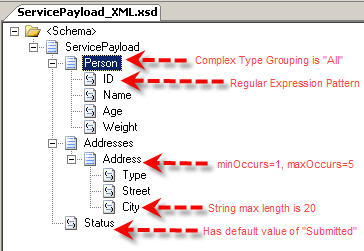
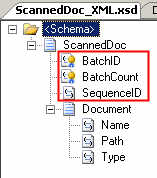
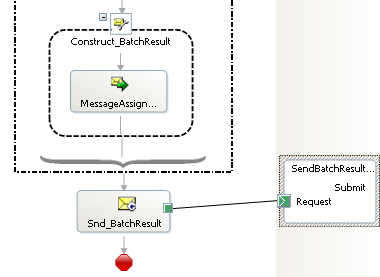
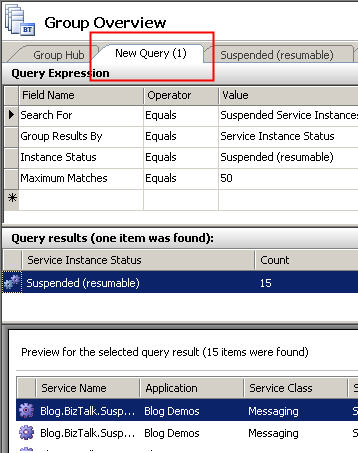
We conclude this series of blog posts by demonstrating how to take a set of feeds, and mash them up into a single RSS feed using RSSBus.
If you’ve been following this blog series, you’ll know that I was asked by my leadership to prove that RSSBus could generate a 360° view of a “contact” by (a) producing RSS feeds from disparate data sources such as databases, web services and Excel workbooks and (b) combining multiple feeds to produce a unified view of a data entity. Our target architecture looks a bit like this:

In this post, I’ll show you how to mash up all those individual feeds, and also how to put a friendly HTML front end on the resulting RSS data.
Building the Aggregate Feed
First off, my new aggregate feed asks for two required parameters: first name and last name of the desired contact.

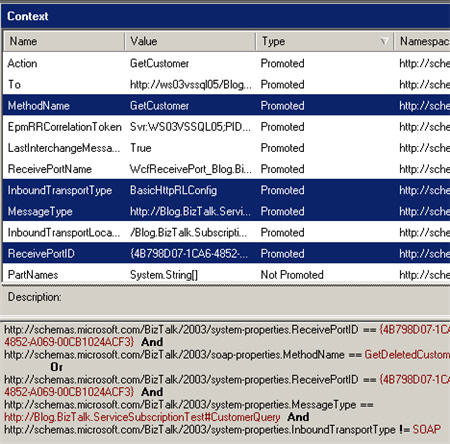
Next, I’m ready to call my first sub-feed. Here, I set the input parameter required by the feed (“in.lastname”), and make a call to the existing feed. Recall that this feed calls my “object registry service” which tells me every system that knows about this contact. I’ve taken the values I get back, and put them into a “person” namespace. The “call” block executes for each response value (e.g. if the user is in 5 systems, this block will execute 5 times), so I have a conditional statement (see red box) that looks to see which system is being returned, and setting a specific feed value based on that.
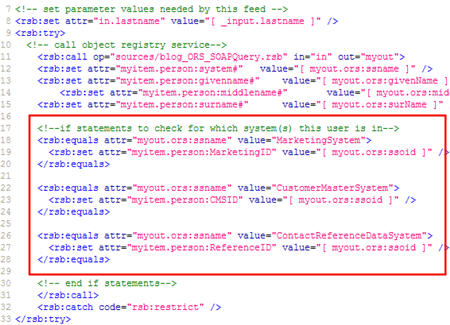
I set unique feed items for each system (e.g. “person:MarketingID”) so that I can later do a check to see if a particular item exists prior to calling the feed for that system. See here that I do a “check” to see if “MarketingID” exists, and if so, I set the input parameter for that feed, and call that feed.

You may notice that I have “try … catch” blocks in the script. Here I’m specifically catching “access denied” blocks and writing a note to the feed instead of just blowing up with a permission error.
Next, I called the other data feeds in the same manner as this one above. That is, I checked to see if the system-specific attribute existed, and if so, called the feed corresponding to that system. My “reference data” feed which serves up Microsoft Excel data returns a data node that holds the blog feed for the contact. I took that value (if it exists) and then called the built-in RSSBus Feed Connector’s feedGet operation and passed in the URL of my contact’s blog feed. This returns me whatever is served up by my contact’s external blog.

Neat. So, now I have a single RSS feed that combines data from web services, Google web queries, Excel workbooks, SQL Server databases, and external blog feeds. If I view this new, monster feed, I get a very denormalized, flat data set.

You can see (in red) that when data repeating occurred (for example, multiple contact “interactions”), the related values, such as which date goes with which location, isn’t immediately obvious. Nonetheless, I have a feed that can be consumed in SharePoint, Microsoft Outlook 2007, Newsgator, or any of your favorite RSS readers.
Building a RSSBus HTML Template
How about presenting this data entity in a business-friendly HTML template instead of a scary XML file? No problem. RSSBus offers the concept of “templates” where you can design an HTML front end for the feed.
Much like an ASP.NET page, you can mix script and server side code in the HTML form. Here, I call the mashup feed in my template, and begin processing the result set (from the “object registry service”). Notice that I can use an enumeration to loop through, and print out, each of the systems that my contact resides in. This enumeration (and being able to pull out the “_value” index) is a critical way to associate data elements that are part of a repeating result set.

To further drive that point home, consider the repeating set of “interactions” I have for each contact. I might have a dozen sets of “interaction type + date + location” values that must be presented together in order to make sense. Here you can see that I once again use an enumeration to print out each date/type/location that are related.

The result? I constructed a single “dashboard” that shows me the results of each feed as a different widget on the page. For a sales rep about to visit a physician, this is a great way for them to get a holistic customer view made up of attributes from every system that knows anything about that customer. This even includes a public web (Google) query and a feed from their personal, professional, or organization’s blog. No need for our user to log into 6 different systems to get data, rather, I present my own little virtual data store.

Conclusion
In these four blog posts, I explained a common data visibility problem, and showed how RSSBus is one creative tool you can use to solve it. I suspect that no organization has all their data in an RSS-ready format, so applications like RSSBus are a great example of adapter technology that makes data extraction and integration seamless. Mashups are a powerful way to get a single real-time look at information that spans applications/systems/organizations and they enable users to make more informed decisions, faster.
Technorati Tags: RSSBus, Mashup