[Series Overview: Part I / Part II / Part III]
If your organization uses MOSS 2007, hopefully you’ve taken a look at what the folks at Nintex have to offer. My company recently deployed their workflow solution, and I thought I’d take a look at how to execute system integration scenarios as part of a Nintex Workflow.
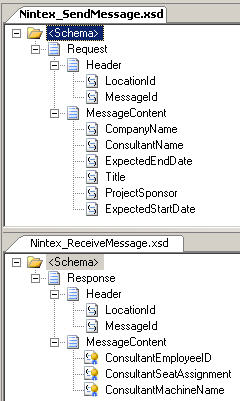
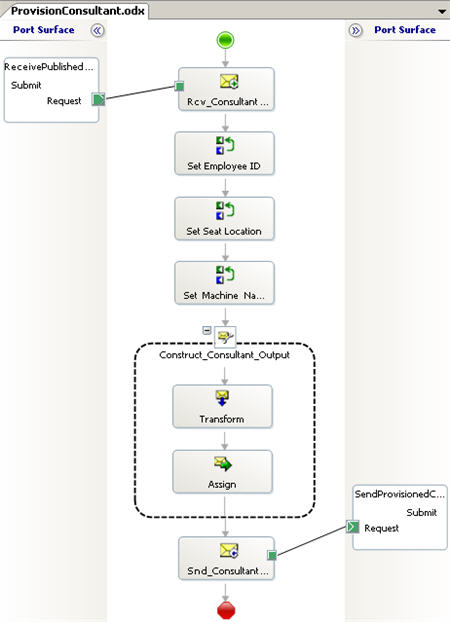
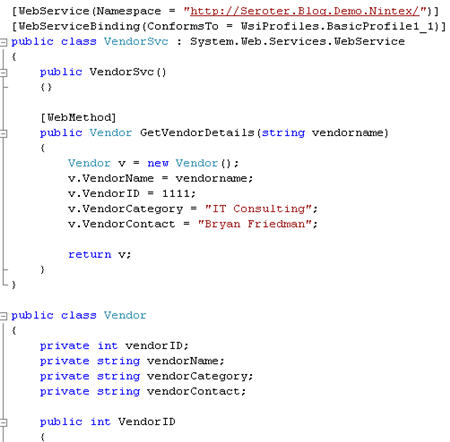
In this first post, I’ll take a short look at the general product toolset. The second post will show off web services integration, and the final post will highlight their native BizTalk Server integration.
First off, what is Nintex Workflow? It’s a solution hosted within the SharePoint environment that allows you to graphically construct robust workflow solutions that play off of SharePoint lists and libraries. While you can build workflows in SharePoint using either WF or SharePoint Designer, the former is purely a developer task and the latter really exposes a linear, wizard driven design model. Where Nintex fits in is right in the middle: you get the business-friendly user experience alongside a rich set of workflow activities (including any custom ones you build in WF).
Design Experience
Once the Nintex module is installed and enabled in your SharePoint farm, then any list or library has a set of new options in the “Settings” menu.

If I choose to create a new workflow, then I am given the option to select a pre-defined template which has a default flow laid out for me.
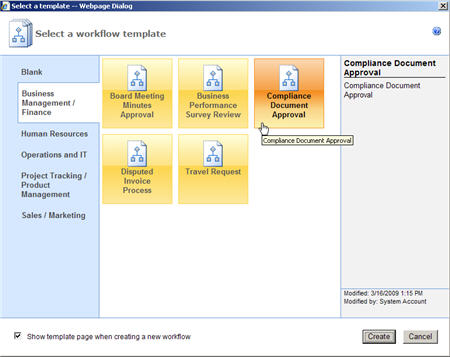
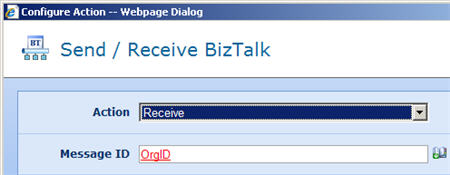
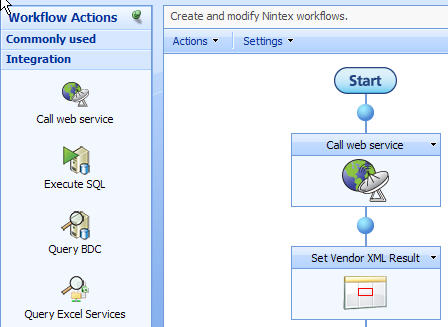
Once a template or blank workflow is chosen, I have a plethora of “Workflow Actions” available to sketch out my process. For example, the Integration category has options such as “Call web service”, “Execute SQL”, “Query LDAP”, “Send/Receive BizTalk” and “Call Workflow.”

There are nine categories of workflow activities in all, including:
- Integration
- Libraries and lists (e.g. “Check out item”, “Create list”, “Set field value”)
- Logic and flow (e.g. “For each”, “Run parallel action”, “State machine”)
- Operations (e.g. “Build dynamic string”, “Wait for an item to update”)
- Provisioning (e.g. “Add User to AD Group”, “Provision user on Exchange”)
- Publishing (e.g. “Copy to SharePoint”)
- SharePoint Profiles (e.g. “Query user profile”)
- Sites and Workspaces (e.g. “Create a site”)
- User Interactions (e.g. “Request approval”, “Send a notification”, “Task reminder”)
Note that you can turn off any individual action you wish if the capability exposed is too risky for your particular organization.
Using these activity shapes, I can draw out a simple process made up of decisions, notifications and approvals.

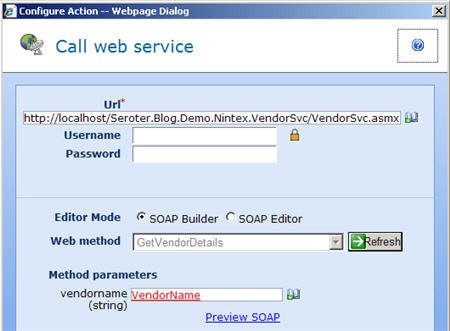
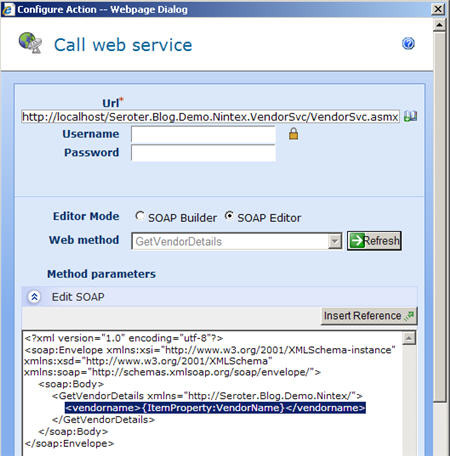
Each activity can be configured (and re-labeled for later readability) per its function. When an activity requires data to act upon (as most do), those values can often either be retrieved from (a) a hard coded value, (b) a workflow-specific variable, or (c) content from any list on the site. For the “Request approval” activity, I have all sorts of options for choosing where to get the approver list from, which means of approval to require (all, single, first, vote) and where to store the assigned tasks. What’s also cool is the “Lazy Approval” setting in Nintex which allows you to respond to a notification email with a single word or phrase to indicate your response. In the image below, notice that I used a value from the list (in red text) as part of my task name.

The configuration experience is pretty similar for each activity. For the most part, I’ve found it to be fairly intuitive although I’ll admit to actually having to open the Help file a few times.
Runtime Experience
You can choose what the start up option should be for the workflow.
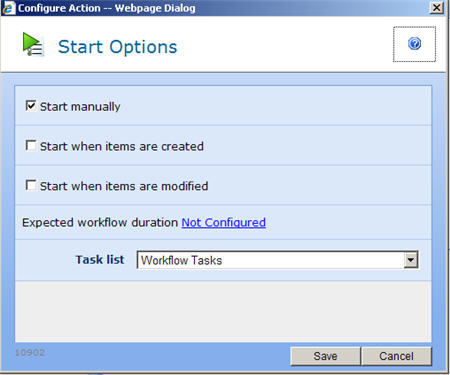
Then, from the “Actions” menu, you can publish the workflow and make it available for use. Pretty darn easy.

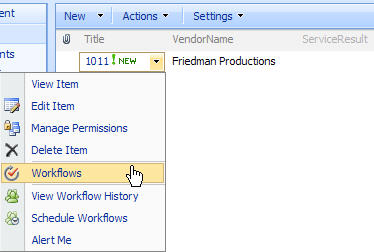
Then, when you add/change data in the list or library, the workflow is either automatically or manually triggered. Just like with any SharePoint workflow, you have a column added to the list which keeps you up to date on the status of the workflow (which you can drill into). Whatever task list is associated with the workflow is also populated with tasks assigned to individual users or groups.

Users can also add the “My Workflow Tasks” web part to a page which will show only the tasks for the active user.
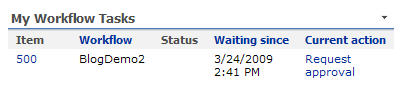
Users can also browse into the running workflow and graphically see what’s been completed so far, how long each step took, and what comes next.

Analysis Experience
Just like the previous image, we can drill into a completed workflow and analyze how it ran and the duration of a given step.

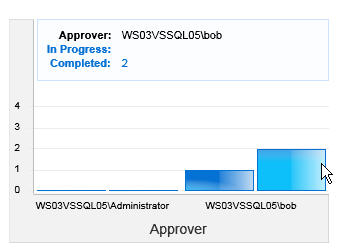
As for reporting, the product comes with plenty of canned reports on a per-site or all-site basis that address topics such as: Approver Performance Statistics, Workflows in Progress, Workflow Performance and much more.

You can display these reports either graphically or tabularly as a web part. For the graphical reports, you can choose line, bar or pie chart. The charts actually rely on Microsoft Silverlight (for the 2-D representation) and are pretty snazzy and configurable.
Summary
This was a very simple, but hopefully adequate, walkthrough to show you around the software. This technology has lots to offer and integrates nicely with the Microsoft stack of products (including Live Communication Server). Note that nothing I did here required a lick of programming or even a particularly technology-centric background. And because the design surface is hosted within the SharePoint environment itself, you get a very rapid, accessible means for building and deploying functional workflows.
If you have a SharePoint sandbox, consider downloading the free trial and playing around.
In the next post, I’ll show you how to do some simple system integration via web service calls from a workflow.
Technorati Tags: SharePoint, BizTalk