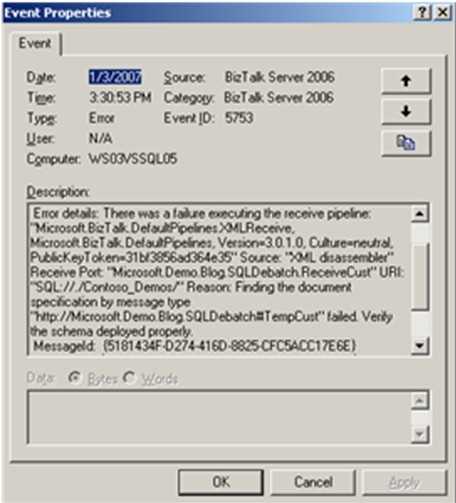
I spent a bit of time digging into how BizTalk handles various orchestration exceptions and what to expect when resuming suspended orchestrations. Here are a few results.
First off, I created a simple orchestration that calls out to an external .NET component. I inserted a few Expression Shapes which write trace statements out. We’ll view those statements using the Debug Viewer.
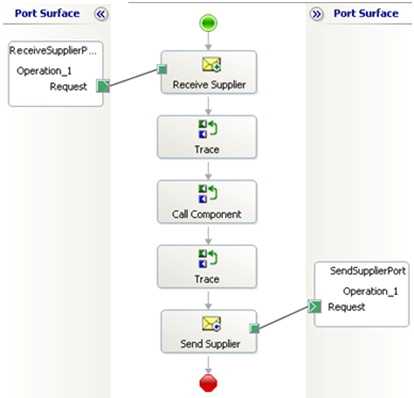
When I run this orchestration in a valid scenario, I get the following trace statements …
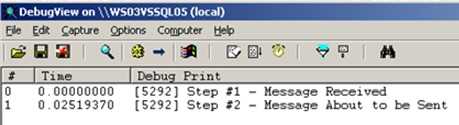
Now what happens if I submit a message that causes the .NET component to divide by 0? I naturally get an exception …
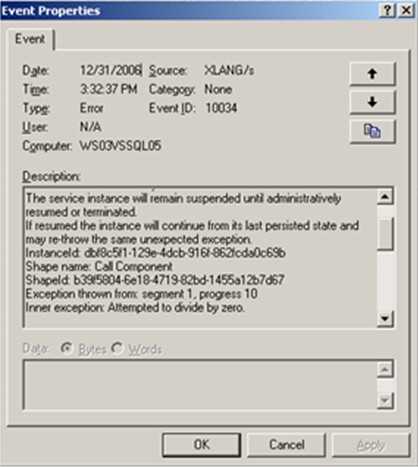
Notice that the exception tells me that the workflow will continue from the “last persisted state.” If I fix the component (to avoid “divide by 0” exceptions), re-GAC the component and bounce the BizTalk host, I can resume the orchestration instance. That results in this …
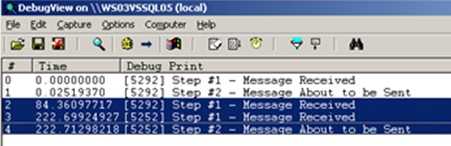
Notice on the highlighted lines that “Step #1” fired again after resuming the process. That’s because the last available persistence point was the initial Receive Shape so, the orchestration picked up from there, thus running the first trace statement again.
Now what if I purposely suspend a message using the Suspend Shape? That workflow looks like this …
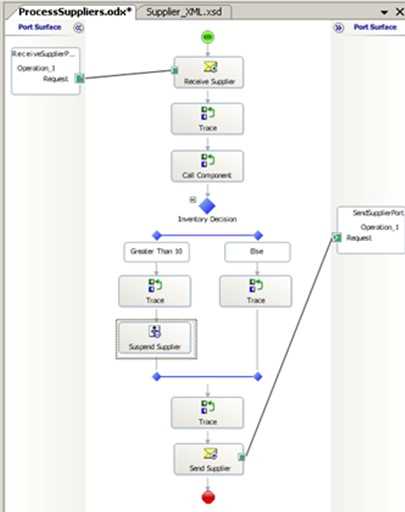
If I pass in a message that goes down the left decision path, the orchestration gets suspended. If I resume that workflow, then the orchestration will pick up WHERE IT LEFT OFF. It won’t jump back to an earlier point since a Suspend Shape is a persistence point. So, running this, suspending it, and resuming it yields the following log …
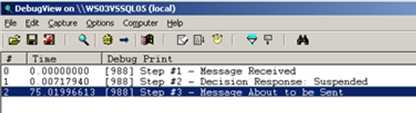
You’ll see that all the steps get fired, and none of them fire twice upon the orchestration resuming. If you feel like throwing a process into a Long Running Scope and raising an exception, like this …
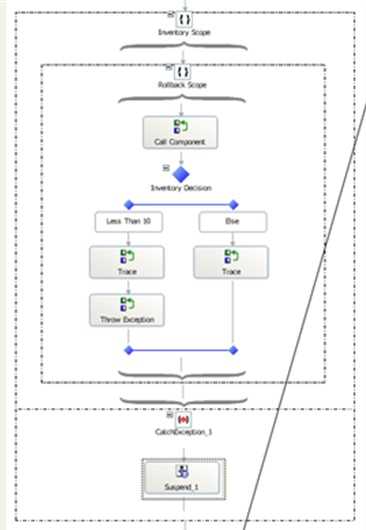
That works, but, the result is the same as above. When the orchestration gets resumed, it’ll pick up right after the Scope Shape. If we WANT the rollback to a previous step to occur, we can remove the Exception Block from the Scope Shape.
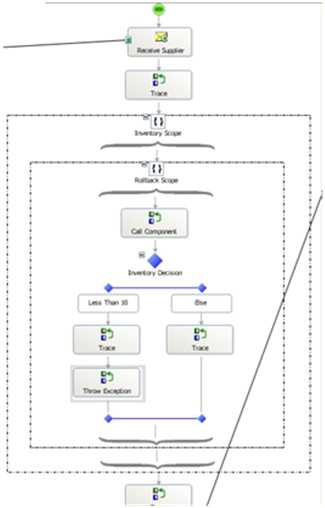
Now if an exception occurs, the orchestration will resume at the last known persistence point, which is the initial Receive Shape. If I start the orchestration, throw an error, suspend the message, fix the component and resume the orchestration, I get these results …
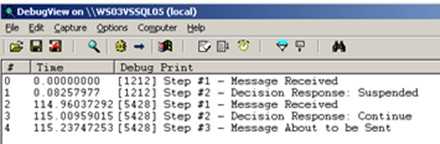
You can see here that the orchestration jumps back to Step #1 after I resume the workflow. Now the Atomic Scope above may be unnecessary given that no other persistence points exist within it, so if an error occurred, it would always jump back to the Receive Shape. But, what if I added a Construct Shape and move the Send Shape to a spot earlier in the process. Now, I have ANOTHER persistence point at the top of my workflow. If I cause an error, the workflow now jumps back to the Send Shape, not all the way back to the beginning.
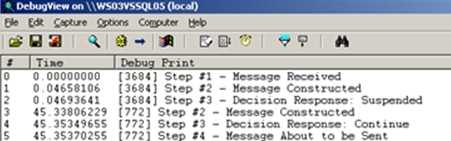
You can see here that after Step #3 (which is where the suspension occurred), that upon resuming, we only go back to the Step #2 trace point. That’s because there’s a persistence point between Step #1 and Step #2. If you want more control over where you get resumed at, use the Atomic Scopes strategically.
For instance, you could write my latest orchestration like this …
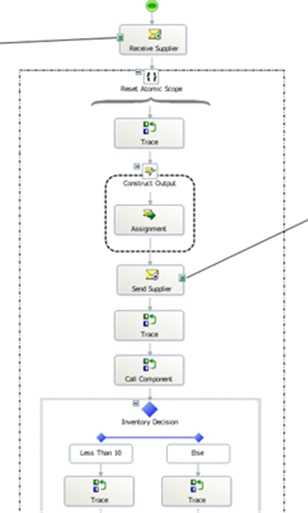
Now, the Construct and Send are both within a Scope Shape, where NO persistence points are recorded. If I raise an error, fix the offending component, and resume my workflow, the output now looks like this …
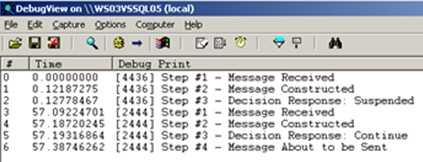
Nice! You can see that after Step #3 (where the error occurred), I resume, and jump all the way back to Step #1 where I wanted.
So, think about how you want your orchestrations to resume, WHERE you want them to resume, and test accordingly. You don’t want any surprises!
Technorati Tags: BizTalk