I was asked a couple days ago whether it was possible to receive a related but disjointed set of files into BizTalk Server and both aggregate and reorder them prior to passing the result to a web service. Below is small sample I put together to demonstrate that it was indeed possible.
You can find some other resequencer patterns (most notably, in the Pro BizTalk Server 2006 book), but I was looking for something fairly simple and straightforward. My related messages all come into BizTalk at roughly the same time, and, there are no more than 20 in a related batch.
Let’s first take a look at a simplified version of the schema I’m working with.
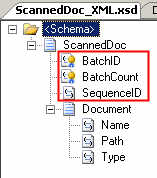
I’ve highlighted a few header values. I know the unique ID of the batch of related records (which is a promoted value), how many items are in the batch, and the position of this individual message in the batch sequence. These are crucial for creating the singleton, and being able to reorder the messages later on. The message payload is a description of a document. This same schema is used for the “aggregate” message because the “Document” node has an unbounded occurrence limit.
I need a helper component which stores, sorts and combines my batch messages. My class starts out like this:

Notice that I’m using a SortedDictionary class which is going to take the integer-based sequence number as the “key” and an XML document as the “value.” The SortedDictionary is pretty cool in that it will automatically sort my list based on the key. No extra work needed on my part. I’ve also got a couple member variables that hold values universal to the entire batch of records. I accept those values in the constructor.
Next, I have an operation to take an inbound XML document and add it to the list.

You can see that I yank out the document-specific “SequenceID” and use that value as the “key” in the SortedDictionary.
Next I created an “aggregation” function which drains the SortedDictionary and creates a single XML message that jams all the “Document” nodes into a repeating collection.

As you can see, I extract values from the dictionary using a “for-each” loop and a KeyValuePair object. I then create a new “Document” node, and suck out the guts of the dictionary value and slap it in there.
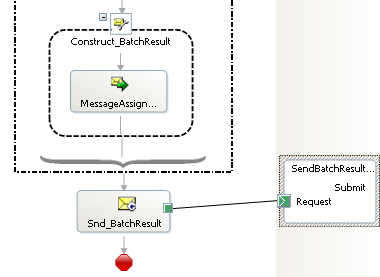
Now I can build my BizTalk singleton. Because we promoted the “BatchID” value, I can create a correlation set based on it. My initial receive shape takes in a “BatchRecord” message and initializes the correlation set. In the “Set Variables” Expression Shape, I instantiate my loop counters (index at 1 and maximum based on the “BatchCount” distinguished field), and the helper class by passing in the “BatchID” and “BatchCount” to the constructor. In the “AddDocToBatch” Expression Shape, I set my message equal to a variable of type “XmlDocument”, and pass that variable to the “AddDocumentToDictionary” method of my helper class.
Next, I have a loop where I receive the (following correlation) “BatchRecord” message, once again call “AddDocumentToDictionary”, and finally increment my loop counter.

Finally, I create the “BatchResult” message (same message type as the “BatchRecord”) by setting it equal to the result of the “GetAggregateDocument” method of the helper class. Then, I send the message out of the orchestration.
So, if I drop in 5 messages at different times and completely out of order (e.g. sequence 3, 5, 4, 2, 1), I get the following XML output from the BizTalk process:

As you can see, all the documents show up in the correct order.
Some parting thoughts: this pattern clearly doesn’t scale as the number of items in a batch increases. Because the batch aggregate is kept in memory, you will run into issues if either (a) the batch messages come in over a long period of time or (b) there are lots of messages in a batch. If either case is true, you would want to consider stashing the batch records in an external storage (e.g. database) and doing the sorting and mashing at that layer.
Any other thoughts you wish to share?
Technorati Tags: BizTalk

Leave a reply to Richard Seroter Cancel reply