We were recently architecting a solution that involved BizTalk calling a synchronous web service from an orchestration in a high volume scenario. What happens if the web service takes a long time to complete? Do you run the risk of timeouts in orchestrations that hadn’t even had a chance to call the service yet?
Let’s say you have an orchestration that calls a synchronous web service, like so …
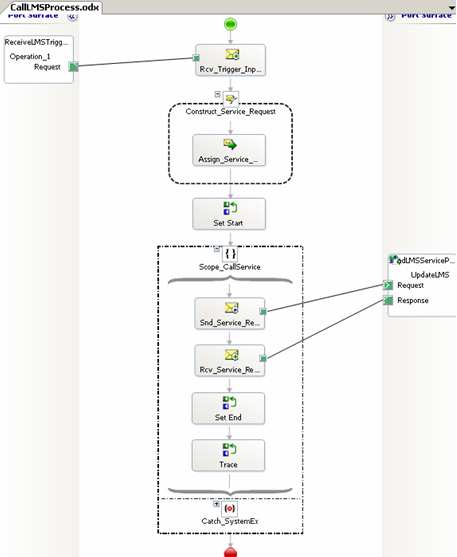
Assume that the downstream system (reached through the web service interface) cannot handle more than a few simultaneous connections. So, you can add the <add address = “*” maxconnection = “2” /> directive to your btsntsvc.exe.config file (actually, you should filter by IP address as to not affect the entire server).
What happens if I have 20 simultaneous orchestrations? I’ve reduced the outbound SOAP threadpool to “2”, so do the orchestrations wait patiently, or fail if they don’t call the service in the allotted time? I started up 3 orchestrations, and called my service (which purposely “sleeps” for 60 seconds to simulate a LONG-running service). As you can see below, I have 3 running instances, but my destination server’s event log only shows the first 2 connections.

The first two calls take 60 seconds, meaning the third message doesn’t call the service until 60 seconds have passed. You can see from my event log below that while the first 2 returned successfully, the third message/orchestration timed out. So, the “timeout” counter starts as soon as the send port is triggered, even if no threads are available.
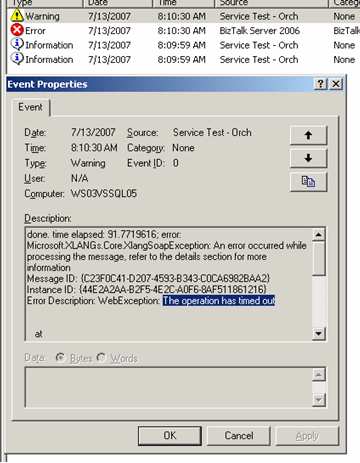
Now, what I found unexpected was the state of affairs after the timeouts. My next scenario involved dropping a larger batch size (13 messages) and predictably, I had 2 successes and 11 failures on the BizTalk server.

HOWEVER, on my web server, the service actually got called 13 times! That is, the 11 messages that timed out (as far as BizTalk knows), actually went across the wire to the service. I added a unique key to each message just to be sure. It was interesting that after the BizTalk side timed out, all the queued up requests came over at once. So, if you have significant business logic in such a service, you’d want to make sure your orchestration had a compensating step. If you catch a timeout in the orchestration, there should be a compensating step to roll back any action that the service may have committed.
So, how do you avoid this scenario? I tried a few things. First, I wondered if it was the orchestration itself starting the clock on the timeout when it detected a web port, so I removed the web port from the orchestration and used a “regular” port instead. No difference. It became crystal clear that the send port itself is starting the timeout clock, and even if no thread is available, the seconds are clicking by. I also considered using a singleton pattern to throttle the outbound calls, but didn’t love that idea.
Finally, I came upon a solution that worked. If you turn on ordered delivery for the send port, then the send port isn’t called for a message until the previous one succeeds.

This is one way to force throttling of the send port itself. To test this, I dropped 13 messages, and sure enough, the messages queued up in the send port, and no timeouts occurred.
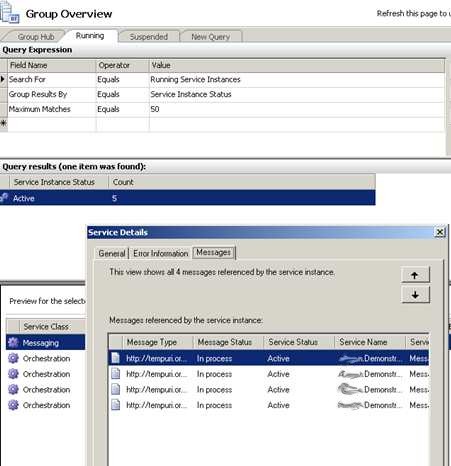
Even though the final orchestration didn’t get its service response back for nearly 13 minutes, it didn’t timeout.
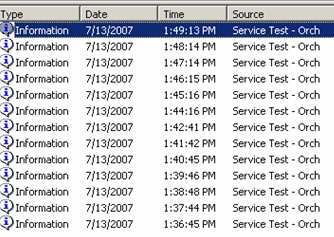
So, while not a fabulous solution, it IS a relatively clean way to make sure that timeouts don’t occur in high volume orchestration-to-service scenarios.
Technorati Tags: BizTalk, web services