Earlier this year, I took a look at how Microsoft Azure supports Java/Spring developers. With my change in circumstances, I figured it was a good time to dig deep into Google Cloud’s offerings for Java developers. What I found was a very impressive array of tools, services, and integrations. More than I thought I’d find, honestly. Let’s take a tour.
Local developer environment
What stuff goes on your machine to make it easier to build Java apps that end up on Google Cloud?
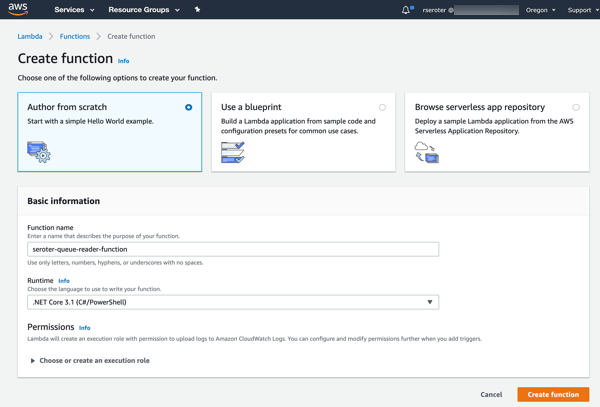
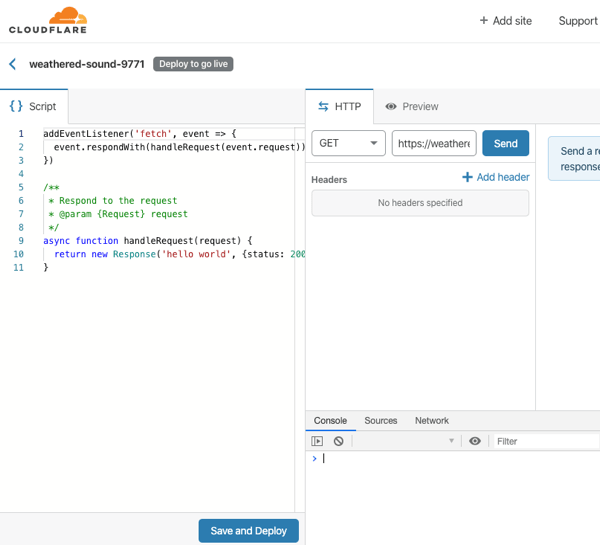
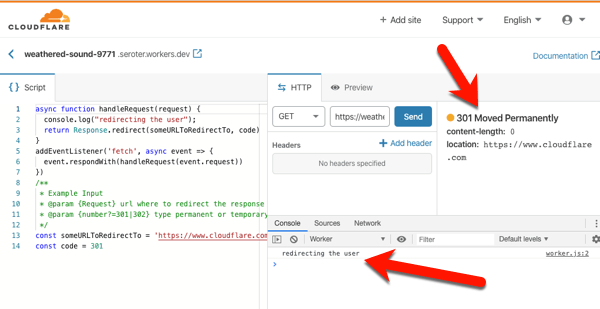
Cloud Code is a good place to start. Among other things, it delivers extensions to IntelliJ and Visual Studio Code. For IntelliJ IDEA users, you get starter templates for new projects, snippets for authoring relevant YAML files, tool windows for various Google Cloud services, app deployment commands, and more. Given that 72% of Java developers use IntelliJ IDEA, this extension helps many folks.

The Visual Studio Code extension is pretty great too. It’s got project starters and other command palette integrations, Activity Bar entries to manage Google Cloud services, deployment tools, and more. 4% of Java devs use Visual Studio Code, so, we’re looking out for you too. If you use Eclipse, take a look at the Cloud Tools for Eclipse.
The other major thing you want locally is the Cloud SDK. Within this little gem you get client libraries for your favorite language, CLIs, and emulators. This means that as Java developers, we get a Java client library, command line tools for all-up Google Cloud (gcloud), Big Query (bq) and Storage (gsutil), and then local emulators for cloud services like Pub/Sub, Spanner, Firestore, and more. Powerful stuff.
App development
Our machine is set up. Now we need to do real work. As you’d expect, you can use all, some, or none of these things to build your Java apps. It’s an open model.
Java devs have lots of APIs to work with in the Google Cloud Java client libraries, whether talking to databases or consuming world-class AI/ML services. If you’re using Spring Boot—and the JetBrains survey reveals that the majority of you are—then you’ll be happy to discover Spring Cloud GCP. This set of packages makes it super straightforward to interact with terrific managed services in Google Cloud. Use Spring Data with cloud databases (including Cloud Spanner and Cloud Firestore), Spring Cloud Stream with Cloud Pub/Sub, Spring Caching with Cloud Memorystore, Spring Security with Cloud IAP, Micrometer with Cloud Monitoring, and Spring Cloud Sleuth with Cloud Trace. And you get the auto-configuration, dependency injection, and extensibility points that make Spring Boot fun to use. Google offers Spring Boot starters, samples, and more to get you going quickly. And it works great with Kotlin apps too.

As you’re building Java apps, you might directly use the many managed services in Google Cloud Platform, or, work with the emulators mentioned above. It might make sense to work with local emulators for things like Cloud Pub/Sub or Cloud Spanner. Conversely, you may decide to spin up “real” instance of cloud services to build apps using Managed Service for Microsoft Active Directory, Secret Manager, or Cloud Data Fusion. I’m glad Java developers have so many options.
Where are you going to store your Java source code? One choice is Cloud Source Repositories. This service offers highly available, private Git repos—use it directly or mirror source code code from GitHub or Bitbucket—with a nice source browser and first-party integration with many Google Cloud compute runtimes.
Building and packaging code
After you’ve written some Java code, you probably want to build the project, package it up, and prepare it for deployment.

Store your Java packages in Artifact Registry. Create private, secure artifact storage that supports Maven and Gradle, as well as Docker and npm. It’s the eventual replacement of Container Registry, which itself is a nice Docker registry (and more).
Looking to build container images for your Java app? You can write your own Dockerfiles. Or, skip docker build|push by using our open source Jib as a Maven or Gradle plugin that builds Docker images. Jib separates the Java app into multiple layers, making rebuilds fast. A new project is Google Cloud Buildpacks which uses the CNCF spec to package and containerize Java 8|11 apps.
Odds are, your build and containerization stages don’t happen in isolation; they happen as part of a build pipeline. Cloud Build is the highly-rated managed CI/CD service that uses declarative pipeline definitions. You can run builds locally with the open source local builder, or in the cloud service. Pull source from Cloud Source Repositories, GitHub and other spots. Use Buildpacks or Jib in the pipeline. Publish to artifact registries and push code to compute environments.
Application runtimes
As you’d expect, Google Cloud Platform offers a variety of compute environments to run your Java apps. Choose among:
- Compute Engine. Pick among a variety of machine types, and Windows or Linux OSes. Customize the vCPU and memory allocations, opt into auto-patching of the OS, and attach GPUs.
- Bare Metal. Choose a physical machine to host your Java app. Choose from machine sizes with as few as 16 CPU cores, and as many as 112.
- Google Kubernetes Engine. The first, and still the best, managed Kubernetes service. Get fully managed clusters that are auto scaled, auto patched, and auto repaired. Run stateless or stateful Java apps.
- App Engine. One of the original PaaS offerings, App Engine lets you just deploy your Java code without worrying about any infrastructure management.
- Cloud Functions. Run Java code in this function-as-a-service environment.
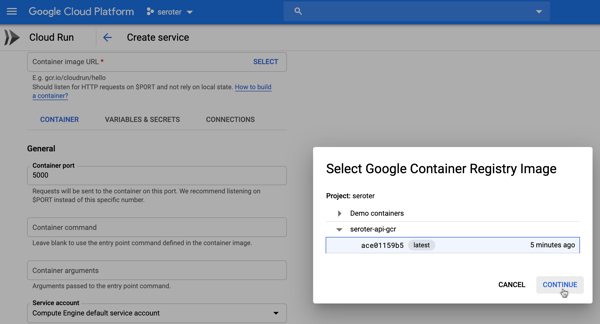
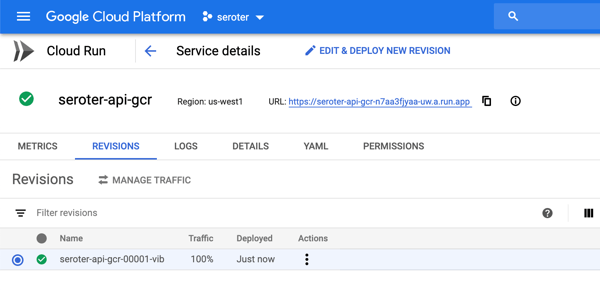
- Cloud Run. Based on the open source Knative project, Cloud Run is a managed platform for scale-to-zero containers. You can run any web app that fits into a container, including Java apps.
- Google Cloud VMware Engine. If you’re hosting apps in vSphere today and want to lift-and-shift your app over, you can use a fully managed VMware environment in GCP.
Running in production
Regardless of the compute host you choose, you want management tools that make your Java apps better, and help you solve problems quickly.
You might stick an Apigee API gateway in front of your Java app to secure or monetize it. If you’re running Java apps in multiple clouds, you might choose Google Cloud Anthos for consistency purposes. Java apps running on GKE in Anthos automatically get observability, transport security, traffic management, and SLO definition with Anthos Service Mesh.

But let’s talk about day-to-day operations of Java apps. Send Java app logs to Cloud Logging and dig into them. Analyze application health and handle alerts with Cloud Monitoring. Do production profiling of your Java apps using Cloud Profiler. Hunt for performance problems via distributed tracing with Cloud Trace. And if you need to, debug in production by analyzing the running Java code (in your IDE!) with Cloud Debugger.
Modernizing existing apps
You probably have lots of existing Java apps. Some are fairly new, others were written a decade ago. Google Cloud offers tooling to migrate many types of existing VM-based apps to container or cloud VM environments. There’s good reasons to do it, and Java apps see real benefits.
Migrate for Anthos takes an existing Linux or Windows VM and creates artifacts (Dockerfiles, Kubernetes YAML, etc) to run that workload in GKE. Migrate for Compute Engine moves your Java-hosting VMs into Google Compute Engine.
All-in-all, there’s a lot to like here if you’re a Java developer. You can mix-and-match these Google Cloud services and tools to build, deploy, run, and manage Java apps.