This has come up twice for me in the past week: once while reading the tech review comments on my own book (due out in April), and again while I was tech reviewing another BizTalk book (due out in July). That is, we presumptively say that the BizTalk “message type” always equals http://namespace#root when that’s not necessarily true. Let’s look at two cases demonstrated here.
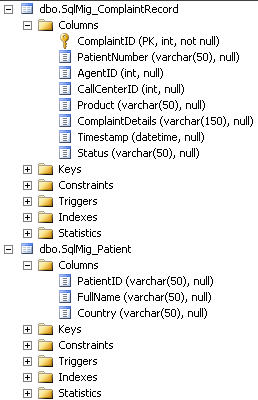
This first simple case looks at a situation where an XML schema actually has no namespace. Consider this schema:

Perfectly fine schema, no target namespace. I’ve gone ahead and created another schema (with namespace) and mapped the no-namespace schema to the namespace schema. After I deploy this solution and create the necessary ports to both pick up and drop off the message, I can stop the send port and observe the context properties of the inbound message.

Notice that my message type is set to ReturnRequest which is the name of the root node of my schema. Obviously, no namespace is required here. If I throw my map on the send port, I can also see that the source schema is successfully found and used when mapping to my destination format.
So, for case #1, you can have schemas with no namespace, and the message type for that message traveling through BizTalk is in no worse shape.
For case #2, I wanted to try creating my own message type arbitrarily and keep it as something BizTalk doesn’t generate. For instance, let’s say I receive binary files (e.g. PDFs) but want to add not only promoted fields about the PDF, but also type the message itself. The PDF file has a specific name which reflects the type of data it contains (e.g. ProductRefund_982100.pdf and ProductReturn_20032.pdf). The file location where these PDFs are dropped have names based on the country of origin, like so:

So I can set a “type” for the message based on the file name prefix, and I can set a promoted “country” value based on the location I picked it up from. After adding a new property schema to my existing BizTalk solution, I next built a custom pipeline component which could work this magic for me. The guts of the pipeline component, the Execute operation, is shown here:
public IBaseMessage Execute(
IPipelineContext pContext,
IBaseMessage pInMsg)
{
//get context pointer
IBaseMessageContext context = pInMsg.Context;
//read file name and path
string filePath = context.Read("ReceivedFileName",
"http://schemas.microsoft.com/BizTalk/2003/file-properties").ToString();
//parse file name to determine message type
string fileName = Path.GetFileNameWithoutExtension(filePath);
string[] namePieces = fileName.Split('_');
string messageType = namePieces[0];
//get last folder which indicates country this pertains to
string[] directories = filePath.Split(Path.DirectorySeparatorChar);
string country = directories[directories.Length - 2];
//set message type
pInMsg.Context.Promote("MessageType",
"http://schemas.microsoft.com/BizTalk/2003/system-properties",
messageType);
//set promoted data value
pInMsg.Context.Promote("Country",
"http://Blog.BizTalk.MessageTypeEvaluation.ProductReturn_PropSchema",
country);
return pInMsg;
}
After compiling this and adding to the “Pipeline Components” directory in the BizTalk install folder, I added a new receive pipeline to my existing BizTalk solution and added my BinaryPromoter component.

After deploying, I added a single receive port with two receive locations that each point to a different “country” pickup folder. Each receive location uses my new custom receive pipeline.

I have two send ports, each subscribing to a different “message type” value. My second send port, shown here, also subscribes on my custom “country” promoted value.

When I drop a PDF “product refund” file into the “USA” folder, I can observe that my message (of PDF type) has a message type and promoted data value.
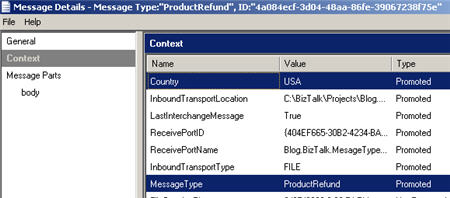
Neat. So while it’s important to have BizTalk-defined message types when doing many operations, be aware that you can (a) still have message types without namespaces, and (b) define completely custom message types for use in message routing.
Technorati Tags: BizTalk Server