Famed psychologist Daniel Kahneman once said “Nothing in life is as important as you think it is, while you are thinking about it.” There’s always new tech, new trends, and a feeling of FOMO. Deep breath. You’re doing fine. Stay aware, but don’t get too hyped up with all the things around you. Keep learning by reading through today’s links below.
[blog] The Misuse of User Stories. Are you relying on user stories to plan and deliver products? This post advises against using them the wrong way.
[article] Cloud Management Issues Are Coming to a Head. Folks are having challenges with running all their environments. That’s not too surprising to me. I wonder how folks who have purposely minimized their options and focused on a rapid transition to cloud architectures are doing? Better, I assume.
[article] Open source Kubeflow 1.7 set to ‘transform’ MLops. I haven’t kept a super-close eye on this project, but it’s good to see momentum here. If you’re doing notebook management, model training, model serving and ALSO using Kubernetes, you might like this project.
[article] Simplify Day 2 Operations on GCP — Active Assist. Plenty of folks don’t want to create their own AI stuff. They just want the things they use to be smarter. Take advantage of what’s already built into the platforms and clouds that you use today.
[blog] Rolling in the deep. The days of “plan once a year” in technology seem to be coming to a close. Things change too quickly. The McDonalds engineering team talks about rolling-planning with specific rhythms for different purposes.
[blog] Jump start your future career with Google Cloud certifications. People seem to either love or loath certifications. I got MCSD certified from Microsoft years ago, and it was a good one to test myself on a topic. I didn’t see it as a job finding tool. But however you view certifications, you might want to take a look at this post about starting your cloud career by taking a cert exam.
##
Want to get this update sent to you every day? Subscribe to my RSS feed or subscribe via email below:
Whew, what a day. Still managed to read and watch some good stuff you’ll find below. Learn about platform teams, AI-washing, Kubernetes, and boosting creativity in your teams.
[blog] Top Ten Things Slowing Down Your Platform Team. If you have a platform team, you’re doing it right. But have you set them up for success? This post has good questions to ask yourself.
[article] From ‘cloud washing’ to ‘AI washing’. Unfortunately, it’s going to be on you to sift through the myriad AI-related announcements out there to discern which are legit.
[article] 5 Ways to Boost Creativity on Your Team. None of these tips are rocket science, but I still appreciate reminders and guidance for keeping our teams engaged and sharing cool ideas.
[blog] Google chip design team benefits from move to Google Cloud. People have asked me why Google doesn’t run on Google Cloud. Parts of it do, but Google Cloud itself is built upon many remarkable Google services. Here’s the story of Google one team (chip design) that’s moved into Google Cloud.
##
Want to get this update sent to you every day? Subscribe to my RSS feed or subscribe via email below:
I found a lot of good advice in today’s reading. There was useful perspective on how to think about the value of AI assistance, tips for asynchronous systems, how to build an effective incident program, and how to write good docs. Dig in!
[article] AI and the future of software development. Many folks are focused on AI generating code, but Matt points out that understanding code, or reviewing code, might be where we’ll find significant impact from LLMs.
[blog] Serverless take the wheel. Simple post, but good reminder that fully managed services continue us on a journey of offloading plumbing work and focusing on the good stuff.
[blog] Don’t Fail Publishing Events! When dealing with message brokers and databases, you need to think through a variety of scenarios. What happens if publishing fails? Should you write to the database FIRST? This post explores the topic.
[blog] Best and Worst Practices in Technical Documentation. Docs aren’t an afterthought. At least they shouldn’t be! This post has applicable advice for those trying to create or improve their documentation.
[blog] The difference between libraries and frameworks. Are you using these words in the right way? I do not. This post reminded me to tighten up my language and not use certain words interchangeably.
[article] Getting Developer Self-Service Right. Read this, and ask yourself if you’d fall into the high-performing or low-performing team bucket, and react accordingly.
##
Want to get this update sent to you every day? Subscribe to my RSS feed or subscribe via email below:
Is a serverless architecture realistic for every system? Of course not. But it’s never been easier to build robust solutions out of a bunch of fully-managed cloud services. For instance, what if I want to take uploaded files, inspect them, and route events to app instances hosted in different regions around the world? Such a solution might require a lot of machinery to set up and manage—file store, file listeners, messaging engines, workflow system, hosting infrastructure, and CI/CD products. Yikes. How about we do that with serverless technology such as:
The heart of this system is the app that processes “loan” events. The events produced by Eventarc are in the industry-standard CloudEvents format. Do I want to parse and process those events in code manually? No, no I do not. Two things will help here. First, our excellent engineers have built client libraries for every major language that you can use to process CloudEvents for various Google Cloud services (e.g. Storage, Firestore, Pub/Sub). My colleague Mete took it a step further by creating VS Code templates for serverless event-handlers in Java, .NET, Python, and Node. We’ll use those.
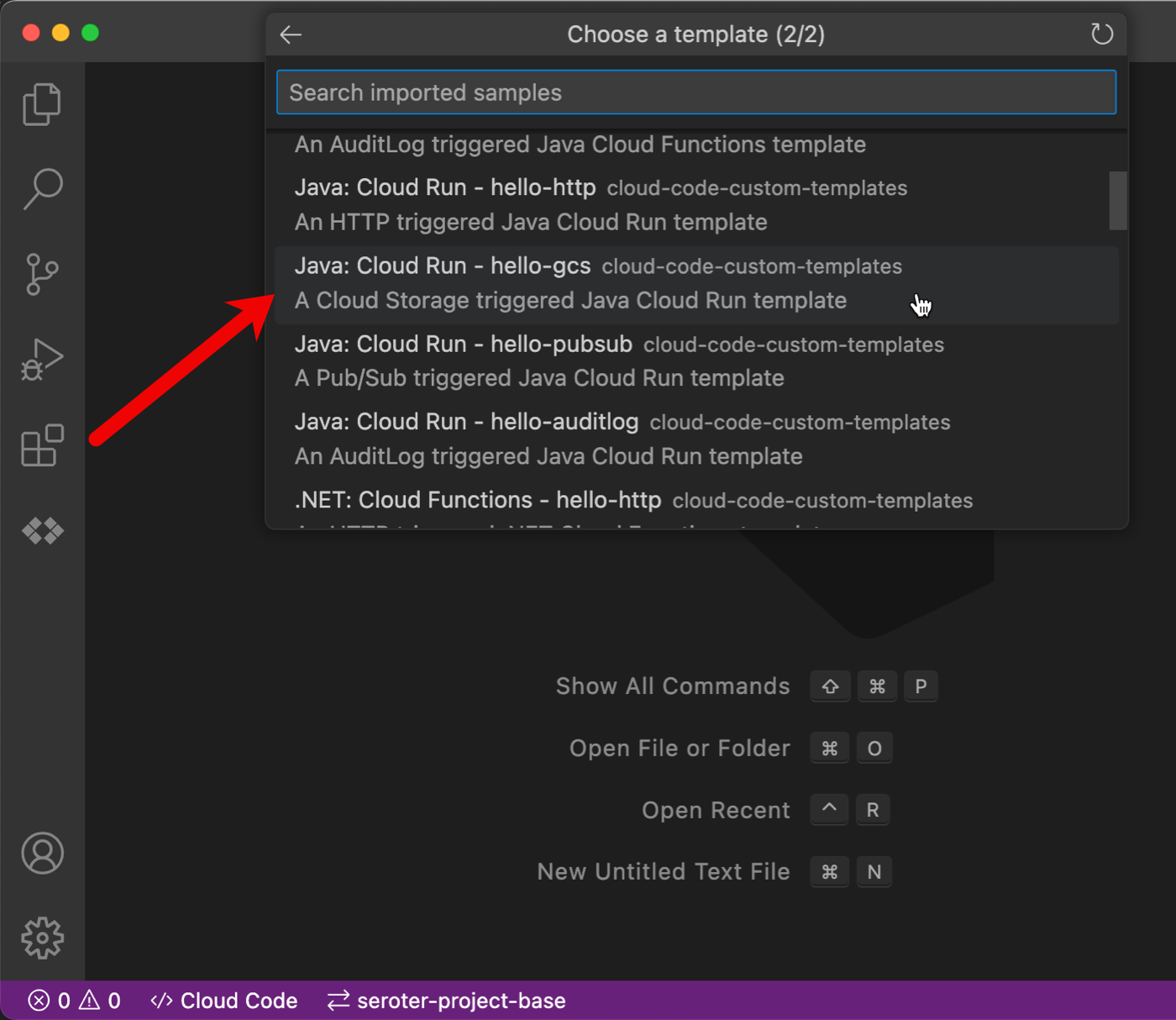
To add these templates to your Visual Studio Code environment, you start with Cloud Code, our Google Cloud extension to popular IDEs. Once Cloud Code is installed, I can click the “Cloud Code” menu and then choose the “New Application” option.
Then I chose the “Custom Application” option and “Import Sample from Repo” and added a link to Mete’s repo.
Now I have the option to pick a “Cloud Storage event” code template for Cloud Functions (traditional function as a service) or Cloud Run (container-based serverless). I picked the Java template for Cloud Run.
The resulting project is a complete Java application. It references the client library mentioned above, which you can see as google-cloudevent-types in the pom.xml file. The code is fairly straightforward and the core operation accepts the inbound CloudEvent and creates a typed StorageObjectData object.
This generated project has directions and scripts to test locally, if you’re so inclined. I went ahead and deployed an instance of this app to Cloud Run using this simple command:
gcloud run deploy --source .
That gave me a running instance, and, a container image I could use in our next step.
Step 2: Create parallel deployment of Java app to multiple Cloud Run locations
In our fictitious scenario, we want an instance of this Java app in three different regions. Let’s imagine that the internal employees in each geography need to work with a local application.
I’d like to take advantage of a new feature of Cloud Deploy, parallel deployments. This makes it possible to deploy the same workload to a set of GKE clusters or Cloud Run environments. Powerful! To be sure, the MOST applicable way to use parallel deployments is a “high availability” scenario where you’d deploy identical instances across locations and put a global load balancer in front of it. Here, I’m using this feature as a way to put copies of an app closer to specific users.
First, I need to create “service” definitions for each Cloud Run environment in my deployment pipeline. I’m being reckless, so let’s just have “dev” and “prod.”
My “dev” service definition looks like this. The “image” name can be anything, as I’ll replace this placeholder in realtime when I deploy the pipeline.
The “production” YAML service is identical except for a different service name.
Next, I need a Skaffold file that identifies the environments for my pipeline, and points to the respective YAML files that represent each environment.
The final artifact I need is a DeliveryPipeline definition. It calls out two stages (dev and prod), and for production that points to a multiTarget that refers to three Cloud Run targets.
In the Google Cloud Console, I can see my deployed pipeline with two stages and multiple destinations for production.
Now it’s time to create a release for this deployment and see everything provisioned.
The command to create a release might be included in your CI build process (whether that’s Cloud Build, GitHub Actions, or something else), or you can run the command manually. I’ll do that for this example. I named the release, gave it the name of above pipeline, and swapped the placeholder image name in my service YAML files with a reference to the container image generated by the previously-deployed Cloud Run instance.
After a few moments, I see a deployment to “dev” rolling out.
When that completed, I “promoted” the release to production and saw a simultaneous deployment to three different cloud regions.
Sweet. Once this is done, I check and see four total Cloud Run instances (one for dev, three for prod) created. I like the simplicity here for shipping the same app instance to any cloud region. For GKE clusters, this also works with Anthos environments, meaning you could deploy to edge, on-prem or other clouds as part of a parallel deploy.
We’re done with this step. I have an event-receiving app deployed around North America.
Step 3: Set up Cloud Storage bucket
This part is simple. I use the Cloud Console to create a new object storage bucket named seroter-loan-applications. We’ll assume that an application drops files into this bucket.
Step 4: Write Cloud Workflow that routes events to correct Cloud Run instance
There are MANY ways one could choose to architect this solution. Maybe you upload files to specific bucket and route directly to the target Cloud Run instance using a trigger. Or you route all bucket uploads to a Cloud Function and decide there where you’ll send it next. Plus dozens of other options. I’m going to use a Cloud Workflow that receives an event, and figures out where to send it next.
A Cloud Workflow is described with a declarative definition written in YAML or JSON. It’s got a standard library of functions, supports control flow, and has adapters to lots of different cloud services. This Workflow needs to parse an incoming CloudEvent and route to one of our three (secured) Cloud Run endpoints. I do a very simple switch statement that looks at the file name of the uploaded file, and routes it accordingly. This is a terrible idea in real life, but go with me here.
This YAML results in a workflow that looks like this:
Step 5: Configure Eventarc trigger to kick off a Cloud Workflow
Our last step is to wire up the “file upload” event to this workflow. For that, we use Eventarc. Eventarc handles the machinery for listening to events and routing them. See here that I chose Cloud Storage as my event source (there are dozens and dozens), and then the event I want to listen to. Next I selected my source bucket, and chose a destination. This could be Cloud Run, Cloud Functions, GKE, or Workflows. I chose Workflows and then my specific Workflow that should kick off.
All good. Now I have everything wired up and can see this serverless solution in action.
Step 6: Test and enjoy
Testing this solution is straightforward. I dropped three “loan application” files into the bucket, each named with a different target region.
Sure enough, three Workflows kick off and complete successfully. Clicking into one of them shows the Workflow’s input and output.
Looking at the Cloud Run logs, I see that each instance received an event corresponding to its location.
Wrap Up
No part of this solution required me to stand up hardware, worry about operating systems, or configure networking. Except for storage costs for my bucket objects, there’s no cost to this solution when it’s not running. That’s amazing. As you look to build more event-driven systems, consider stitching together some fully managed services that let you focus on what matters most.
On this Friday, I read a whole stash of interesting things. There thought-provoking content on “build versus buy”, analyzing logs in security scenarios, and helping robots navigate your living room.
[blog] Visual language maps for robot navigation. If reading this changes what you plan to do at work on Monday, I want to be friends with you. For most of us, it’s just neat research to read about.
[blog] Buy vs Build… Over Time. Good post that emphasizes opportunity cost and the context of the current situation when deciding when to build or buy a solution.
[blog] Nobody cares, train harder. Edgy post, but it resonates with me. Everyone’s got challenges and rarely is everything handed to you. If you want more, push through.
[article] What’s the Difference between Flutter and React Native? Virtually every year, I threaten to learn a frontend web framework or mobile framework, and every year I don’t. But, I still like to pay attention to what’s out there. This is a good breakdown of two popular options.
[blog] Improving Istio Propagation Delay. This is a good example of (a) why good infrastructure monitoring matters and (b) the value of open source software that you can explore and change if needed. The Airbnb engineering team walks through their experiences here.
Another day, another batch of AI-related announcements. So much going on in this space! Check out a couple related articles below, while also learning about app modernization challenges, good team cultures, and change data capture.
[blog] Cheating is All You Need. Steve Yegge is good at rants. He makes great points about the fully disruptive nature of large language models what that means to many people.
[article] Improving CI/CD Pipelines Through Observability. This isn’t something I’ve thought about very much, so it was useful to read an article about the tactics and useful metrics for a well-monitored set of pipelines.
[blog] The new Google Cloud region in Turin Italy is now open. Whenever I retire, I’ve thought about visiting every baseball stadium. Maybe I should also aim for visiting every city where Google Cloud offers a “region.”
[news] Survey Surfaces Application Modernization Challenges. Oof, tough numbers here. Level of confidence in understanding modernization effort plummets once the work starts. Lots of challenges finding people to support existing apps. More in this depressing, but important data.
Spent the day in Silicon Valley with our friends at GitLab. Was still able to consume some good content that you’ll find below.
[youtube-video] Unboxing brand new Google Bard and GPT-4. Fun video by a colleague of mine who engages in a short conversation with two generative AI experiences.
[blog] EA Principles Addendum: Build vs. Buy. This post highlights why blogs, social media, and chance interactions matter. We all learn from each other! Brian digs further into his “build vs buy” EA principle and how it’ll evolve a bit after feedback.
[blog] Technology Lifecycle. The Slack Engineering team explores the stages of an infrastructure project (e.g. alpha, active, retirement) and what to consider at each stage.
I’m on the way to the Google Cloud mothership in Sunnyvale (San Jose area) but still read a bunch of terrific things today. It includes new stuff to play with (Bard, code templates) and new ideas to chew on (product vision, testing, pragmatic pessimism).
[blog] Product Vision is Science Fiction. Excellent post that explains what a “product vision” really is, and how to generate one. And, how not to fear that you’ll be wrong. You will be.
[blog] Performance Optimization with BigQuery. Lots of very specific advice here for optimizing your data warehouse (BigQuery, in this case). It’s applicable to many products.
[article] Developers, unite! Join the fight for code quality. Is the pursuit of “quality” the most exciting thing a developer can do? I dunno. But this article lays out why it matters, and how to build momentum for a focus on quality at your company.
[blog] Extending Cloud Code with custom templates. My colleague created some very useful templates for languages like .NET and Java that make it simpler to build event-driven serverless apps. If you’re using Visual Studio Code, you can easily try it out.
[news] Awareness of Software Supply Chain Security Issues Improves. If you’ve been reading these updates, you’ve seen a lot of mentions of software supply chain security. That topic is now top of mind for a lot of technology leaders, and that’s a good thing.
Greetings. Today’s Wrap Up features a bunch of good media including some advice for getting feedback from your boss, setting up a good team structure for SREs, and reasons why serverless may work for you.
[article] Docker’s bad week. There was some messy communication from Docker last week about sunsetting their Free Teams service, but Matt focuses here on the bigger (positive) picture.
[blog] In defense of serverless. The “this computing paradigm is awful” posts are usually just click-bait, but some warrant further discussion. In this post, Hendrik answers the question of whether serverless is useful or not.
[youtube-playlist] Making Friends with Machine Learning. This is a tremendous YouTube playlist that features 100+ short videos for learning all about ML. It’s worth a listen!
[blog] Pub/Sub schema evolution is now GA. Cloud message brokers still mostly take whatever you throw in there. If you want to limit the types of messages you accept, you’ll like Google Cloud’s Pub/Sub schema support. And now, you can create revisions and accept ranges of revisions in each Topic.
##
Want to get this update sent to you every day? Subscribe to my RSS feed or subscribe via email below:
Happy Friday. Today, I read a handful of great posts. Check out some insightful stuff about microservices, serverless, lowcode, and how to get un-frustrated (is that a word?) with your team.
[blog] Why does everyone “suddenly” hate Single Page Apps? Here’s a guarantee for you. Something you’re obsessed with right now will be considered a “bad idea” in three years. It’s inevitable. As an individual, get good at learning how to learn. As a leader, build teams that are nimble and unafraid to adapt to changing circumstances.
[blog] Microservices Best Practices. Simple title to this post, but you’ll find some lengthy advice. Not every architecture should be oriented around microservices—most shouldn’t?—but this is helpful advice if you’re taking that route.
[blog] Build your first AppSheet app: how I built a food tracker. It’ll probably never be the “year of low code”, but tools like AppSheet definitely have a place at most any company. This is a excellent little walkthrough of building a simple data-driven app.
[blog] Serverless in 2023. Has “serverless” had its moment yet? I’m not sure. It’s still lurking as a powerful architecture that many don’t take advantage of.