I’m currently architecting a project where one of the requirements is to limit the number of concurrent calls to a web service. I’d covered a similar topic in a previous post, and outlined two ways one could try and configure this behavior.
First, you could limit the number of simultaneous connections for the SOAP adapter by setting the “maxconnections” setting in the btsntsvc.exe.config file. The downside to this mechanism is that if you have many messages, and the service takes a while to process, you could timeouts.
The second choice is to turn on ordered delivery at the send port. This eliminates the timeout issue, but, really slows processing. In our case, the downstream web service (a FirstDoc web service that uploads documents to Documentum) is fairly CPU intensive, and may take upwards of 200 seconds to run (which is why I also asked the developer to consider an asynchronous callback pattern), so we need a few calls happening at once, but not so many that the box collapses.
So, Scott Colestock recommended I take a look at the last issue of the BizTalk HotRod magazine and review the orchestration throttling pattern that he had expalined there. Unlike the two options mentioned above, this DOES requirement development, but, it also provides fairly tight control over the number of concurrent orchestrations. Since Scott’s article didn’t have code attached, I figured I’d rebuild the project to help our developer out, and, learn something myself.
The first step was to define my two BizTalk message schemas. My first is the schema that holds the data used by the FirstDoc web service. It contains a file path which the web service uses to stream the document from disk into Documentum. I didn’t want BizTalk to actually be routing 50MB documents, just the metadata. The second schema is a simple acknowledgement schema that will be used to complete an individual processing instance. Also, I need a property schema that holds a unique correlation ID, and the instance ID of the target convoy. Both properties are set to MessageContextPropertyBase since the values themselves don’t come from the message payload but rather, the context.

The second step was to build a helper component which will dictate which throttled instance will be called. Basically, this pattern uses convoy orchestrations. The key is though, that you have multiple convoys running, vs. a true singleton that processes ALL messages. The “correlation” used for each convoy is an instance ID that corresponds to a number in the numerical range of running orchestrations allowed. For instance, if I allowed 10 orchestrations to run at once, I’d have 10 convoy orchestrations, each one initializing (and following) an “InstanceID” between 1-10. Each of my calling orchestrations acquire a number between 1-10, and then target that particular correlation. Make sense? So I may have 500 messages come in at once, and 500 base orchestrations spin up, but each one of those target a specific throttled (convoy) orchestration.
So my helper component is responsible for doling out an instance ID to the caller. The code looks like this:
Notice that because it’s a static class, and it has a member variable, we have to be very careful to build this in a thread safe manner. This will be called by many orchestrations running on many threads.
Once this component was built and GAC-ed, I could build my orchestration. The first orchestration is the convoy. The first receive shape (which is direct bound to the MessageBox) initializes the “instance ID” correlation set. Then I have a loop which will run continuously. Inside that loop, I have a placeholder for the logic that actually calls Documentum, and waits for the response. Next I build the “acknowledgement message”, making sure to set the “Correlation ID” context property so that this acknowledgement reaches the orchestration that called it. I then send that message back out through a direct bound send port. Finally, I have a receive shape which follows the “Instance ID” correlation set (thus defining this orchestration as a convoy).
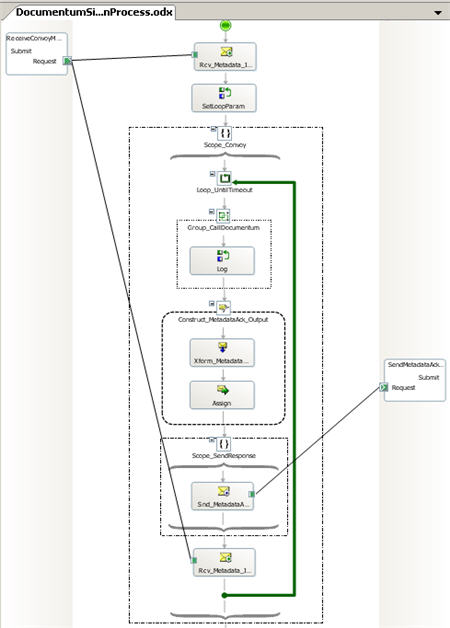
Next, we have the orchestration that spins up for EVERY inbound message. First, it receives a message from a port bound to a file receive location. Next, within an Expression shape, I call out to my “round robin” helper component which gives me the next instance ID in the sequence.
I then make sure to create a new message with both the “Correlation ID” and “Instance ID” context properties set.
Finally, I send this message out (via direct bound send port) and wait for the acknowledgement back.

So what I have now is a very (basic) load balancing solution where many inbound messages flow through a narrowed pipe to the destination. The round robin helper component keeps things relatively evenly split between the convoy orchestrations, and I’m not stuck using a singleton that grinds all parallel processing to a halt. Running a few messages through this solution yields the following trace …

If I look in the BizTalk Administration Console, I now have three orchestrations running at all times, since I set up a maximum of three convoys. Neat. Thanks to Scott for identifying this pattern.
Any other patterns for this sort of thing that people like?
Technorati Tags: BizTalk

Leave a comment