On of the many actions items I took away from last week’s TechEd was to spend some time with the latest release of the .NET Services portion of the Azure platform from Microsoft. I saw Aaron Skonnard demonstrate an example of a RESTful, anonymous cloud service, and I thought that I should try and build the same thing myself. As an aside, if you’re looking for a nice recap of the “connected system” sessions at TechEd, check out Kent Weare’s great series (Day1, Day2, Day3, Day4, Day5).
So what I want is a service, hosted on my desktop machine, to be publicly available on the internet via .NET Services. I’ve taken the SOAP-based “Echo” example from the .NET Services SDK and tried to build something just like that in a RESTful fashion.
First, I needed to define a standard WCF contract that has the attributes needed for a RESTful service.
using System.ServiceModel;
using System.ServiceModel.Web;
namespace RESTfulEcho
{
[ServiceContract(
Name = "IRESTfulEchoContract",
Namespace = "http://www.seroter.com/samples")]
public interface IRESTfulEchoContract
{
[OperationContract()]
[WebGet(UriTemplate = "/Name/{input}")]
string Echo(string input);
}
}
In this case, my UriTemplate attribute means that something like http://<service path>/Name/Richard should result in the value of “Richard” being passed into the service operation.
Next, I built an implementation of the above service contract where I simply echo back the name passed in via the URI.
using System.ServiceModel;
namespace RESTfulEcho
{
[ServiceBehavior(
Name = "RESTfulEchoService",
Namespace = "http://www.seroter.com/samples")]
class RESTfulEchoService : IRESTfulEchoContract
{
public string Echo(string input)
{
//write to service console
Console.WriteLine("Input name is " + input);
//send back to caller
return string.Format(
"Thanks for calling Richard's computer, {0}",
input);
}
}
}
Now I need a console application to act as my “on premises” service host. The .NET Services Relay in the cloud will accept the inbound requests, and securely forward them to my machine which is nestled deep within a corporate firewall. On this first pass, I will use a minimum amount of service code which doesn’t even explicitly include service host credential logic.
using System.ServiceModel;
using System.ServiceModel.Web;
using System.ServiceModel.Description;
using Microsoft.ServiceBus;
namespace RESTfulEcho
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("Host starting ...");
Console.Write("Your Solution Name: ");
string solutionName = Console.ReadLine();
// create the endpoint address in the solution's namespace
Uri address = ServiceBusEnvironment.CreateServiceUri(
"http",
solutionName,
"RESTfulEchoService");
//make sure to use WEBservicehost
WebServiceHost host = new WebServiceHost(
typeof(RESTfulEchoService),
address);
host.Open();
Console.WriteLine("Service address: " + address);
Console.WriteLine("Press [Enter] to close ...");
Console.ReadLine();
host.Close();
}
}
}
So what did I do there? First, I asked the user for the solution name. This is the name of the solution set up when you register for your .NET Services account.

Once I have that solution name, I use the Service Bus API to create the URI of the cloud service. Based on the name of my solution and service, the URI should be:
http://richardseroter.servicebus.windows.net/RESTfulEchoService.
Note that the URI template I set up in the initial contract means that a fully exercised URI would look like:
http://richardseroter.servicebus.windows.net/RESTfulEchoService/Name/Richard
Next, I created an instance of the WebServiceHost. Do not use the standard “ServiceHost” object for a RESTful service. Otherwise you’ll be like me and waste way too much time trying to figure out why things didn’t work. Finally, I open the host and print out the service address to the caller.
Now, nowhere in there are my .NET Services credentials applied. Does this mean that I’ve just allowed ANYONE to host a service on my solution? Nope. The Service Bus Relay service requires authentication/authorization and if none is provided here, then a Windows CardSpace card is demanded when the host is started up. In my Access Control Service settings, you can see that I have a Windows CardSpace card associated with my .NET Services account.

Finally, I need to set up my service configuration file to use the new .NET Services WCF bindings that know how to securely communicate with the cloud (and hide all the messy details from me). My straightforward configuration file looks like this:
<configuration>
<system.servicemodel>
<bindings>
<webhttprelaybinding>
<binding opentimeout="00:02:00" name="default">
<security relayclientauthenticationtype="None" />
</binding>
</webhttprelaybinding>
</bindings>
<services>
<service name="RESTfulEcho.RESTfulEchoService">
<endpoint name="RelayEndpoint"
address="" contract="RESTfulEcho.IRESTfulEchoContract"
bindingconfiguration="default"
binding="webHttpRelayBinding" />
</service>
</services>
</system.servicemodel>
</configuration>
Few things to point out here. First, notice that I use the webHttpRelayBinding for the service. Besides my on-premises host, this is the first mention of anything cloud-related. Also see that I explicitly created a binding configuration for this service and modified the timeout value from the default of 1 minute up to 2 minutes. If I didn’t do this, I occasionally got an “Unable to establish Web Stream” error. Finally, and most importantly to this scenario, see the RelayClientAuthenticationType is set to None which means that this service can be invoked anonymously.
So what happens when I press “F5” in Visual Studio? After first typing in my solution name, I am asked to chose a Windows Card that is valid for this .NET Services account. Once selected, those credentials are sent to the cloud and the private connection between the Relay and my local application is established.

I can now open a browser and ping this public internet-addressable space and see a value (my dog’s name) returned to the caller, and, the value printed in my local console application.
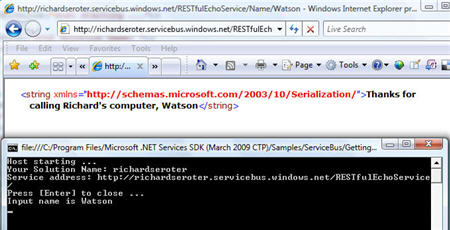
Neato. That really is something pretty amazing when you think about it. I can securely unlock resources that cannot (or should not) be put into my organization’s DMZ, but are still valuable to parties outside our local network.
Now, what happens if I don’t want to use Windows CardSpace for authentication? No problem. For now (until .NET Services is actually released and full ADFS federation is possible with Geneva), the next easiest thing to do is apply username/password authorization. I updated my host application so that I explicitly set the transport credentials:
static void Main(string[] args)
{
Console.WriteLine("Host starting ...");
Console.Write("Your Solution Name: ");
string solutionName = Console.ReadLine();
Console.Write("Your Solution Password: ");
string solutionPassword = ReadPassword();
// create the endpoint address in the solution's namespace
Uri address = ServiceBusEnvironment.CreateServiceUri(
"http",
solutionName,
"RESTfulEchoService");
// create the credentials object for the endpoint
TransportClientEndpointBehavior userNamePasswordServiceBusCredential=
new TransportClientEndpointBehavior();
userNamePasswordServiceBusCredential.CredentialType =
TransportClientCredentialType.UserNamePassword;
userNamePasswordServiceBusCredential.Credentials.UserName.UserName=
solutionName;
userNamePasswordServiceBusCredential.Credentials.UserName.Password=
solutionPassword;
//make sure to use WEBservicehost
WebServiceHost host = new WebServiceHost(
typeof(RESTfulEchoService),
address);
host.Description.Endpoints[0].Behaviors.Add(
userNamePasswordServiceBusCredential);
host.Open();
Console.WriteLine("Service address: " + address);
Console.WriteLine("Press [Enter] to close ...");
Console.ReadLine();
host.Close();
}
Now, I have a behavior explicitly added to the service which contains the credentials needed to successfully bind my local service host to the cloud provider. When I start the local host again, I am prompted to enter credentials into the console. Nice.
One last note. It’s probably stupidity or ignorance on my part, but I was hoping that, like the other .NET Services binding types, that I could attach a ServiceRegistrySettings behavior to my host application. This is what allows me to add my service to the ATOM feed of available services that .NET Services exposes to the world. However, every time that I add this behavior to my service endpoint above, my service starts up but fails whenever I call it. I don’t have the motivation to currently solve that one, but if there are restrictions on which bindings can be added to the ATOM feed, that’d be nice to know.
So, there we have it. I have a application sitting on my desktop and if it’s running, anyone in the world could call it. While that would make our information security team pass out, they should be aware that this is a very secure way to expose this service since the cloud-based relay has hidden all the details of my on-premises application. All the public consumer knows is a URI in the cloud that the .NET Services Relay then bounces to my local app.
As I get the chance to play with the latest bits in this release of .NET Services, I’ll make sure to post my findings.
Technorati Tags: .NET Services, Cloud Computing, SOA