHT NOW to build with Gemini.
Build knowledge, plans, and prototypes with Gemini
Are you still starting your learning efforts with a Google search? Amateurs 🙂 I mean, keep doing those so that we earn ad dollars. But you’ve got so many new ways to augment a basic search.
Gemini Deep Research is pretty amazing. Part of Gemini Advanced, it takes your query, searches the web on your behalf, and gives you a summary in minutes. Here I asked for help understanding the landscape of PostgreSQL providers, and it recapped results found in 240+ relevant websites from vendors, Reddit, analyst, and more.
Gemini Deep Research creating a report about the PostgreSQL landscape
You’ve probably heard of NotebookLM. Built with Gemini 2.0, it takes all sorts of digital content and helps you make sense of it. Including those hyper-realistic podcasts (“Audio Overviews”).
Planning your work or starting to flesh out a prototype? For free, Google AI Studio lets you interact with the latest Gemini models. Generate text, audio, or images from prompts. Produce complex codebases based on reference images or text prompts. Share your desktop and get live assistance on whatever task you’re doing. It’s pretty rad.
Google AI Studio’s Live API makes it possible to interact live with the model
Google Cloud customers can get knowledge from Gemini in a few ways. The chat for Gemini Cloud Assist gives me an ever-present agent that can help answer questions or help me explore options. Here, I asked for a summary of the options for running PostgreSQL in Google Cloud. It breaks the response down by fully-managed, self-managed, and options for migration.
Chat for Gemini Code Assist teaches me about PostgreSQL options
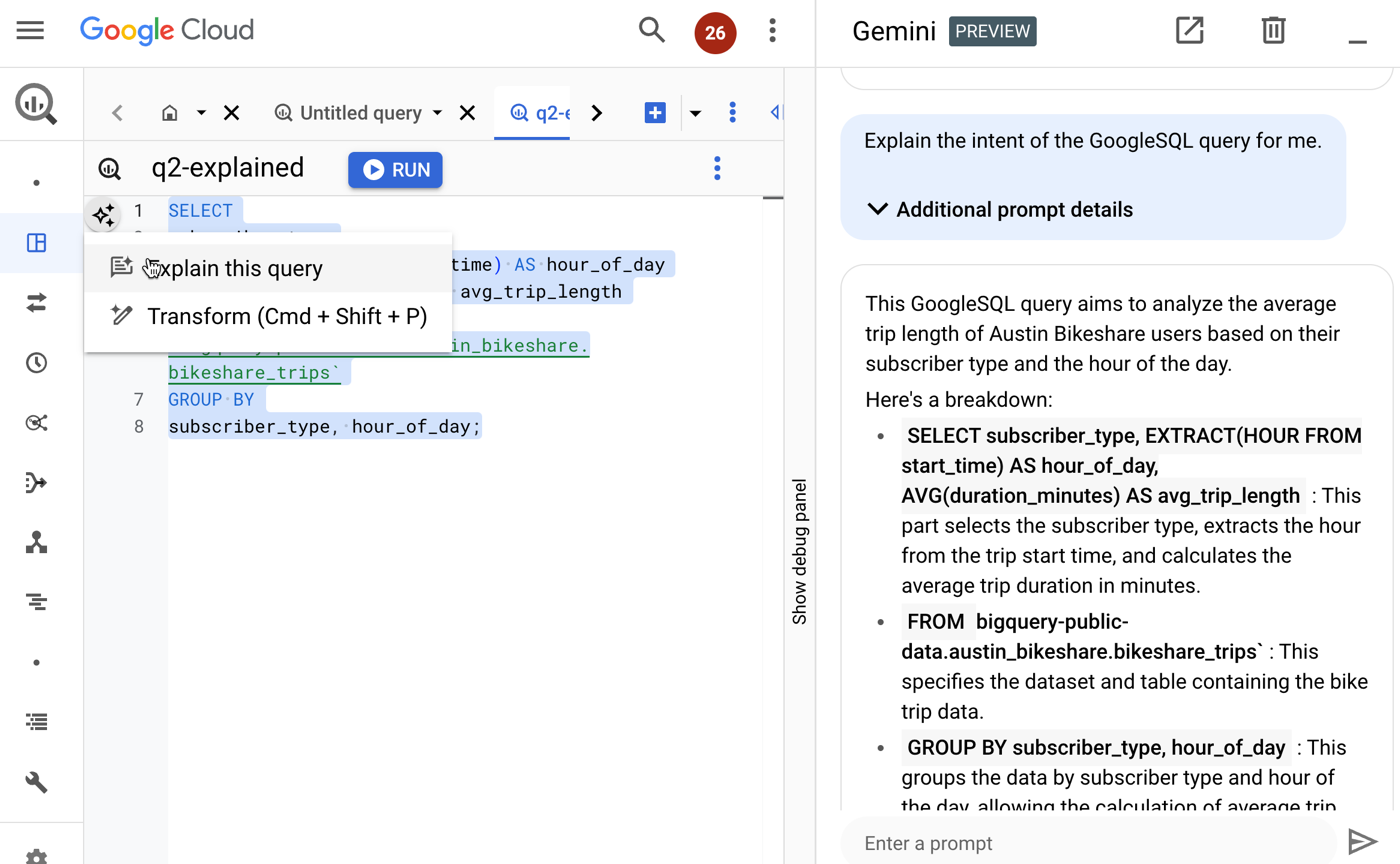
Gemini for Google Cloud blends AI-assistance into many different services. One way to use this is to understand existing SQL scripts, workflows, APIs, and more.
Gemini in BigQuery explains an existing query and helps me learn about it
Trying to plan out your next bit of work? Google AI Studio or Vertex AI Studio can assist here too. In either service, you can pass in your backlog of features and bugs, maybe an architecture diagram or two, and even some reference PDFs, and ask for help planning out the next sprint. Pretty good!
Vertex AI Studio “thinking” through a sprint plan based on multi-modal input
Build apps and agents with Gemini
We can use Google AI Studio or Vertex AI Studio to learn things and craft plans, but now let’s look at how you’d actually build apps with Gemini.
You can work with the raw Gemini API. There are SDK libraries for Python, Node, Go, Dart, Swift, and Android. If you’re working with Gemini 2.0 and beyond, there’s a new unified SDK that works with both the Developer API and Enterprise API (Vertex). It’s fairly easy to use. I wrote a Google Cloud Function that uses the unified Gemini API to generate dinner recipes for whatever ingredients you pass in.
package function
import (
"context"
"encoding/json"
"fmt"
"log"
"net/http"
"os"
"github.com/GoogleCloudPlatform/functions-framework-go/functions"
"google.golang.org/genai"
)
func init() {
functions.HTTP("GenerateRecipe", generateRecipe)
}
func generateRecipe(w http.ResponseWriter, r *http.Request) {
ctx := context.Background()
ingredients := r.URL.Query().Get("ingredients")
if ingredients == "" {
http.Error(w, "Please provide ingredients in the query string, like this: ?ingredients=pork, cheese, tortilla", http.StatusBadRequest)
return
}
projectID := os.Getenv("PROJECT_ID")
if projectID == "" {
projectID = "default" // Provide a default, but encourage configuration
}
location := os.Getenv("LOCATION")
if location == "" {
location = "us-central1" // Provide a default, but encourage configuration
}
client, err := genai.NewClient(ctx, &genai.ClientConfig{
Project: projectID,
Location: location,
Backend: genai.BackendVertexAI,
})
//add error check for err
if err != nil {
log.Printf("error creating client: %v", err)
http.Error(w, "Failed to create Gemini client", http.StatusInternalServerError)
return
}
prompt := fmt.Sprintf("Given these ingredients: %s, generate a recipe.", ingredients)
result, err := client.Models.GenerateContent(ctx, "gemini-2.0-flash-exp", genai.Text(prompt), nil)
if err != nil {
log.Printf("error generating content: %v", err)
http.Error(w, "Failed to generate recipe", http.StatusServiceUnavailable)
return
}
if len(result.Candidates) == 0 {
http.Error(w, "No recipes found", http.StatusNotFound) // Or another appropriate status
return
}
recipe := result.Candidates[0].Content.Parts[0].Text // Extract the generated recipe text
response, err := json.Marshal(map[string]string{"recipe": recipe})
if err != nil {
log.Printf("error marshalling response: %v", err)
http.Error(w, "Failed to format response", http.StatusInternalServerError)
return
}
w.Header().Set("Content-Type", "application/json")
w.Write(response)
}
What coding tools can I use with Gemini? GitHub Copilot now supports Gemini models. Folks who love Cursor can choose Gemini as their underlying model. Same goes for fans of Sourcegraph Cody. Gemini Code Assist from Google Cloud puts AI-assisted tools into Visual Studio Code and the JetBrains IDEs. Get the power of Gemini’s long context, personalization on your own codebase, and now the use of tools to pull data from Atlassian, GitHub, and more. Use Gemini Code Assist within your local IDE, or in hosted environments like Cloud Workstations or Cloud Shell Editor.
Gemini Code Assist brings AI assistance to your dev workspace, including the use of tools
Project IDX is another Google-provided dev experience for building with Gemini. Use it for free, and build AI apps, with AI tools. It’s pretty great for frontend or backend apps.
Project IDX lets you build AI apps with AI tools
Maybe you’re building apps and agents with Gemini through low-code or declarative tools? There’s the Vertex AI Agent Builder. This Google Cloud services makes it fairly simple to create search agents, conversational agents, recommendation agents, and more. No coding needed!
Conversational agents in the Vertex AI Agent Builder
Another options for building with Gemini is the declarative Cloud Workflows service. I built a workflow that calls Gemini through Vertex AI and summarizes any provided document.
# Summarize a doc with Gemini
main:
params: [args]
steps:
- init:
assign:
- doc_url: ${args.doc_url}
- project_id: ${args.project_id}
- location: ${args.location}
- model: ${args.model_name}
- desired_tone: ${args.desired_tone}
- instructions:
- set_instructions:
switch:
- condition: ${desired_tone == ""}
assign:
- instructions: "Deliver a professional summary with simple language."
next: call_gemini
- condition: ${desired_tone == "terse"}
assign:
- instructions: "Deliver a short professional summary with the fewest words necessary."
next: call_gemini
- condition: ${desired_tone == "excited"}
assign:
- instructions: "Deliver a complete, enthusiastic summary of the document."
next: call_gemini
- call_gemini:
call: googleapis.aiplatform.v1.projects.locations.endpoints.generateContent
args:
model: ${"projects/" + project_id + "/locations/" + location + "/publishers/google/models/" + model}
region: ${location}
body:
contents:
role: user
parts:
- text: "summarize this document"
- fileData:
fileUri: ${doc_url}
mimeType: "application/pdf"
systemInstruction:
role: user
parts:
- text: ${instructions}
generation_config: # optional
temperature: 0.2
maxOutputTokens: 2000
topK: 10
topP: 0.9
result: gemini_response
- returnStep:
return: ${gemini_response.candidates[0].content.parts[0].text}
Similarly, its sophisticated big-brother, Application Integration, can also interact with Gemini through drag-and-drop integration workflows. These sorts of workflow tools help you bake Gemini predictions into all sorts of existing processes.
Google Cloud Application Integration calls Gemini models
After you build apps and agents, you need a place to host them! In Google Cloud, you’ve could run in a virtual machine (GCE), Kubernetes cluster (GKE), or serverless runtime (Cloud Run). There’s also the powerful Firebase App Hosting for these AI apps.
There are also two other services to consider. For RAG apps, we now offer the Vertex AI RAG Engine. I like this because you get a fully managed experience for ingesting docs, storing in a vector database, and performing retrieval. Doing LangChain? LangChain on Vertex AI offers a handy managed environment for running agents and calling tools.
Build AI and data systems with Gemini
In addition to building straight-up agents or apps, you might build backend data or AI systems with Gemini.
If you’re doing streaming analytics or real-time ETL with Dataflow, you can build ML pipelines, generate embeddings, and even invoke Gemini endpoints for inference. Maybe you’re doing data analytics with frameworks like Apache Spark, Hadoop, or Apache Flink. Dataproc is a great service that you can use within Vertex AI, or to run all sorts of data workflows. I’m fairly sure you know what Colab is, as millions of folks per month use it for building notebooks. Colab and Colab Enterprise offer two great ways to build data solutions with Gemini.
I made a dataset from the public “release notes” dataset from Google Cloud. Then I made a reference to the Gemini 2.0 Flash model, and then asked Gemini for a summary of all a product’s release notes from the past month.
-- create the remote model
CREATE OR REPLACE MODEL
`[project].public_dataset.gemini_2_flash`
REMOTE WITH CONNECTION `projects/[project]/locations/us/connections/gemini-connection`
OPTIONS (ENDPOINT = 'gemini-2.0-flash-exp');
-- query an aggregation of responses to get a monthly product summary
SELECT *
FROM
ML.GENERATE_TEXT(
MODEL `[project].public_dataset.gemini_2_flash`,
(
SELECT CONCAT('Summarize this month of product announcements by rolling up the key info', monthly_summary) AS prompt
FROM (
SELECT STRING_AGG(description, '; ') AS monthly_summary
FROM `bigquery-public-data`.`google_cloud_release_notes`.`release_notes`
WHERE product_name = 'AlloyDB' AND DATE(published_at) BETWEEN '2024-12-01' AND '2024-12-31'
)
),
STRUCT(
.05 AS TEMPERATURE,
TRUE AS flatten_json_output)
)
How wild is that? Love it.
You can also build with Gemini in Looker. Build reports, visualizations, and use natural language to explore data. See here for more.
And of course, Vertex AI helps you build with Gemini. Build prompts, fine-tune models, manage experiments, make batch predictions, and lots more. If you’re working with AI models like Gemini, you should give Vertex AI a look.
Build a better day-2 experience with Gemini
It’s not just about building software with Gemini. The AI-driven product workflow extends to post-release activities.
Have to set up least-privilege permissions for service accounts? Build the right permission profile with Gemini.
The “Help me choose roles” feature uses Gemini to figure out the right permissions
Something goes wrong. You need to get back to good. You can build faster resolution plans with Gemini. Google Cloud Logging supports log summarization with Gemini.
Google Cloud Logging supports log summarization with Gemini
Ideally, you know when something goes wrong before your customers notice. Synthetic monitors are one way to solve that. We made it easy to build synthetic monitors with Gemini using natural language.
“Help me code” option for creating synthetic monitors in Cloud Monitoring
Gemini can also help you build billing reports. I like this experience where I can use natural language to get answers about my spend in Cloud Billing.
Gemini in Cloud Billing makes it easier to understand your spend
Build supporting digital assets with Gemini
The developer workflow isn’t just about code artifacts. Sometimes you create supporting assets for design docs, production runbooks, team presentations, and more.
Use the Gemini app (or our other AI surfaces) to generate images. I do this all the time now!
Image for use in a presentation is generated by Gemini
Building slides? Writing docs? Creating spreadsheets? Gemini for Workspace gives you some help here. I use this on occasion to refine text, generate slides or images, and update tables.
Gemini in Google Docs helps me write documents
Maybe you’re getting bored with static image representations and want some more videos in your life? Veo 2 is frankly remarkable and might be a new tool for your presentation toolbox. Consider a case where you’re building a mobile app that helps people share cars. Maybe produce a quick video to embed in the design pitch.
Veo 2 generating videos for use in a developer’s design pitch
AI disrupts the traditional product development workflow. Good! Gemini is part of each stage of the new workflow, and it’s only going to get better. Consider introducing one or many of these experiences to your own way of working in 2025.
You don’t have to use generative AI. It’s possible to avoid it and continue doing whatever you’ve been doing, the way you’ve been doing it. I don’t believe that sentence will be true in twelve months. Not because you’ll have to use it—although in some cases it may be unavoidable—but because you’ll want to use it. I thought about how my work will change next year.
#1. I’ll start most efforts by asking “can AI help with this?”
Do I need to understand a new market or product area? Analyze a pile of data? Schedule a complex series of meetings? Quickly generate a sample app for a customer demo? Review a blog post a teammate wrote? In most cases, AI can give me an assist. I want to change my mental model to first figure out if there’s a smarter (Ai-assisted) way to do something.
That said, it’s about “can AI help me” versus “can AI do all my work.” I don’t want to end up in this situation.
Whether planning a strategy or a vacation, there’s a lot of time spent researching. That’s ok, as you often uncover intriguing new tangents while exploring the internet.
AI can still improve the process. A lot. I find myself using the Gemini app, Google AI Studio, and NotebookLM to understand complex ideas. Gemini Deep Research is almost unbelievable. Give it a prompt, it scours the web for dozens or hundreds of sources, and then compiles a report.
What an amazing way to start or validate research efforts. Have an existing pile of content—might be annual reports, whitepapers, design docs, or academic material—that you need to make sense of? NotebookLM is pretty amazing, and should change how all of us ask questions of research material.
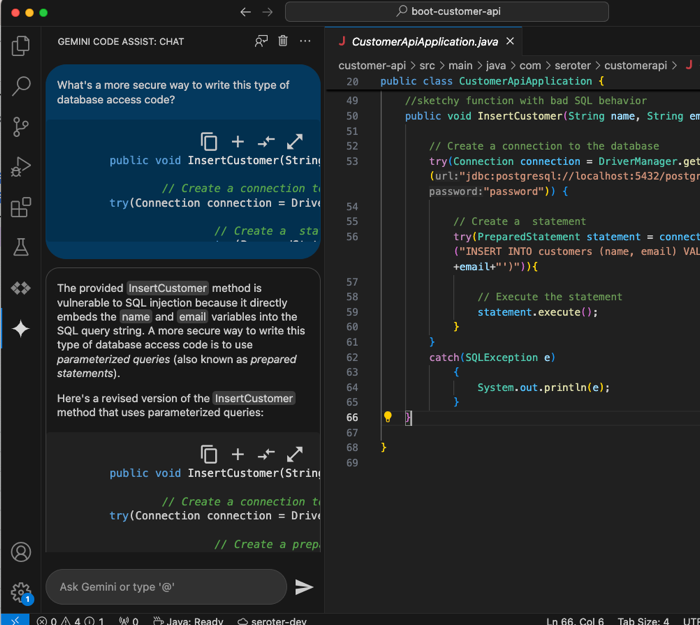
And then with coding assistance tools, I also am getting more and more comfortable staying in my IDE to get help on things I don’t yet know. Here, my Gemini Code Assist extension is helping me learn how to fix my poorly-secured Java code.
Finally, I’m quite intrigued by how the new Gemini 2.0 Multimodal Live API will help me in the moment. By sharing my screen with the model, I can get realtime help into whatever I’m struggling with. Wow.
My day job is to lead a sizable team at Google Cloud and help everyone do their best work. I still like to code, though!
it’s already happening, but next year I expect to code more than in years past. Why? Because AI is making easier and more fun. Whether using an IDE assistant, or a completely different type of IDE like Cursor, it’s never been simpler to build legit software. We all can go from idea to reality so quickly now.
Stop endlessly debating ideas, and just test them out quickly! Using lowcode platforms or AI assisted coding tools, you can get working prototypes in no time.
#5. I will ask better questions.
I’ve slowly learned that the best leaders simply ask better questions. AI can help us a few ways here. First, there are “thinking” models that show you a chain of thought that might inspire your own questions.
LLMs are awesome at giving answers, but they’re also pretty great at crafting questions. Look at this. I uploaded a set of (fake) product bugs and asked the Gemini model to help me come up with clarifying questions to ask the engineers. Good list!
And how about this. Google Cloud BigQuery has an excellent feature called Data Insights which generates a bunch of candidate questions for a given dataset (here, the Google Cloud Release Notes). What a great way to get some smart, starter questions to consider!
#6. I want to identify where the manual struggle is actually the point.
I don’t want AI to do everything for me. There are cases where the human struggle is where the enjoyment comes from. Learning how to do something. Fumbling with techniques. Building up knowledge or strength. I don’t want a shortcut. I want deep learning.
I’m going to keep doing my daily reading list by hand. No automation allowed, as it forces me to really get a deeper grasp on what’s going on in our industry. I’m not using AI to write newsletters, as I want to keep working on the writing craft myself.
This mass integration of AI into services and experiences is great. It also forces us to stop and decide where we intentionally want to avoid it!
#7. I should create certain types of content much faster.
There’s no excuse to labor over document templates or images in presentations anymore. No more scouring the web for the perfect picture.
I use Gemini in Google Slides all the time now. This is the way I add visuals to presentations and it saves me hours of time.
But videos too? I’m only starting to consider how to use remarkable technology like Veo 2. I’m using it now, and it’s blowing my mind. It’ll likely impact what I produce next year.
That’s what most of this is all about. I don’t want to do less work; I want to do better work. Even with all this AI and automation, I expect I’ll be working the same number of hours next year. But I’ll be happier with how I’m spending those hours: learning, talking to humans, investing in others. Less time writing boilerplate code, breaking flow state to get answers, or even executing mindlessly repetitive tasks in the browser.
The ability to use your own codebase to customize the suggestions from an AI coding assist is a big deal. This feature—available in products like Gemini Code Assist, GitHub Copilot, and Tabnine—gives developers coding standards, data objects, error messages, and method signatures that they recognize from previous projects. Data shows that the acceptance rate for AI coding assistants goes way up when devs get back trusted results that look familiar. But I don’t just want up-to-date and familiar code that *I* wrote. How can I make sure my AI coding assistant gives me the freshest and best code possible? I used code customization in Gemini Code Assist to reference Google Cloud’s official code sample repos and now I get AI suggestions that feature the latest Cloud service updates and best practices for my preferred programming languages. Let me show you how I did it.
Last month, I showed how to use local codebase awareness in Gemini Code Assist (along with its 128,000 input token window) to “train” the model on the fly using code samples or docs that an LLM hasn’t been trained on yet. It’s a cool pattern, but also requires upfront understanding of what problem you want to solve, and work to stash examples into your code repo. Can I skip both steps?
Yes, Gemini Code Assist Enterprise is now available and I can point to existing code repos in GitHub or GitLab. When I reference a code repo, Google Cloud automatically crawls it, chunks it up, and stores it (encrypted) in a vector database within a dedicated project in my Google Cloud environment. Then, the Gemini Code Assist plugin uses that data as part of a RAG pattern when I ask for coding suggestions. By pointing at Google Cloud’s code sample repos—any best practice repo would apply here—I supercharge my recommendations with data the base LLM doesn’t have (or prioritize).
Step #0 – Prerequisites and considerations
Code customization is an “enterprise” feature of Gemini Code Assist, so it requires a subscription to that tier of service. There’s a promotional $19-per-month price until March of 2025, so tell your boss to get moving.
Also, this is currently available in US, European, and Asian regions, you may need to request geature access via a form (depending on when you read this), and today it works with GitHub.com and GitLab.com repos, although on-premises indexing is forthcoming. Good? Good. Let’s keep going.
Step #1 – Create the source repo
One wrinkle here is that you need to own the repos you ask Gemini Code Assist to index. You can’t just point at any random repo to index. Deal breaker? Nope.
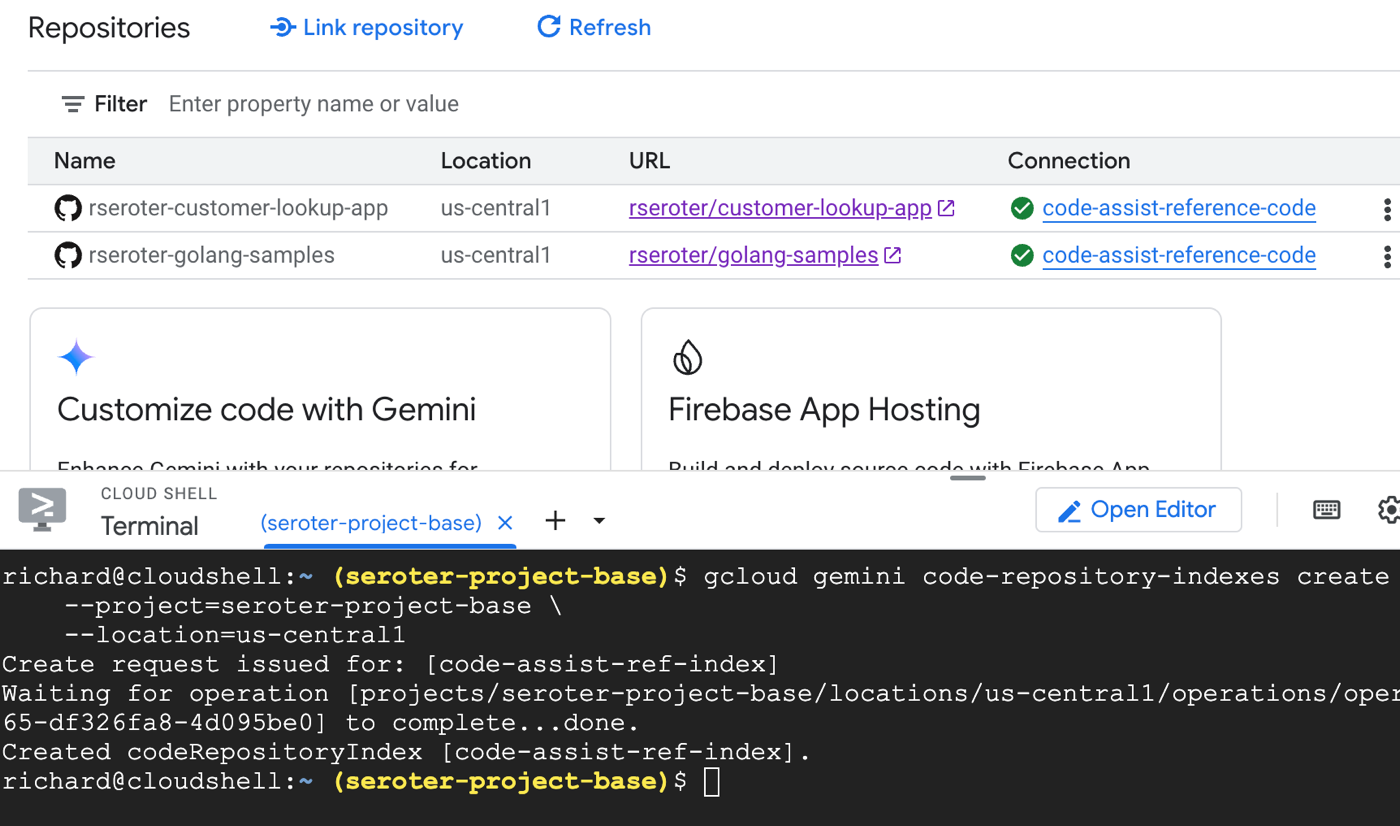
I can just fork an existing repo into my own account! For example, here’s the Go samples repo from Google Cloud, and the Java one. Each one is stuffed with hundreds of coding examples for interacting with most of Google Cloud’s services. These repos are updated multiple times per week to ensure they include support for all the latest Cloud service features.
I went ahead and forked each repo in GitHub. You can do it via the CLI or in the web console.
I didn’t overthink it and kept the repository name the same.
Gemini Code Assist can index up to 950 repos (and more if really needed), so you could liberally refer to best-practice repos that will help your developers write better code.
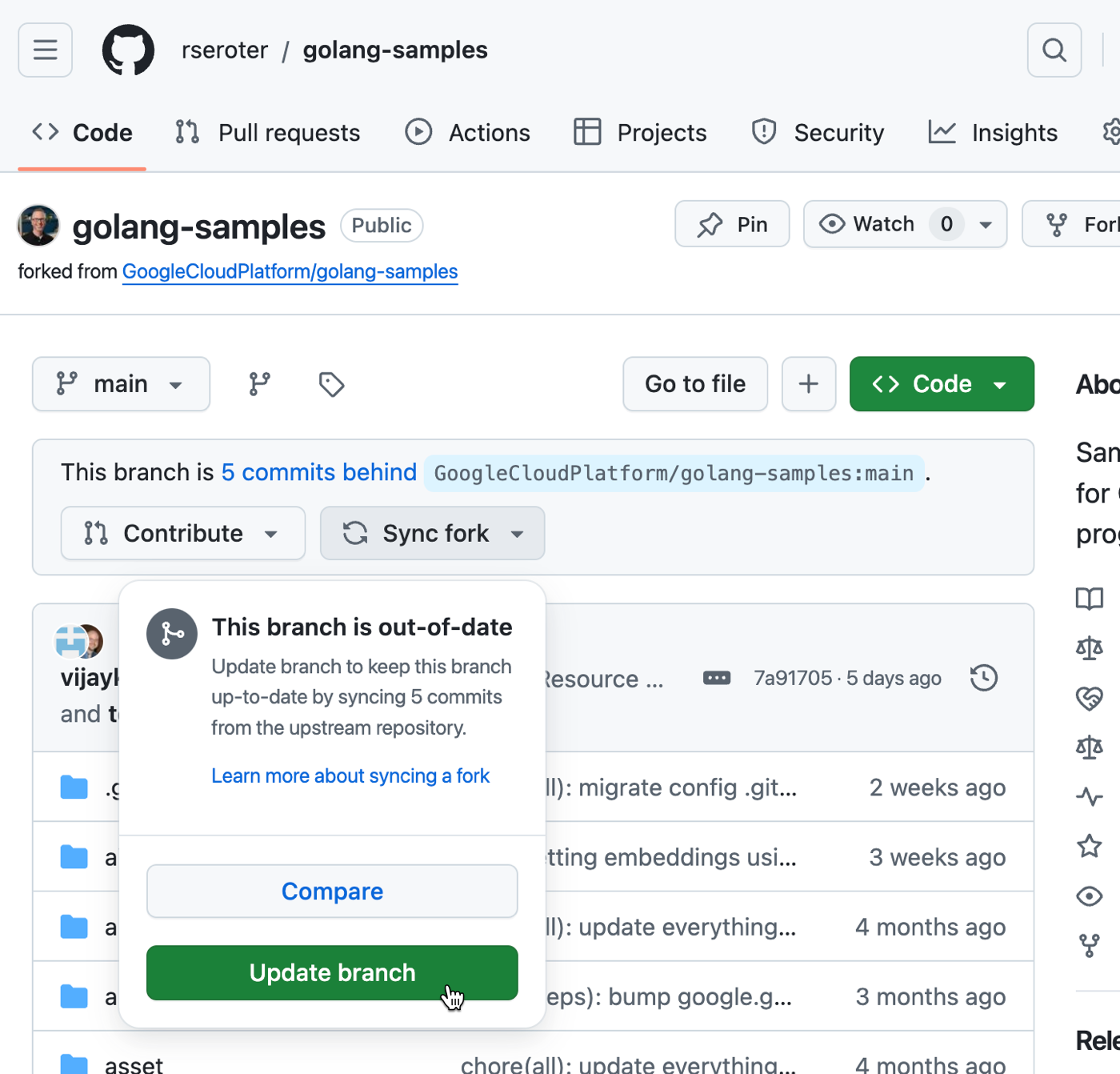
Any time I want to refresh my fork to grab the latest code sample updates, I can do so.
Step #2 – Add a reference to the source repo
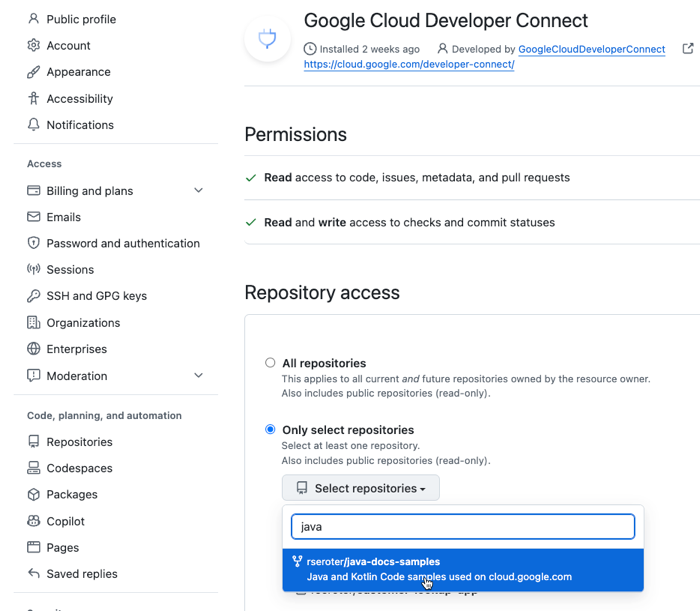
Now I needed to reference these repos for later code customization. Google Cloud Developer Connect is a service that maintains connections to source code sitting outside Google Cloud.
I started by choosing GitHub.com as my source code environment.
Then I named my Developer Connect connection.
Then I installed a GitHub app into my GitHub account. This app is what enables the loading of source data into the customization service. From here, I chose the specific repos that I wanted available to Developer Connect.
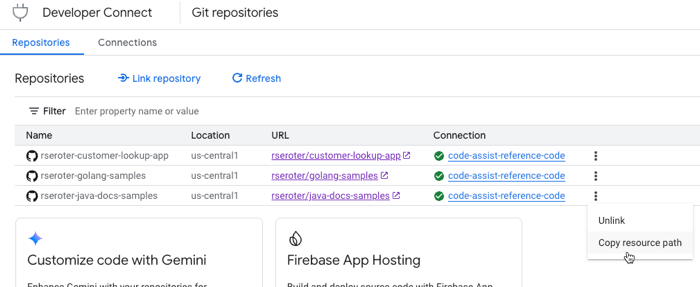
When finished, I had one of my own repos, and two best practice repos all added to Developer Connect.
That’s it! Now to point these linked repos to Gemini Code Assist.
Step #3 – Add a Gemini Code Assist customization index
I had just two CLI commands to execute.
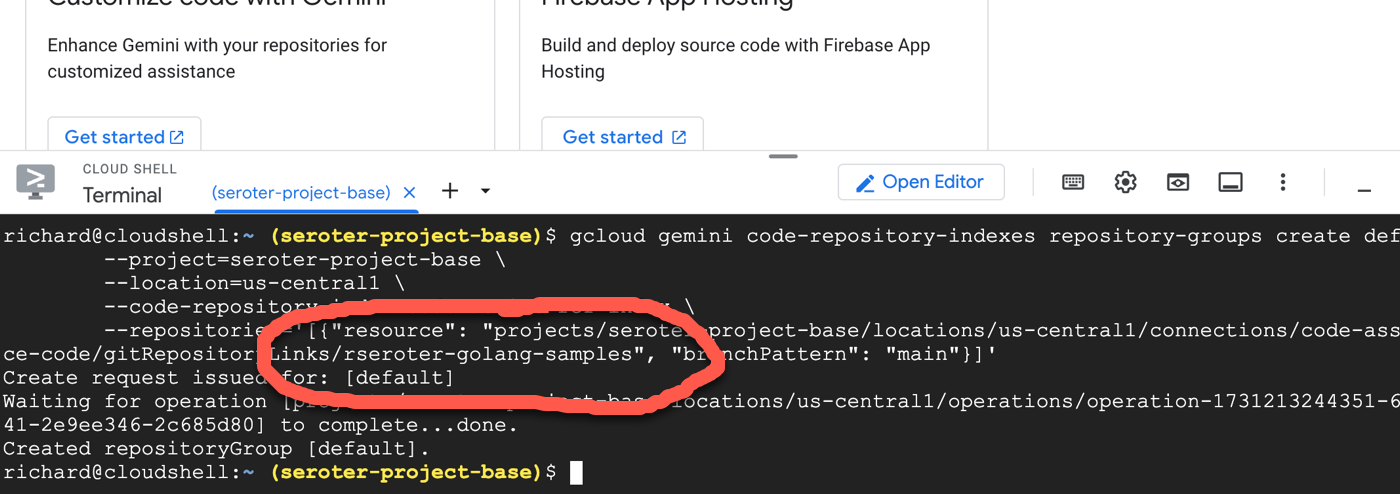
First, I created a code customization index. You’ve got one index per Cloud project (although you can request more) and you create it with one command.
Next, I created a repository group for the index. You use these to control access to repos, and could have different ones for different dev audiences. Here’s where you actually point to a given repo that has the Developer Connect app installed.
I ran this command a few times to ensure that each of my three repos was added to the repository group (and index).
Indexing can take up to 24 hours, so here’s where you wait. After a day, I saw that all my target repos were successfully indexed.
Whenever I sync the fork with the latest updates to code samples, Gemini Code Assist will index the updated code automatically. And my IDE with Gemini Code Assist will have the freshest suggestions from our samples repo!
Step #4 – Use updated coding suggestions
Let’s prove that this worked.
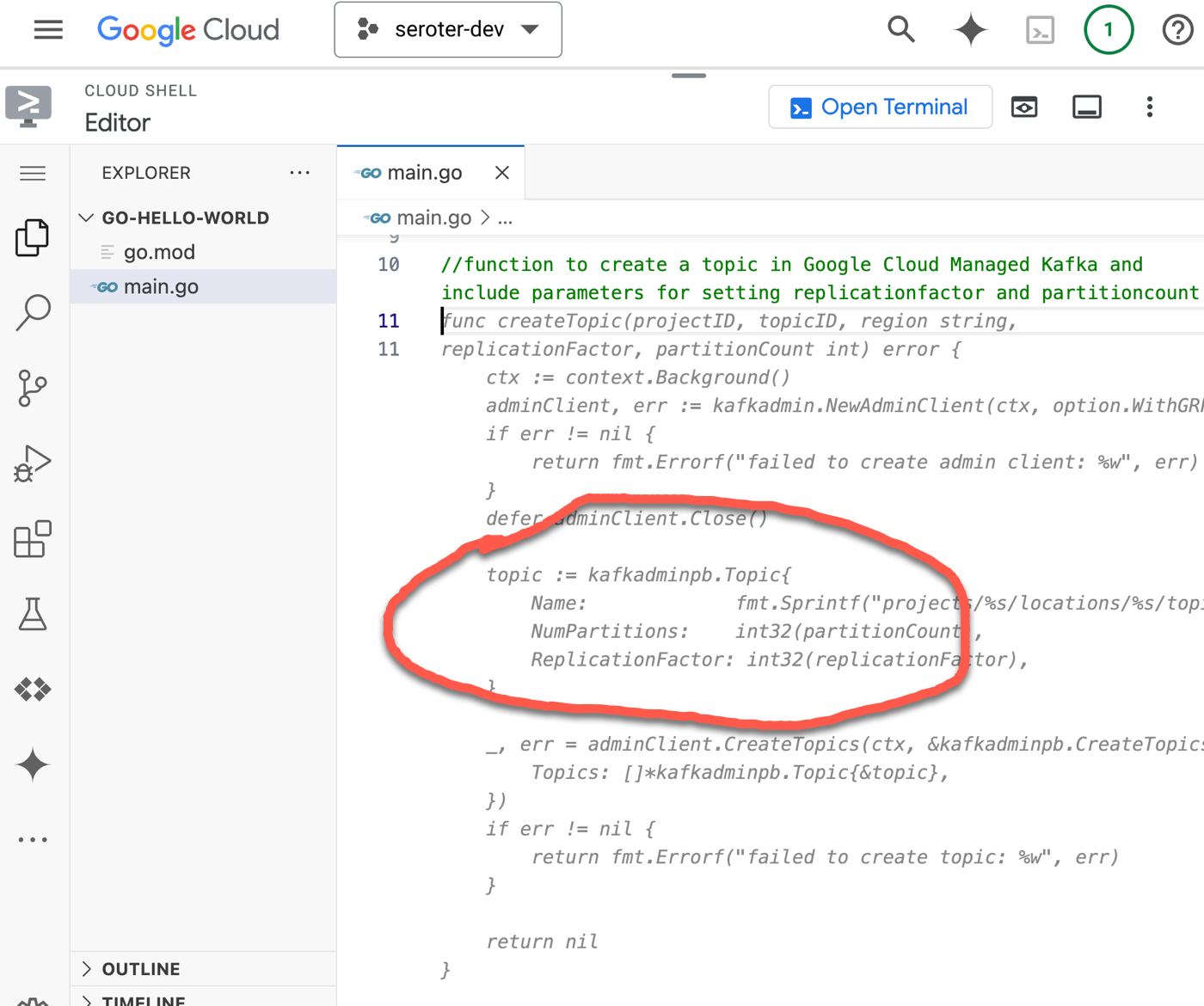
I looked for a recent commit to the Go samples repos that the base Gemini Code Assist LLM wouldn’t know about yet. Here’s one that has new topic-creation parameters for our Managed Kafka service. I gave the prompt below to Gemini Code Assist. First, I used a project and account that was NOT tied to the code customization index.
//function to create a topic in Google Cloud Managed Kafka and include parameters for setting replicationfactor and partitioncount
The coding suggestion was good, but incomplete as it was missing the extra configs the service can now accept.
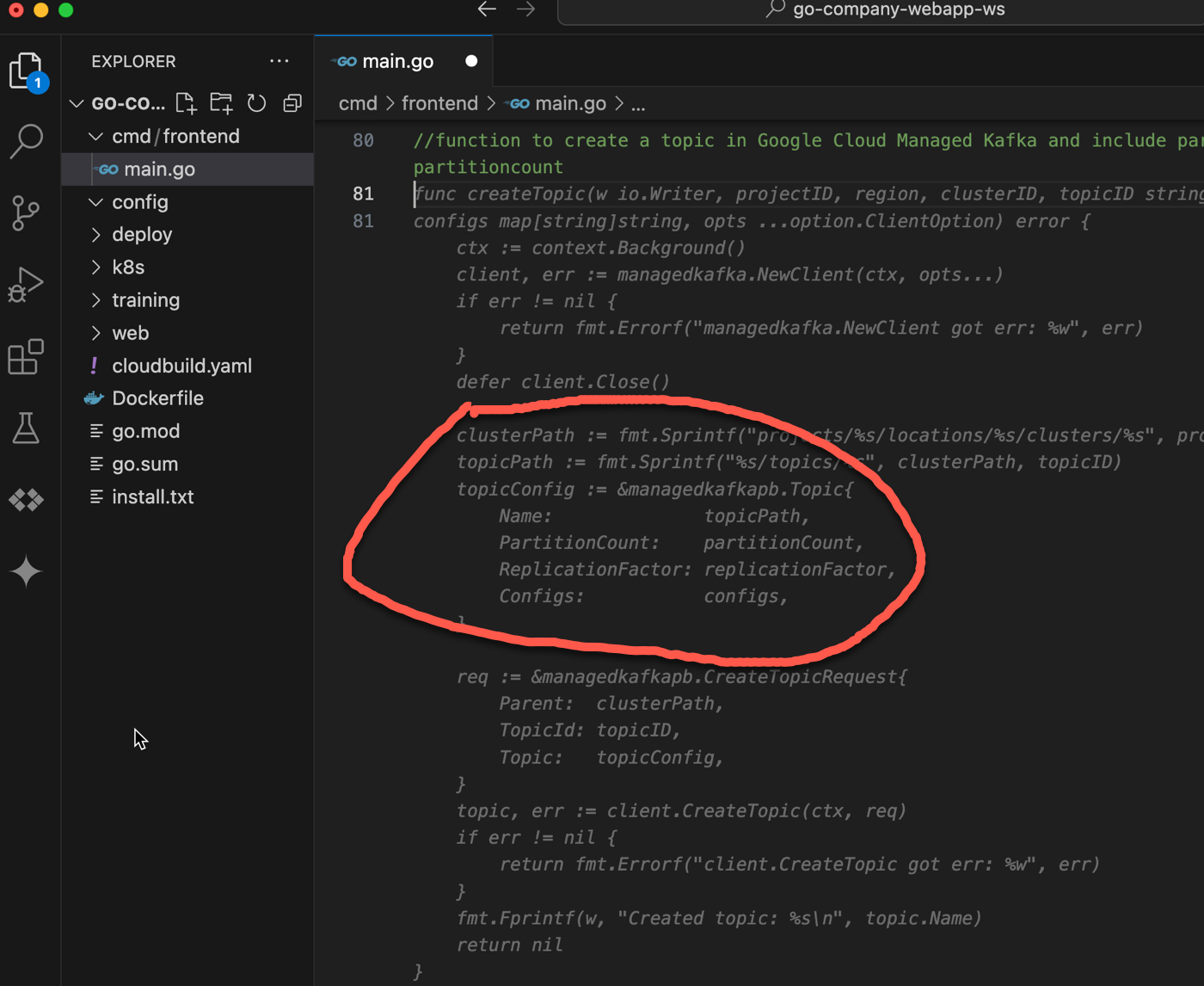
When I went to my Code Assist environment that did have code customization turned on, you see that the same prompt gave me a result that mirrored the latest Go sample code.
I tried a handful of Java and Go prompts, and I regularly (admittedly, not always) got back exactly what I wanted. Good prompt engineering might have helped me reach 100%, but I still appreciated the big increase in quality results. It was amazing to have hundreds of up-to-date Google-tested code samples to enrich my AI-provided suggestions!
AI coding assistants that offer code customization from your own repos are a difference maker. But don’t stop at your own code. Index other great code repos that represent the coding standards and fresh content your developers need!
Do you happen to subscribe my daily reading list? If you don’t, that’s ok. We’re still friends.
I shared a lot of links last week, and maybe it’s easier to listen to an audio recap instead. I just fed in last week’s reading list (all five days) to NotebookLM and generated a 20 minute engaging podcast. Great summary and analysis. Listen!