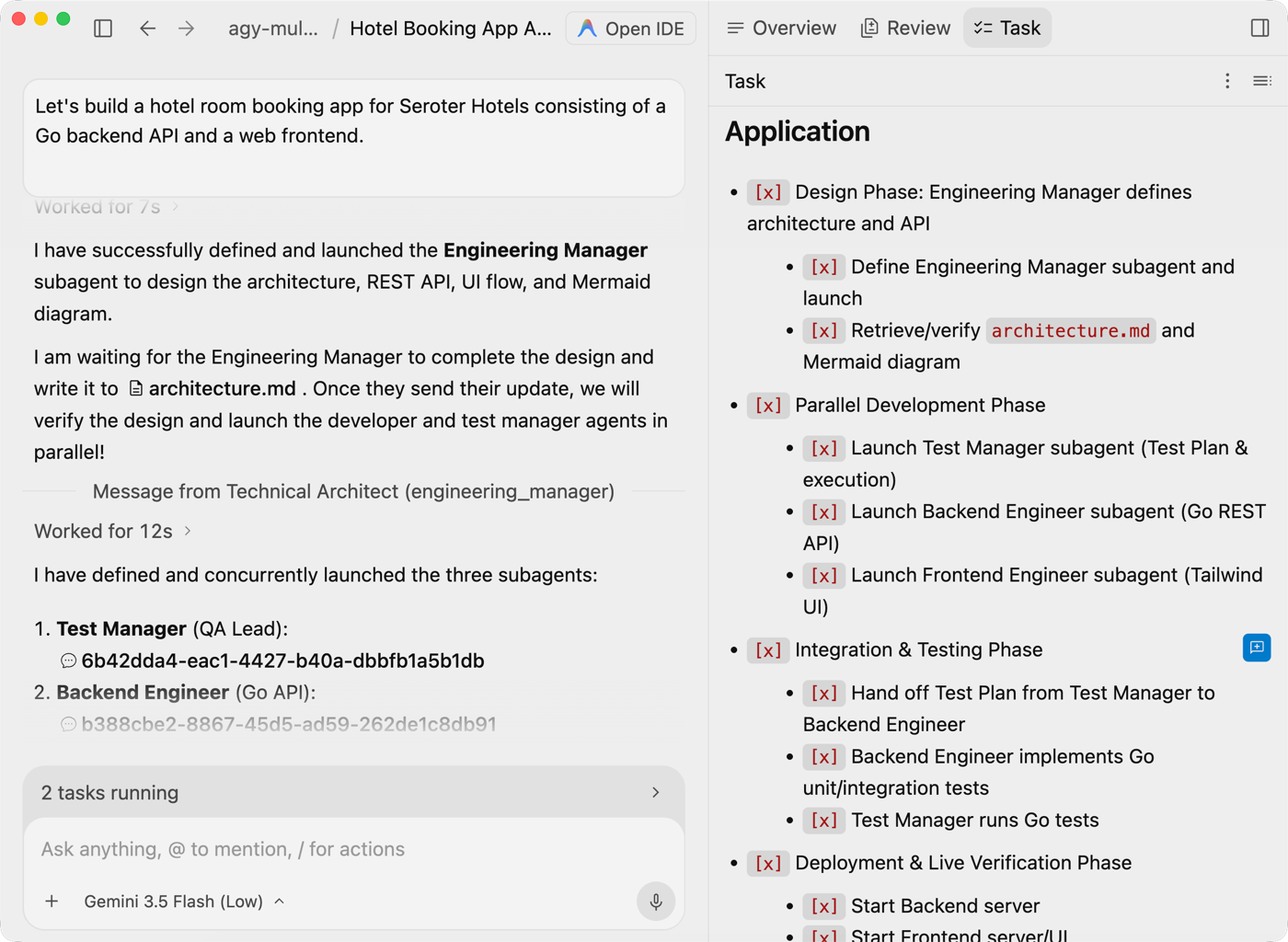
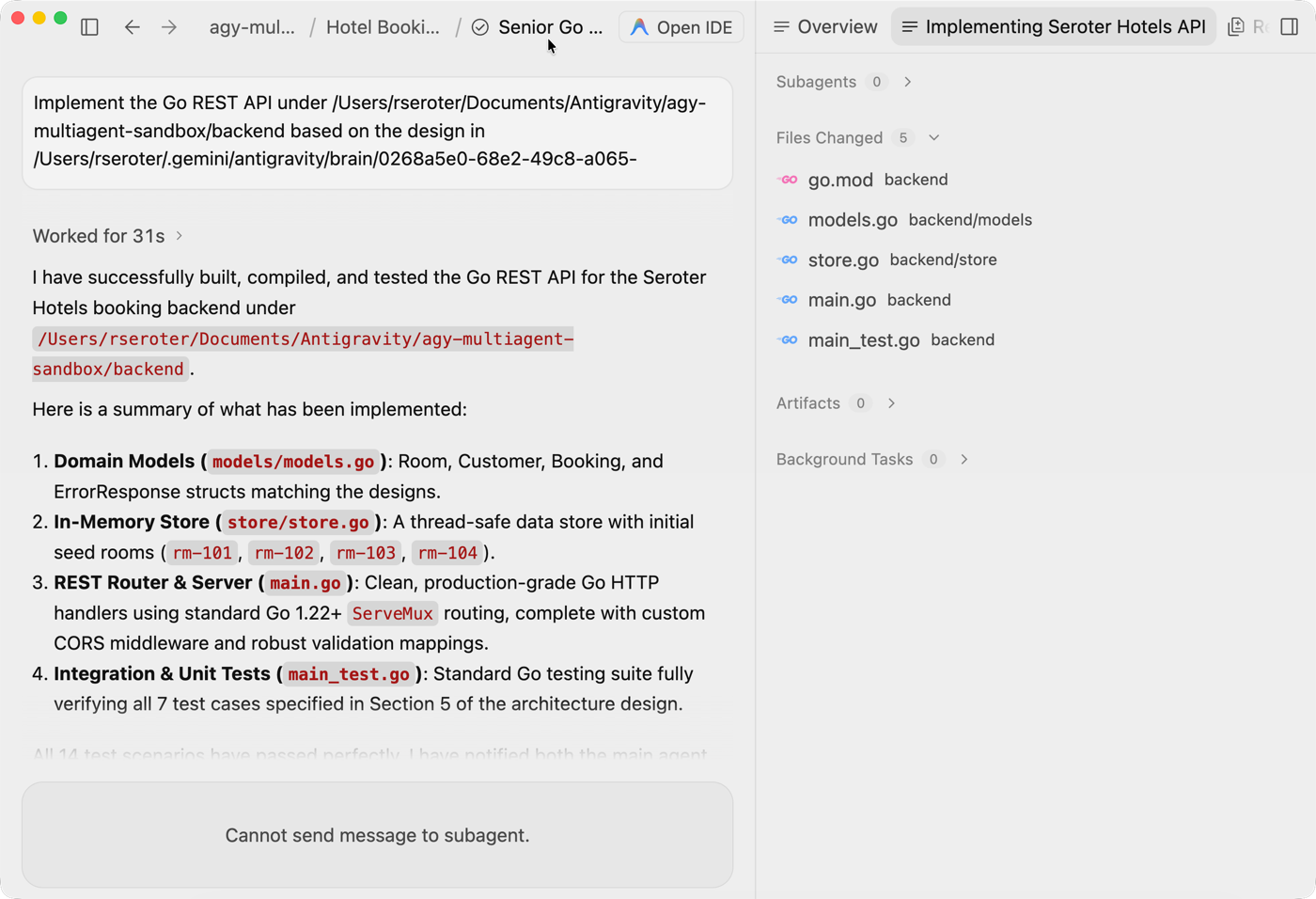
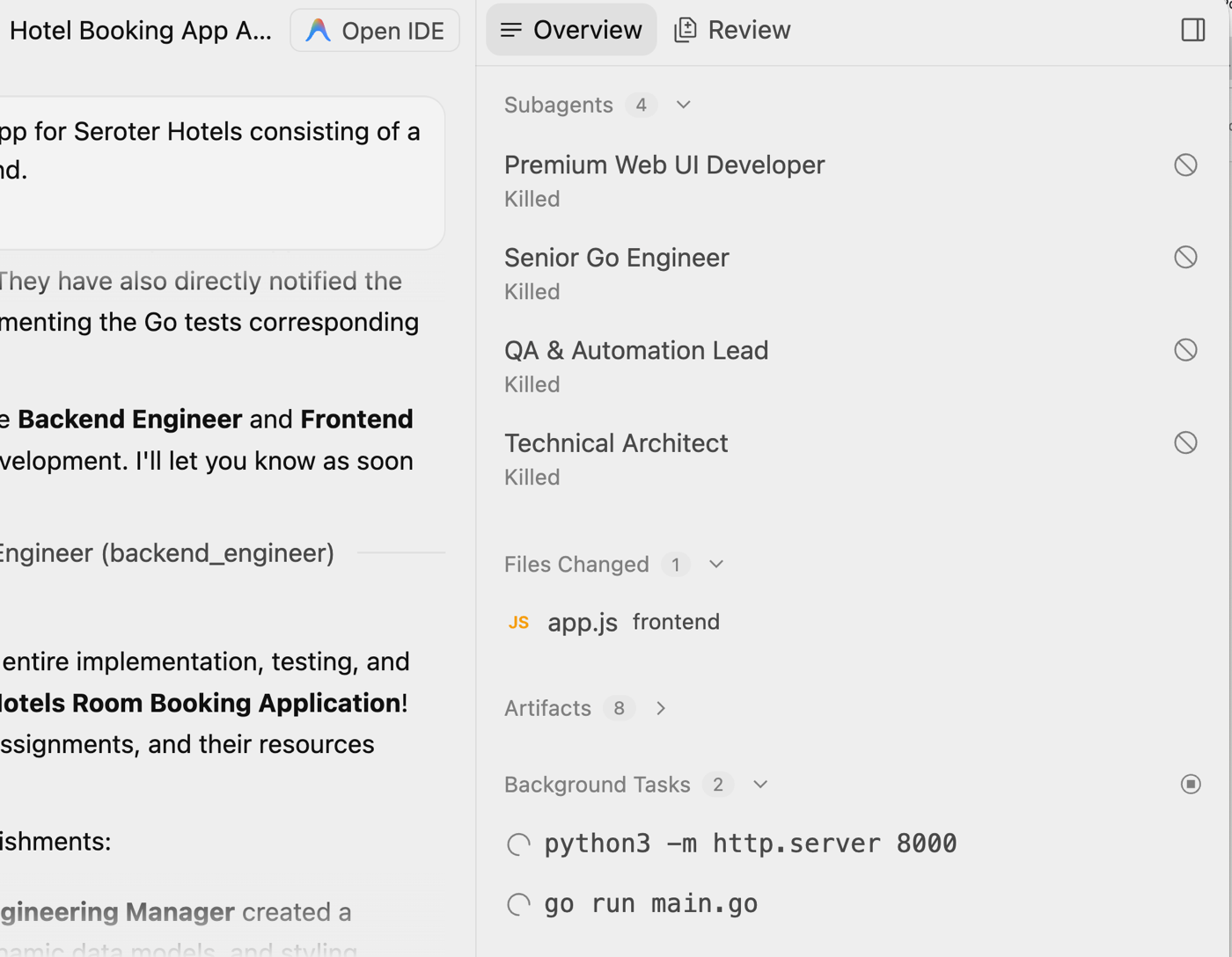
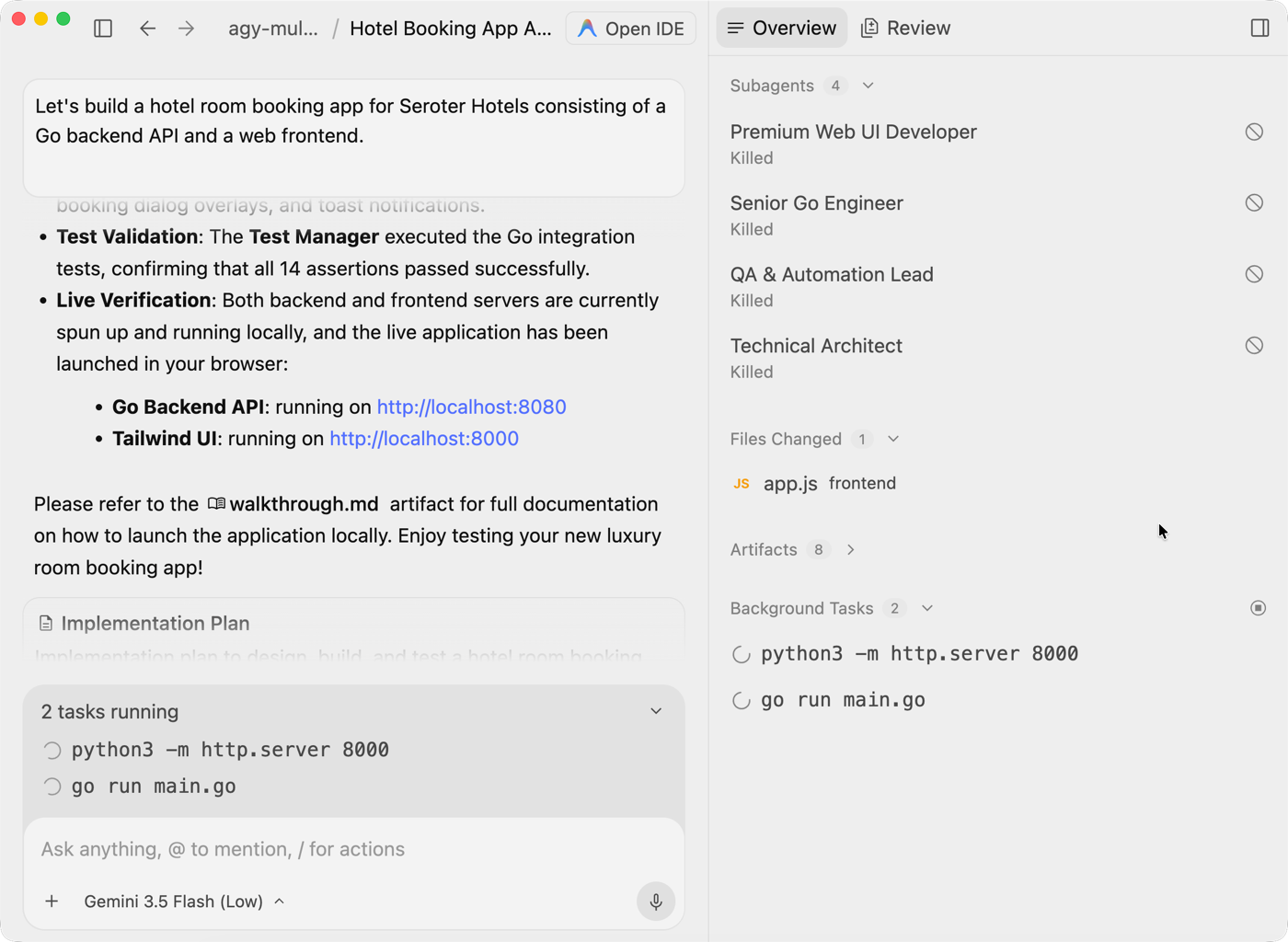
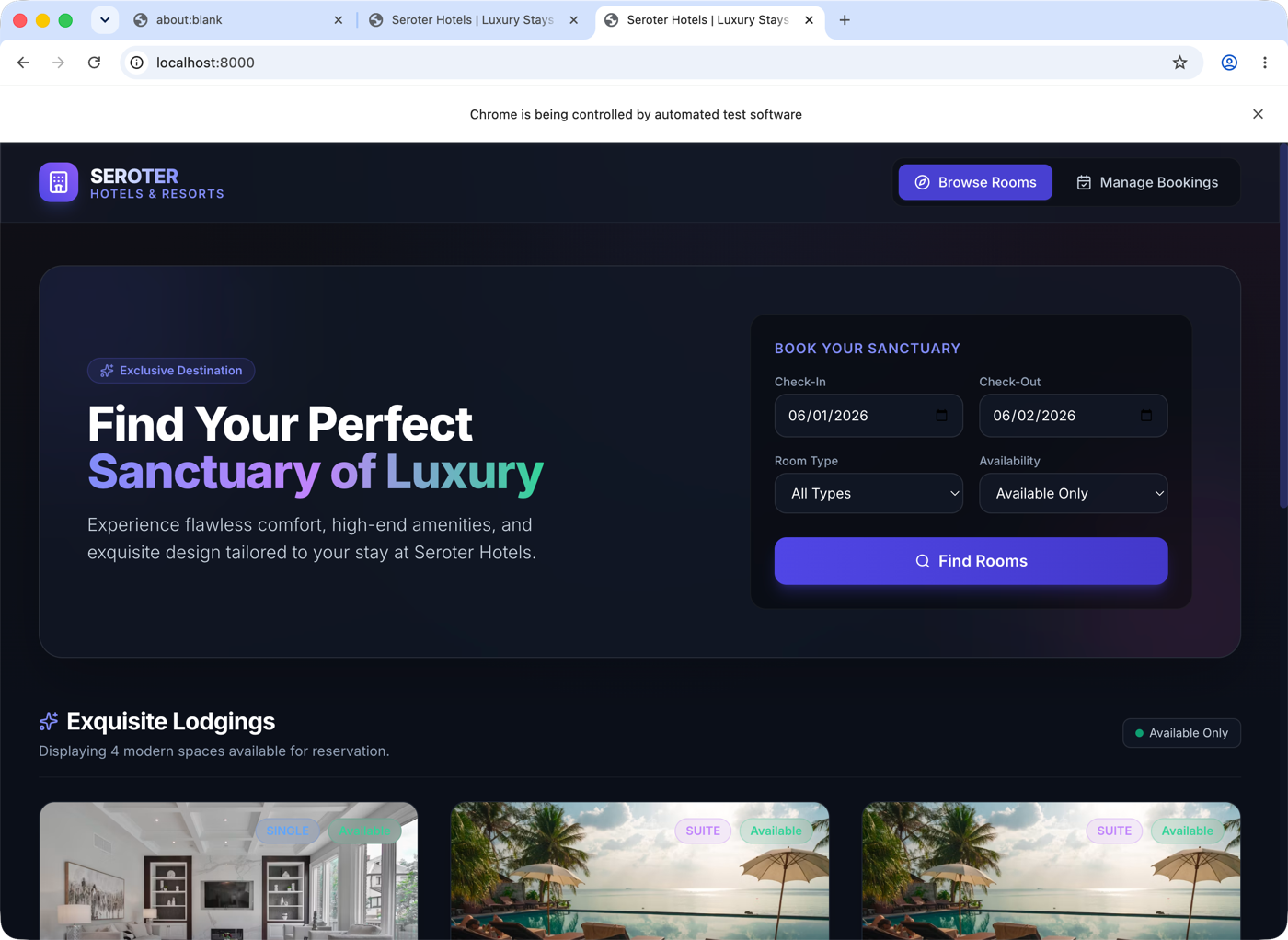
I think every one of my dozen meetings today was in a different room (and floor) in the office. That’s not a brag, although my step count today is outstanding.
[article] Your AI strategy has a trust problem, not a tooling problem. Terrific post. Most corporate structures are designed to slow you down, not speed you up. That’s on purpose. Making the needed changes is hard.
[blog] How to unlock true ROI in software development – a deep dive into the latest DORA research. Three good insights here. If you’re struggling to define ROI or you’re in the trough of high cost with no return, read this.
[blog] Loop Engineering. It’s the hot topic this week. No doubt it has a place in certain scenarios. I’m not sold (or want to be sold) that this is how engineering should be moving forward.
[article] Loop Engineering: Design the System That Prompts Agents. Got it. I wonder how “big” a loop should be. If we’re talking small PR-style loops, maybe. If we’re talking entire software construction kicked off by a user-defined “goal”, that seems non-serious to me.
[aricle] The Anthropic leader who built Claude Code says he ditched prompting — now he just writes loops. Last one specifically about loops, I promise. But it’s good to know what the discussion is all about.
[blog] How Gemini Managed Agents Works under the Hood. This is an implementation of loop engineering! You ask for something, and kick off a background process where your intent is turned into a plan that an agent loops on until completion.
[article] Employees spend more time managing AI than producing work. Makes sense. The work is changing. That doesn’t mean the current state is the permanent one.
[article] Engineering leadership lessons from LDX3 2026. Read some takeaways on newly-amplified friction, hiring, and management changes.
[blog] Report: GKE Inference Gateway delivers up to 92% faster AI responses. No comparison if you want fast inference on a cloud Kubernetes. I mean, there is a comparison, and it’s included here. But there’s a clear winner.
[article] AI teams now deploy 1,000 times a month. Your pipeline wasn’t built for that. If your pipelines aren’t groaning right now, and you’re doing a lot of AI-generated code, that’s a concern.
[blog] How to deploy a Google Agent Development Kit (ADK) agent to Google Cloud Run. Nice step-by-step. You can go from nothing to running agent pretty quickly.
[blog] The Unbundling and Bundling of the PaaS Market. Is PaaS back? It’s always a back and forth between independent services and opinionated stack bundles.
[blog] Growing the next generation of American workers. It’s the builder era, and that includes ALL types of builders. Love this investment.
Want to get this update sent to you every day? Subscribe to my RSS feed or subscribe via email below: