When you think about “events” in an event-driven architecture, what comes to mind? Maybe you think of business-oriented events like “file uploaded”, “employee hired”, “invoice sent”, “fraud detected”, or “batch job completed.” You might emit (or consume) these types of events in your application to develop more responsive systems.
What I find even more interesting right now are the events generated by the systems beneath our applications. Imagine what your architects, security pros, and sys admins could do if they could react to databases being provisioned, users getting deleted, firewall being changed, or DNS zone getting updated. This sort of thing is what truly enables the “trust, but verify” approach for empowered software teams. Let those teams run free, but “listen” to things that might be out of compliance.
This week, the Google Cloud team announced Events for Cloud Run, in beta this September. What this capability does is let you trigger serverless containers when lifecycle events happen in most any Google Cloud service. These lifecycle events are in the CloudEvents format, and distributed (behind the scenes) to Cloud Run via Google Cloud PubSub. For reference, this capability bears some resemblance to AWS EventBridge and Azure Event Grid. In this post, I’ll give you a look at Events for Cloud Run, and show you how simple it is to use.
Code and deploy the Cloud Run service
Developers deploy containers to Cloud Run. Let’s not get ahead of ourselves. First, let’s build the app. This app is Seroter-quality, and will just do the basics. I’ll read the incoming event and log it out. This is a simple ASP.NET Core app, with the source code in GitHub.
I’ve got a single controller that responds to a POST command coming from the eventing system. I take that incoming event, serialize from JSON to a string, and print it out. Events for Cloud Run accepts either custom events, or CloudEvents from GCP services. If I detect a custom event, I decode the payload and print it out. Otherwise, I just log the whole CloudEvent.
namespace core_sample_api.Controllers
{
[ApiController]
[Route("")]
public class Eventsontroller : ControllerBase
{
private readonly ILogger<Eventsontroller> _logger;
public Eventsontroller(ILogger<Eventsontroller> logger)
{
_logger = logger;
}
[HttpPost]
public void Post(object receivedEvent)
{
Console.WriteLine("POST endpoint called");
string s = JsonSerializer.Serialize(receivedEvent);
//see if custom event with "message" root property
using(JsonDocument d = JsonDocument.Parse(s)){
JsonElement root = d.RootElement;
if(root.TryGetProperty("message", out JsonElement msg)) {
Console.WriteLine("Custom event detected");
JsonElement rawData = msg.GetProperty("data");
//decode
string data = System.Text.Encoding.UTF8.GetString(Convert.FromBase64String(rawData.GetString()));
Console.WriteLine("Data value is: " + data);
}
}
Console.WriteLine("Data: " + s);
}
}
}
After checking all my source code into GitHub, I was ready to deploy it to Cloud Run. Note that you can use my same repo to continue on this example!
I switched over to the GCP Console, and chose to create a new Cloud Run service. I picked a region and service name. Then I could have chosen either an existing container image, or, continuous deployment from a git repo. I chose the latter. First I picked my GitHub repo to get source from.

Then, instead of requiring a Dockerfile, I picked the new Cloud Buildpacks support. This takes my source code and generates a container for me. Sweet.

After choosing my code source and build process, I kept the default HTTP trigger. After a few moments, I had a running service.
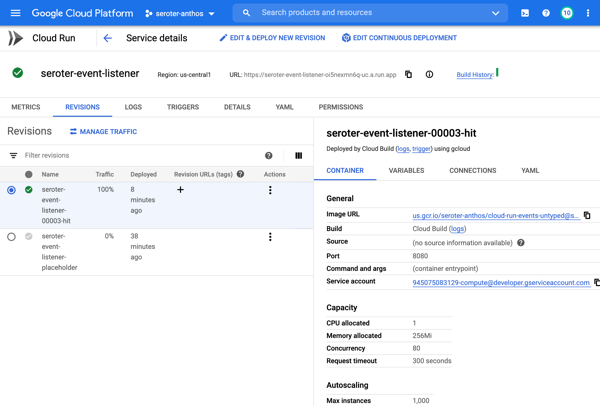
Add triggers to Cloud Run
Next up, adding a trigger. By default, the “triggers” tab shows the single HTTP trigger I set up earlier.
I wanted to show custom events in addition to CloudEvents ones, so I went to the PubSub dashboard and created a new queue that would trigger Cloud Run.
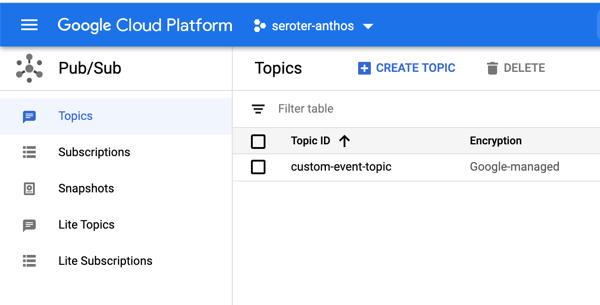
Back in the Cloud Run UX, I added a new trigger. I chose the trigger type of “com.google.cloud.pubsub.topic.publish” and picked the Topic I created earlier. After saving the trigger, I saw it show up in the list.

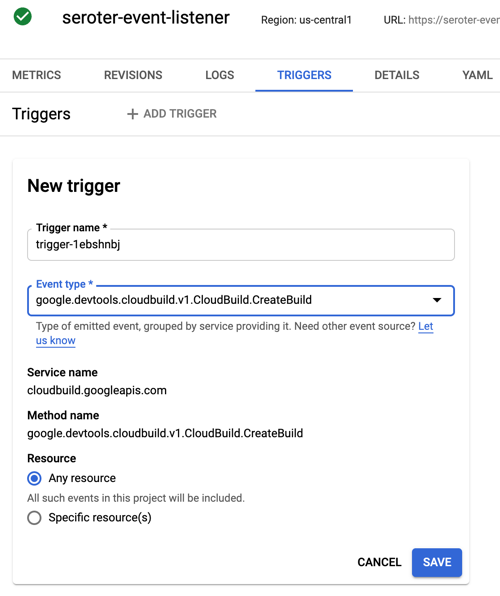
After this, I wanted to trigger my Cloud Run service with CloudEvents. If you’re receiving events from Google Cloud services, you’ll have to enable Data Access Logs so that events can be spun up from Cloud Logs. I’m going to listen for events from Cloud Storage and Cloud Build, so I turned on audit logging for each.

All that was left to define the final triggers. For Cloud Storage, I chose the storage.create.bucket trigger.

I wanted to react to Cloud Build, so that I could see whenever a build started.
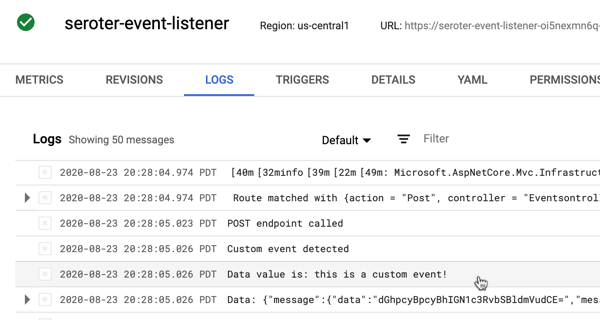
Terrific. Now I was ready to test. I sent in a message to PubSub to trigger the custom event.

I checked the logs for Cloud Run, and almost immediately saw that the service ran, accepted the event, and logged the body.
Next, I tested Cloud Storage by adding a new bucket.

Almost immediately, I saw a CloudEvent in the log.

Finally, I kicked off a new Build pipeline, and saw an event indicating that Cloud Run received a message, and logged it.
If you care about what happens inside the systems your apps depend on, take a look at the new Events for Cloud Run and start tapping into the action.


