Q: PDC 2009 has recently finished up and we saw the formal announcements around Azure, AppFabric and the BizTalk Server roadmap. It seems we’ve been talking to death about BizTalk vs. Dublin (aka AppFabric) and such, so instead, talk to us about NEW scenarios that you see these technologies enabling for customers. What can Azure and/or AppFabric add to BizTalk Server and allow architects to solve problems easier than before?
A: First off, let me clarify that Windows Server AppFabric is not just “Dublin”-renamed, it brings together the technologies that were being developed as code-name “Dublin” and code-name “Velocity”. For the benefit of your readers that may not know much about “Velocity”, it was a distributed in-memory cache, ultra-high performance and highly-scalable. Although I have not been involved with “Velocity”, I have been quite close to “Dublin” since the beginning.
I think the immediate value people will see in Windows Server AppFabric is that now.NET developers are being provided with a host for their WF workflows. Previously developers could use SharePoint as a host, or write their own host (typically a Windows service). However, writing a host is a non-trivial task once you start to think about scale-out, failover, tracking, etc. I believe that the lack of a host was a bit of an adoption blocker for WF and we’re going to see that a lot of people that never really thought about writing workflows will start doing so. People will realize that a lot of what they write actually is a workflow, and that we’ll see migration once they see how easy it is to create a workflow and host it in AppFabric and expose it as WCF Web services. This doesn’t, of course, preclude the need for integration server (BizTalk) which as you’ve said we’ve been talked to death about, and “when to use what” is one of the most common questions I get. There is a time and place for each, they are complementary.
Your question is very astute, although Azure and AppFabric will allow us to create the same applications architected in a new way (in the cloud, or hybrid on-premise-plus-cloud), they will also allow us to create NEW types of applications that previously would not have been possible. In fact, I have already had many real-world discussions with customers around some novel application architectures.
For example, in one case, we’re working with geo-distributed (federated) ESBs, and potentially tens of thousands of data collection points scattered around the globe, each rolling up data to its “regional ESB”. Some of those connection points will be in VERY remote locations, where reliable connectivity can be a problem. It would never have been reasonable to assume that those locations would be able to establish secure connections to a data center with any kind of tolerable latency, however, the expectation is that somehow they’ll all be able to reach to cloud. As such, we can use the Windows Azure platform Service Bus as a data collection and relay mechanism.
Another cool pattern is using the Windows Azure platform Service Bus as an entry point into an on-premises ESB. In the past, if a BizTalk developer wanted to accept input from the outside typically they would expose a Web service, and reverse-proxy that to make it available, probably with a load balancer thrown in if there was any kind of sustained or spike volume. That all works, but it’s a lot of moving parts that need to be set up. A new pattern we can do now is that we can use the Windows Azure platform Service Bus as a relay: externals parties send messages to it (assuming they are authorized to do so by the Windows Azure platform Access Control service) , and a BizTalk receive location picks up from it. That receive location could even be an ESB on-ramp. I have a simple application that integrates BizTalk, ESB, BAM, SharePoint, InfoPath, SS/AS, SS/RS (and a few more things). It was trivial for me to add another receive location that picked up from the Service Bus (blog post about this coming soon, really J). Taking advantage of Azure to act as an intermediary like this is a very powerful capability, and one I think will be very widely used.
Q: You were instrumental in incubating and delivering the first release of the ESB Toolkit (then ESB Guidance) for Microsoft. I’ve spoken a bit about itineraries here, but give me your best sales pitch on why itineraries matter to Microsoft developers who may not familiar with this classic ESB pattern. When is the right time to use them, why use an itinerary instead of an orchestration, when should I NOT use them?
A: I recently had the pleasure of creating and delivering a “Building the Modern ESB” presentation with a gentleman from Sun at the SOA Symposium in Rotterdam. It was quite enlightening, to see the convergence and how similar the approaches are. In that world, an itinerary is called a “micro-flow”, and it exists for exactly the same reasons we have it in the ESB Toolkit.
Itineraries can be thought of as a light-weight service composition model. If all you’re doing is receiving a request, calling 3 services, perhaps with some transformations along the way, and then returning a response, then that would be appropriate for an itinerary. However, if you have a more complex flow, perhaps where you require sophisticated branching logic or compensation, or if it’s long running, then this is where orchestrations come into play. Orchestration provides the rich semantics and constructs you need to handle these more sophisticated workflows.
The ESB Toolkit 2.0 added the new Broker capabilities, which allow you to do conditional branching from inside an itinerary, however I generally caution against that as its one more place you could hide business logic (although there will of course be times where this is the right approach to take).
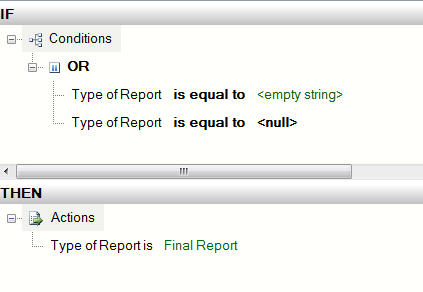
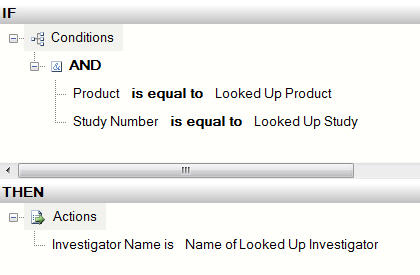
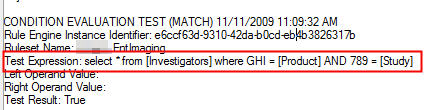
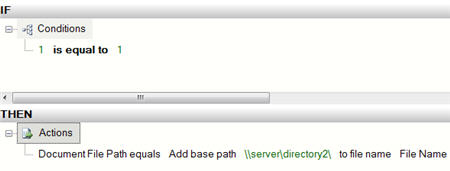
A pattern that I REALLY like is to use BizTalk’s Business Rules Engine (BRE) to dynamically select an itinerary and apply it to a message. The BRE has always been a great way to abstract business rules (which could change frequently) from the process (which doesn’t change often). By letting the BRE choose an itinerary, you have yet another way to leverage this abstraction, and yet another way you can quickly respond to changing business requirements.
Q: You’ve had an interesting IT career with a number of strategic turns along the way. We’ve seen the employment market for developers change over the past few years to the point that I’ve had colleagues say that they wouldn’t recommend that their kids go into computer science and rather focus on something else. I still think that this is a fun field with compelling opportunities, but that we all have to be more proactive about our careers and more tuned in to the skills we bring to the table. What advice would you give to those starting out their IT careers with regards to where to focus their learning and the types of roles they should be looking for?
A: It’s funny, when the Internet bubble burst, a couple of developers I knew then decided to abandon the industry and try their hands at something else: being a mortgage broker. I’m not sure where they are now, probably looking for the next bubble J
You’re right though, I’ve been fortunate in that I’ve had the opportunity to play many roles in this industry, and I have never been as excited about where we are as an industry as I am now. The maturing and broad adoption of Web service standards, the adoption of Service-Oriented Architectures and ESBs, the rapid onset of the cloud (and new types of applications cloud computing enables)… these are all major change agents that are shaking up our world. There is, and will continue to be, a strong market for developers. However, increasingly, it’s not so much what you know, but how quickly you can learn and apply something new that really matters. In order to succeed, you need to be able to learn and adapt quickly, because our industry seems to be in a constant state of increasingly rapid change. In my opinion, good developers should also aspire to “move up the stack” if you want to advance your career, either along a technical track (as an architect) or perhaps a more business-related track (strategy advisor, project management). As you can see from the recently published SOA Manifesto (http://soa-manifesto.org), providing business value and better alignment between IT and business are key values that should be on the minds of developers and architects, and SOA “done right” facilitates that alignment.
Q [stupid question]: year you finally bit the bullet and joined Microsoft. This is an act often equated with “joining the dark side.” Now that phrase isn’t only equated with doing something purely evil, but rather, giving into something that is overwhelming and seems inevitable such as joining Facebook, buying an iPhone, or killing an obnoxious neighbor and stuffing him into a recycling container. Standard stuff. Give us an example (in life or technology) of something you’ve been resisting in your life, and why you’re holding out.
A: Wow, interesting question.
I would have to say Twitter. I resisted for a long time. I mean c’mon, I was already on Facebook, Live, LinkedIn, Plaxo…. Where does it end? At some point you need to be able to live your life and do your work rather than talking about it. Plus, maybe I’m verbose, but when I have something to say it’s usually more than 140 characters, so I really didn’t see the point. However, I succumbed to the peer pressure, and now, yes, I am on Twitter.
Do you think if I say something like “you can follow me at http://twitter.com/BrianLoesgen” that maybe I’ll get the “Seroter Bump”? 🙂
Thanks Brian for some good insight into new technologies.